В предыдущей статье мы поведали вам о новых фичах в вышедшем в январе обновлении Update 4 для Veeam Backup & Replication 9.5 (VBR), где осознанно не упомянули бэкапы на магнитную ленту. Рассказ об этой области заслуживает отдельной статьи, потому что новых фич было действительно много.
– Ребята из QA, напишете статью?
– Почему бы и нет!

Хранение данных на магнитных лентах (кассетах, «тейпах», как мы в R&D их называем) не ограничивается ушедшим в прошлое компьютером ZX-Spectrum, одна игра для которого могла грузиться в оперативную память 48 kb с магнитофонной кассеты по несколько минут. За четверть века скорости и ёмкости кассет возросли на 6-7 порядков. Это не совсем корректное сравнение, и за законом Мура стандарт LTO не поспевает. Тем не менее, современные технологии позволяют записать на километровую ленту одной кассеты 12 терабайт данных (до 30 терабайт в режиме компрессии), таким образом, 160-долларовый накопитель оставляет конкурентов позади по стоимости долговременного хранения большого объёма данных даже с учётом вложений в оборудование для записи/чтения. Данные на таких кассетах надёжно хранятся 15-30 лет.
Зайду с другой стороны. В последнее время вирусы-вымогатели вышли на новый уровень. Они могут ждать своего часа в инфраструктуре крупной компании неделями и месяцами, а с появлением очередной уязвимости нулевого дня – уничтожить (не без помощи человека, ведь на кону большие деньги) не только все данные, но и все резервные копии, до которых только можно добраться. Вот свежий пример, когда компании пришлось заплатить вымогателям. Так называемые air gap, т. е. физически изолированные от инфраструктуры бэкапы стали, по сути, единственным надёжным спасением от таких историй. Магнитная лента тут – одно из неустаревающих решений.

Но одной спецификации и технологических железных и барий-ферритовых новинок от ведущих производителей (IBM, HPE, Oracle, Dell) для надёжной защиты данных недостаточно, нужен хороший софт. У нас в Veeam целая команда занимается ленточными бэкапами, около 10 человек ежедневно анализируют, планируют, исследуют, разрабатывают и тестируют. Результаты этой работы вы могли видеть в предыдущих статьях (раз, два). Что же было сделано за последний год?
Встаёт выбор между вольностями по отношению к родному языку и усложняющими читаемость канцеляризмами. Я предпочитаю первое, поэтому заранее прошу прощения, если кому-то жаргонные словечки из списка ниже будут резать глаз. Здесь же вкратце напомню, что означает тот или иной термин.
Сразу козыри на стол. Самая масштабная фича нашего апдейта, предназначенная для облачных провайдеров, использующих в своей инфраструктуре VBR. Разработка была начата ещё два года назад. Вскоре мы поняли, что справиться с такой серьёзной задачей к ближайшему релизу не успеем, взяли небольшую паузу, и в итоге выпустили фичу в 9.5 Update 4.
Если коротко, теперь у провайдеров появилась возможность копировать бэкапы своих клиентов на кассеты с помощью тейп-джобы в GFS-пул. Это даёт провайдерам – а это очень крупные дорогие нашему сердцу и коммерческому отделу ребята – две возможности:
С точки зрения маркетинга функциональность очень «вкусная», с нашей же – не менее сложная в реализации.
Основная возникшая проблема – шифрование данных. Большинство облачных бэкапов зашифрованы, статистика говорит о ⅔ от общего количества. Для нас эта цифра была сюрпризом, предполагали, что криптуется почти всё, но нет – многие клиенты, похоже, безоговорочно уверены в своих провайдерах.
Парадигма простая: провайдер не должен уметь расшифровать данные своих тенантов. При этом в рамках новой фичи требуется на стороне провайдера открывать стораджи с бэкапами. Нужно это для того, чтобы перекладывать блоки данных, например, для создания виртуальной полной резервной копии. Главное, делать это нужно независимо от тенанта, когда необходимые ключи не передаются на сторону провайдера во время выполнения джобы.
Решение этой проблемы, задействованное, кстати, и в другой важнейшей фиче вышедшего дополнения – Capacity Tier – состоит в добавлении дополнительного ключа шифрования. Архивный ключ (Archive key) хранится в базе провайдера в зашифрованном виде. По хитрой схеме на стороне провайдера с его помощью можно открывать сторадж, перемещать и перешифровывать блоки данных между стораджами (ведь у каждого – свой ключ), но нельзя расшифровать сами данные.

