
Не существует компаний, в которых не было бы работы с документами. И это — кропотливый, рутинный, но очень важный процесс. Люди хотят получать зарплату вовремя, а поставщики и контрагенты своевременную оплату за свои услуги. Бухгалтеру в компании регулярно приходится проводить серии повторяющихся действий и при этом отслеживать их правильность. Вот простейший пример цепочки таких операций: чтобы отправить счет покупателю, менеджер по продажам отправляет бухгалтеру заявку. Затем бухгалтер создает счет в учетной системе, формирует печатную форму и высылает ее менеджеру. Если с покупателем ведется обмен электронными документами, то бухгалтер создает и отправляет ему счет в системе ЭДО.
Процесс обработки входящих документов состоит из нескольких частей: сканирование, распознавание, классификация, извлечение данных. Обычно, весь процесс происходит с использованием технологий одного вендора, что ограничивает компанию в выборе технологий. При этом недостаточно извлечь данные из документа, необходимо каким-то образом их передать в основные бизнес-приложения (SAP, 1C и др.), это не всегда возможно из-за сложностей интеграции с корпоративными бизнес-приложениями.
Если какие-то задачи выполняются систематически с неизменной четкой логикой, и они присутствуют в большом количестве бизнес-процессов, то их роботизация становится экономически выгодной. UiPath предлагает использовать программных роботов для автоматизации процесса обработки входящих документов. Использование RPA позволяет для каждого типа документов применять разные подходы к распознаванию и извлечению (например, для одного документа использовать шаблоны Abbyy Flexi Capture, а для другого – Microsoft OCR и ML-модели), что делает этот процесс гибким, с точки зрения внедрения.
Сложности распознавания и извлечения данных
Для примера возьмем популярные виды документов: счета и квитанции. На первый взгляд кажется, что работать с ними — простая задача. Но в реальности это не так. Несмотря на то, что подобная автоматизация очень актуальна — ежегодно обрабатываются миллионы счетов, решения, которые умеют это делать, стали лишь недавно выходить на рынок и показывать первые реальные результаты. Трудности такой роботизации определяются двумя ключевыми моментами.
Первая проблема с автоматизацией обработки счетов и квитанций состоит в том, что эти документы являются полуструктурированными. Это значит, что мы наверняка знаем, как расположены логические блоки в таких документах: например, платежная информация всегда находится в шапке счета на оплату, но при этом мы не знаем в каком конкретно месте находится такая информация, как сумма платежа или номер счета.
В начале любого процесса обработки документов используются решения оптического распознавания (OCR), которые трансформируют изображения символов со скана в символы воспринимаемые компьютером. Существуют различные механизмы распознавания: полнотекстовое и зональное распознавание. После того, как документ распознан, нам необходимо извлечь из него нужные данные, ведь движок OCR не знает, где в документе «искать» необходимую информацию.
Для примера рассмотрим извлечение такой простой информации, как банк получателя. Мы однозначно знаем, что название банка будет находиться в верхней части счета. Однако точное расположение нам неизвестно: в одном из примеров ниже он находится в верхней строке над ключевыми словами “Банк получателя”, а в другом - в нижней строчке под ключевыми словами. У каждого контрагента будет свой счет с разным расположением данных на нем.

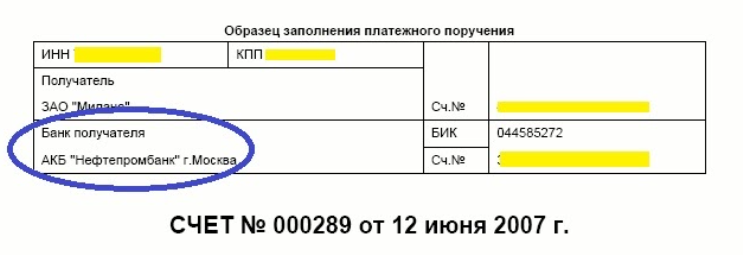
Это приводит к тому, что компании, пытаясь решить эту проблему, создают большое количество шаблонов, предназначенных для каждого бланка счета. Эти макеты помогают указать OCR правильное место на странице, чтобы оно могло найти и извлечь соответствующую информацию. Этот метод работает, но когда макетов становится много, он теряет свою эффективность. И для каждого нового поставщика нам приходится настраивать новый шаблон.