Хитрая схема (рабочий вариант)
Добавлю, что все инженеры в R&D очень любят шифрование в нашем продукте, правда, никто не знает во всех деталях, как оно работает. (Тут была ещё шутка «и почему вообще работает», но её не пропустили редакторы.)
На фичу были записаны сотни багов. Наиболее сложные области – шифрование, пользовательский интерфейс, проблемы при ресторе.
С точки зрения тестирования трудность представляла большая вариативность, «комбинаторика» видов и типов тенантских джоб и репозиториев – имею в виду как сорс, так и таргет при восстановлении бэкапов в инфраструктуру. Всё это нанизывается на логику в рамках модели GFS (в том числе новую – параллелизм и ежедневные медиа-сеты, об этом ниже), да и в целом на непривычную для тейпов облачную специфику. Не забудьте обильно приправить шифрованием. Если продолжать метафору, мы хорошенько объелись этим блюдом – но и распробовали со всех сторон.
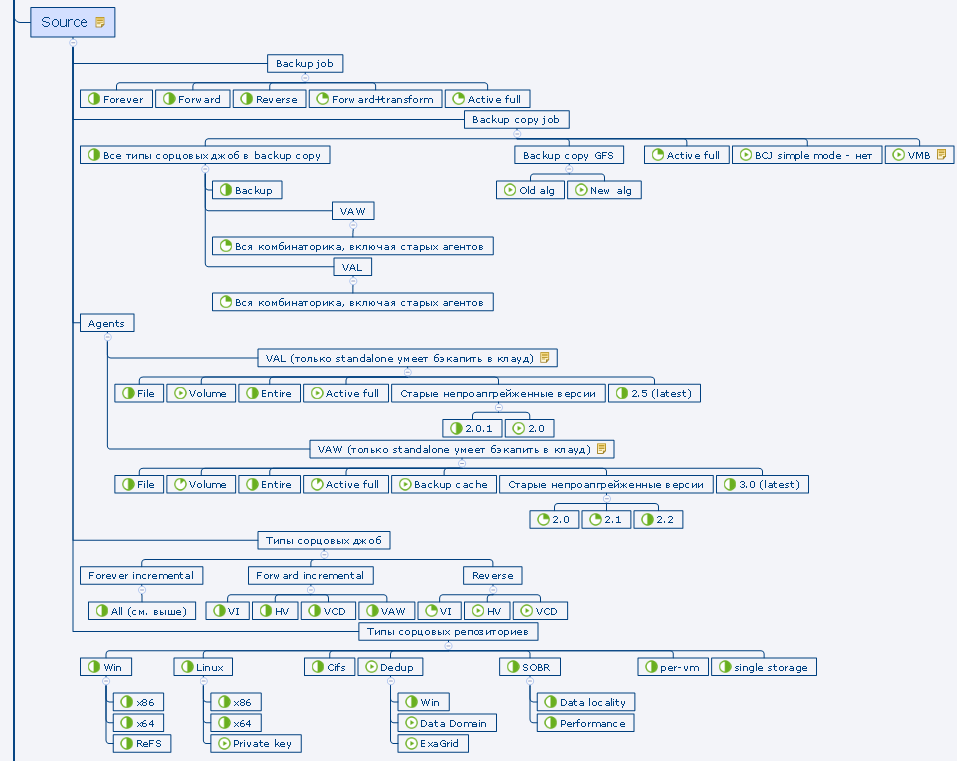
Фрагмент тест-плана
Подробное описание можно найти в руководстве пользователя (пока что на англ.языке): бэкап, восстановление. Остановлюсь на основных моментах.
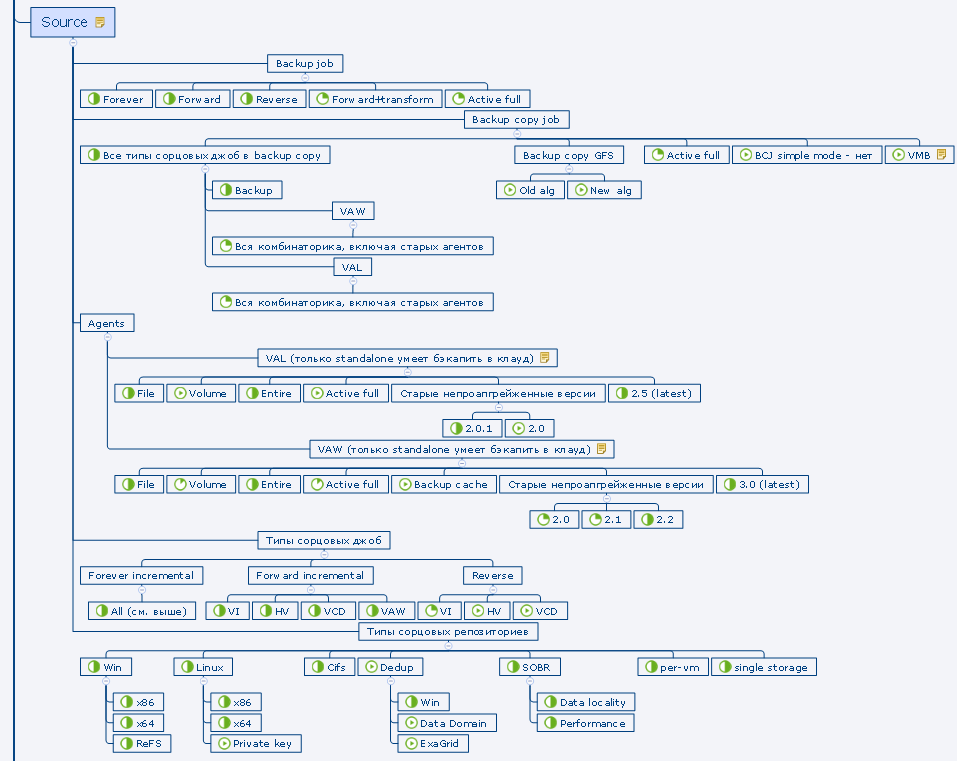
Провайдер добавляет тенантов в тейп-джобу с GFS-пулом в качестве таргета. При наличии облачной лицензии на втором шаге визарда доступна опция Tenants. Можно добавить всех тенантов сразу или по отдельности, а можно выбрать и лишь отдельную квоту (но не сабквоту) отдельного тенанта. Смешивать в одной джобе тенантские бэкапы и обычные локальные нельзя.
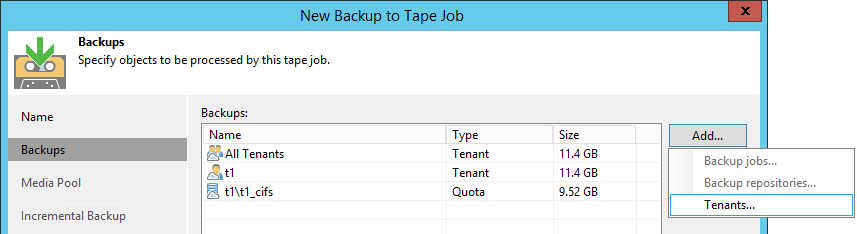
Остальные настойки почти полностью идентичны обычной джобе в GFS-пул.
Рестор данных возможен как на стороне провайдера, так и на стороне самого тенанта.
Выполняется через новый визард. Тут уже можно спуститься до отдельной джобы, восстанавливается целиком цепочка, находившаяся в репозитории в определённый день.
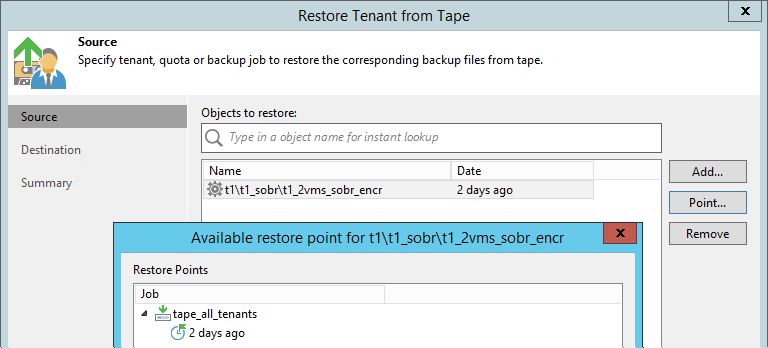
Есть три варианта рестора:

Эта опция подразумевает наличие у клиента собственной тейп-инфраструктуры и большого объёма данных для рестора. Кассету с записанными бэкапами провайдер может физически отправить клиенту службой доставки, тот каталогизирует её на своём оборудовании, расшифровывает кассеты и бэкапы и работает с резервными копиями так, как будто бы он сам их и записал на ленту. Вот такой лайфхак, чтобы не качать терабайты по WAN.