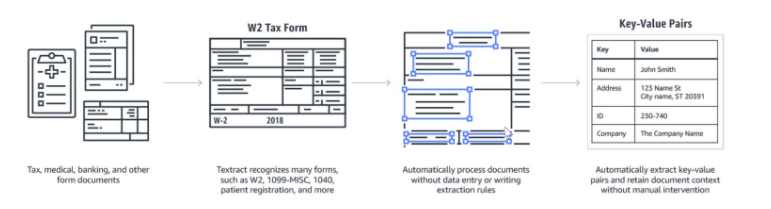
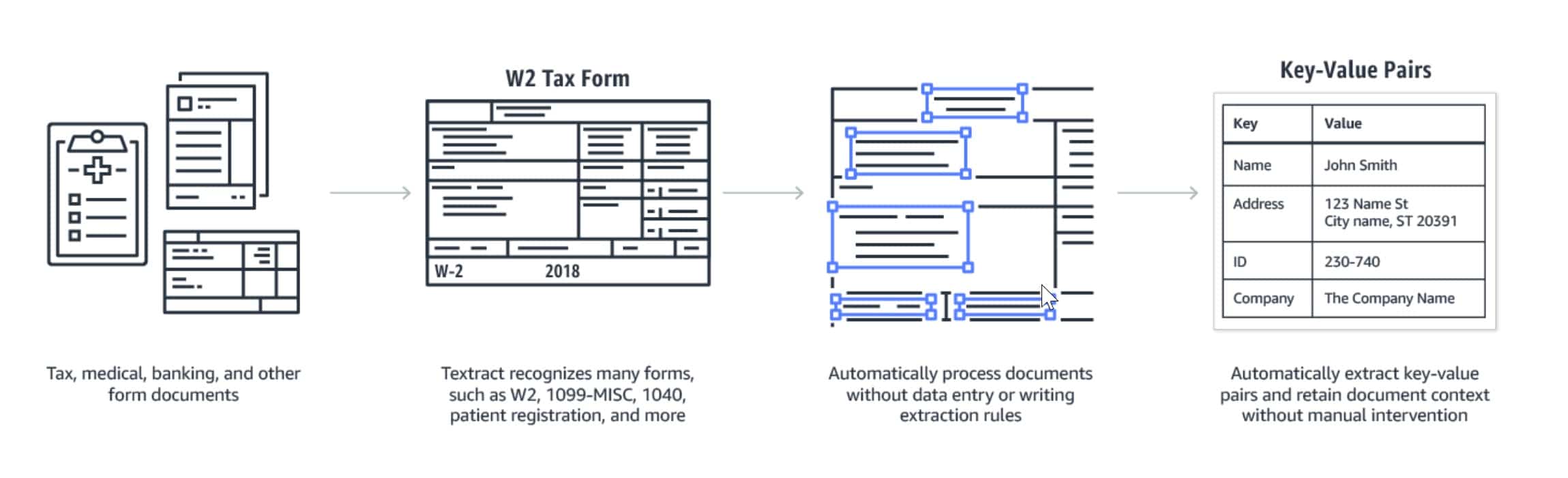
Примеры извлечения данных из шаблонов. Источник: https://research.aimultiple.com/wp-content/uploads/2019/03/key-value-pairs.jpg
Вторая проблема заключается в устранении ошибок, встречающихся в реальных документах, которые редко бывают идеально напечатанными и хорошо отсканированными.
Документы, с которыми сталкивается робот, часто содержат много ошибок, затрудняющих их чтение. Счет может быть отсканирован на некачественном офисном сканере. Картинка может быть перекошена или отсканирована вместе с другими ненужными документами. Все эти факторы могут запутывать роботов и систему OCR, затрудняя поиск необходимой информации.
Как роботы извлекают данные?
Есть несколько подходов к извлечению данных. Одним из перспективных направлений мы считаем использование моделей машинного обучения. У UiPath есть модели для счетов и чеков, они помогают автоматически определять местоположение информации, которую необходимо извлечь. UiPath может работать и со сторонними моделями. Даже если документ содержит множество ошибок, робот все равно найдет необходимую информацию. Возвращаясь к нашим примерам счетов выше, с использованием машинного обучения робот без проблем сможет найти, в каком конкретно поле содержится информация о банке получателя.
Другие подходы - использование регулярных выражений, создание шаблонов для полуструктурированных и структурированных данных.
Создаем проект по обработке документов в UiPath Studio
1 Запуск менеджера таксономий.
В менеджере таксономий мы создаем классы документов, с которыми мы будем работать.
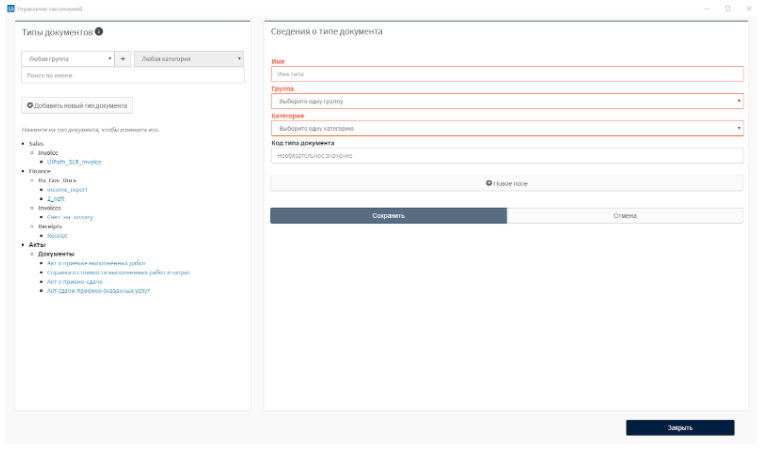
Мы можем выбирать категорию и тип распознаваемого документа:
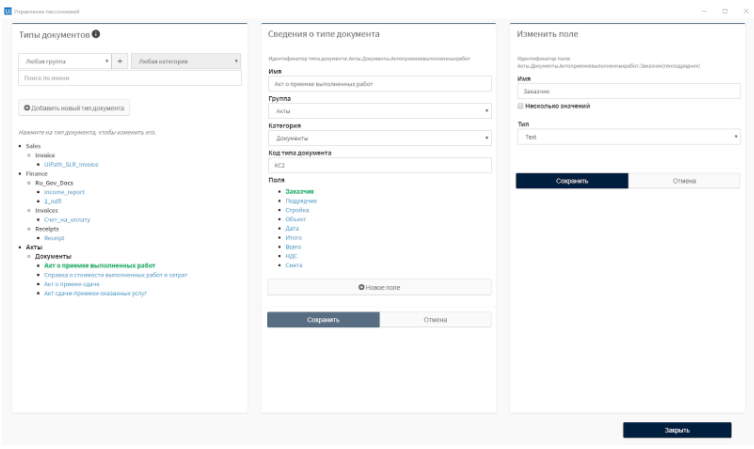
На этом этапе также определяются поля для извлечения в конкретном типе документа. Например, типу документа «акт о приемке выполненных работ» могут соответствовать поля «Итого», «Заказчик», «Дата» и, например, «Смета» в формате таблицы.
2 Оцифровка документа с помощью OCR
В UiPath реализовано полнотекстовое распознавание. Можно настроить мониторинг папки, из которой робот будет переносить документы в OCR-сервис. У UiPath есть встроенные механизмы для работы с распространенными движками, как платными, так и бесплатными (Abbyy, Tesseract OCR, Microsoft OCR и др.). Чтобы выбрать нужный движок, нужно просто перенести его из палитры действий в Digitize Document Scope.
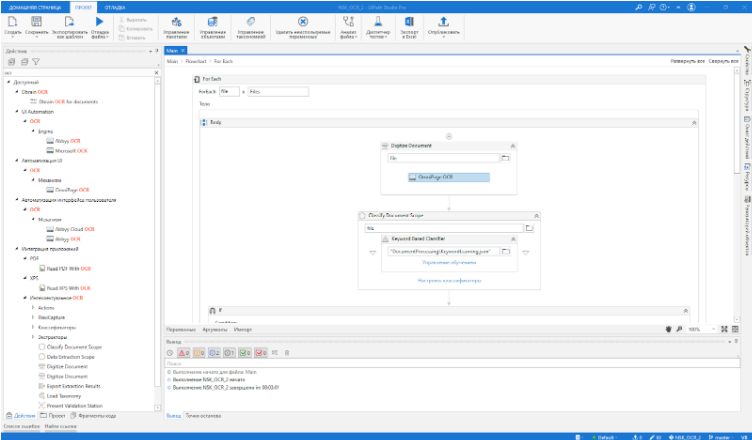
3 Классификация документа по ключевым словам.
После распознавания робот классифицирует документ, чтобы сопоставить его с таксономией и определить какие поля необходимо извлечь. Здесь можно использовать разные подходы от машинного обучения до обычных бизнес правил. Например, если встречается слово ‘invoice’, то скорее всего документ является международным инвойсом, а если “счет-фактура”, то российским счетом-фактурой.
Классификатор UiPath может обучаться на массиве данных.
4 Экстракция данных.
Экстракция — это извлечение текстовых данных из распознаваемого файла.
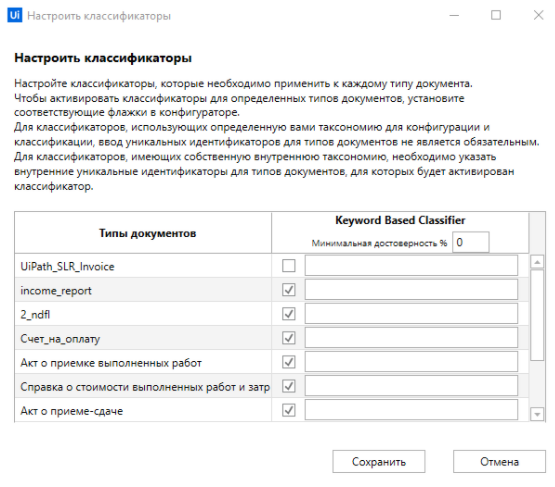
На этом этапе производится выбор экстрактора, который будет извлекать данные. На текущий момент в UiPath есть 4 основных типа экстрактора: формы, ML, Regex, Abbyy Flexi Capture. Переносим их из палитры действий в Data Extraction Scope.
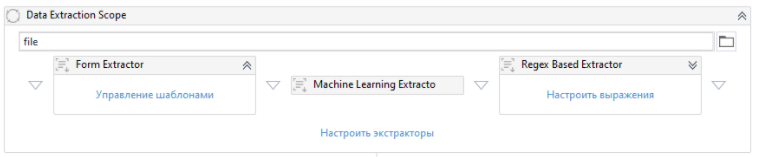
Для каждого экстрактора мы можем задать необходимую степень уверенности. При этом для каждого типа документа мы можем выбрать несколько экстракторов. Если при использовании первого по порядку экстрактора степень уверенности оказывается ниже заданной, то используется следующий экстрактор.
Также мы можем выбрать разные экстракторы для разных полей в документе. Например дату извлекать с помощью ML, а наименование компании через Regex:
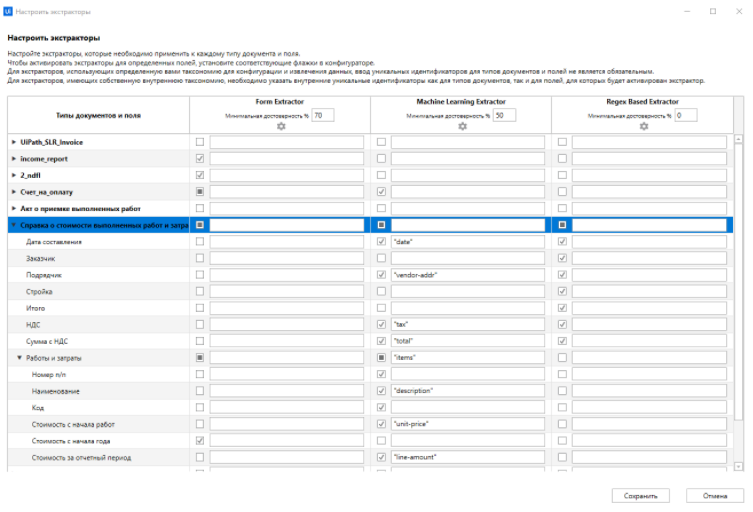
Так настраиватся извлечение нужных данных в UiPath Studio. Источник: https://www.uipath.com/blog/ai-invoice-receipt-processing
А вот как в интерфейсе сервиса выглядит распознанный документ с извлеченными данными:
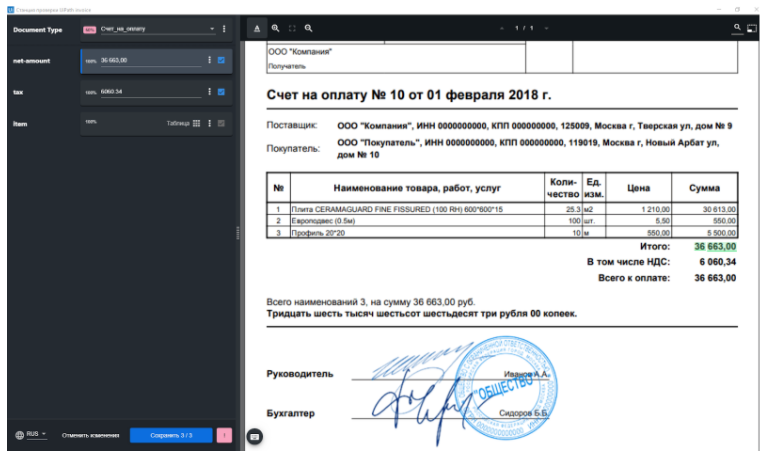
5 Экспорт результатов распознавания.
Первичный экспорт результатов происходит с помощью действия Export Extraction Results в датасет, откуда информация может передаваться в любые сторонние системы, например, SAP, 1C или Госуслуги для бизнеса. При этом нам не нужно реализовывать сложную интеграцию. Робот может ввести данные в абсолютно любую систему через пользовательский интерфейс.
Примеры внедрения RPA для работы с документами
Одно из первых внедрений робота UiPath для работы с документами было проведено в компании «СОК Сервисный Центр РУС», которая оказывает сервисные услуги бухгалтерского сопровождения магазинам финской розничной сети PRISMA и отелям Sokos Hotels в России.
Робот-ассистент UiPath освободил сотрудников сервисной компании от выполнения рутинных операций, связанных с документооборотом. Он обращается к ERP-системе компании, находит, распечатывает и рассылает клиентам по e-mail бухгалтерские документы (счета, счета-фактуры, накладные), в соответствии с требуемыми параметрами и условиями формирования печатных форм. Скорость выполнения операций благодаря использованию робота-ассистента выросла, а количество ошибок уменьшилось. Это позволило ускорить обработку и оплату счетов, и разгрузить сотрудников, высвободив до двух часов их рабочего времени для решения более творческих и интересных задач.
Еще один пример — внедрение бота в компании QIWI, который проверяет бухгалтерские документы на соответствие стандартам финансовой безопасности. Он выполняет запросы к таблицам баз данных из различных систем (в основном ORACLE). Затем компонует полученные результаты и сохраняет их в отдельный файл. После этого бот создает в «1С: Документооборот» документы с файлами отчетов.
В результате удалось освободить людей от рутины, повысить скорость и прозрачность процессов, снизить риски и количество ошибок. Итоговый экономический эффект от роботизации значительно превысил затраты на внедрение RPA.
Выводы и перспективы
Мы рассказали о том, как реализовать процесс ввода и первичной обработки входящих документов без привязки к вендору. С использованием роботов вы можете использовать как классические подходы к извлечению данных, такие как формы или шаблоны, так и недавно появившиеся возможности машинного обучения.
Рассуждая о будущем, мы можем сказать, что появляется все больше моделей машинного обучения, которые позволяют автоматизированно извлекать данные из документа без использования “якорей” и шаблонов. Решения, которые работают с привлечением возможностей машинного обучения в разы эффективнее предыдущих поколений аналогичных сервисов и имеют большой потенциал для повышения уровня автоматизации бизнес-процессов.
По данным Aimultiple.com большинство компаний из списка Fortune 500, использующих технологии, которые разработаны более трех лет назад, имеют уровень автоматизации 10-15%, в то время как решения для извлечения данных счетов на основе машинного обучения могут увеличить этот показатель до 80% и выше.
Компании только начинают осваивать RPA для автоматизации работы с документами, и многие совершают общую стратегическую ошибку в этой области. Поскольку весь процесс управления счетами-фактурами уже является цифровым, они не стремятся его автоматизировать. Однако, бухгалтеры все равно тратят много времени на сверку, перенос и другую работу с цифровыми данными. Получается парадокс — в почти полностью цифровом процессе все равно присутствует много ручного труда. Поэтому автоматизация повторяющихся процессов — становится сегодня точкой роста цифровой трансформации бизнеса, а распознавание и дальнейшая обработка финансовых документов — самой распространенной областью применения RPA.

{kind=link}