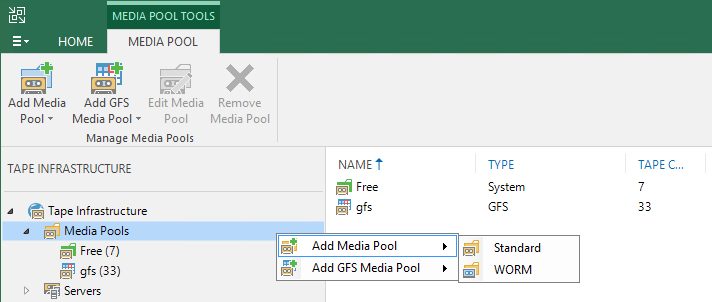
GFS-медиа-пулы появились в VBR два года назад, в версии 9.5. В вышедшем обновлении, как в связи с появлением фичи Tenant to tape, так и по просьбам пользователей, мы хорошо прокачали эту функциональность.
Появился новый ежедневный (daily) медиа-сет. Теперь в GFS-пуле можно хранить бэкапы за каждый день, и не только полные, но и инкрементальные. Последние занимают существенно меньше места, и сделано это в целях экономии ленты. Подразумевается, что эти кассеты постоянно ротируются в библиотеке, не отвозятся на удалённое хранение. При этом для рестора из инкрементальной точки нужны будут кассеты одного из старших медиа-сетов (недельного, месячного, квартального или годового). Включить ежедневный медиа-сет без включения недельного нельзя для того, чтобы в большинстве случаев для восстановления из инкрементальной копии требовались именно недельные кассеты. Они либо тоже всегда находятся в библиотеке, либо хранятся на не столь удалённом складе.
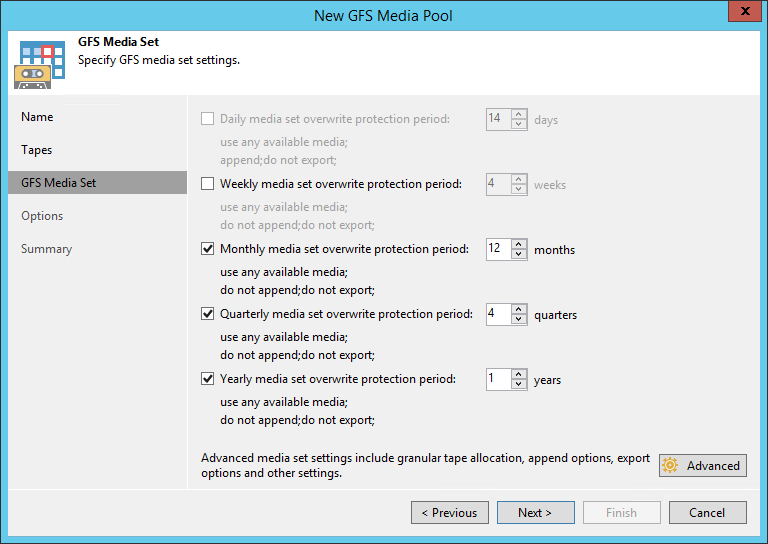
Логика работы тейп-джобы в GFS-медиа-пул не самая простая, технические писатели не дадут соврать. Если в двух словах, опуская детали, то в недельный и старшие медиа-сеты копируются только полные бэкапы (в том числе виртуальные полные бэкапы), по одному за каждую дату, а в ежедневный – все находящиеся в репозитории бэкапы за текущий день, ведь бэкап-джоба может запускаться чаще, чем раз в сутки.
Теперь параллельная запись нескольких цепочек или джоб на нескольких драйвах библиотеки возможна и в GFS-медиа-пулах (раньше – только в обычных). Включается на шаге Options медиа-пула.

Важное уточнение: один и тот же файл всегда пишется в один поток, поэтому в случае нескольких больших виртуальных машин рекомендуется включать настройку per-VM на репозитории, чтобы бэкап состоял из нескольких цепочек.
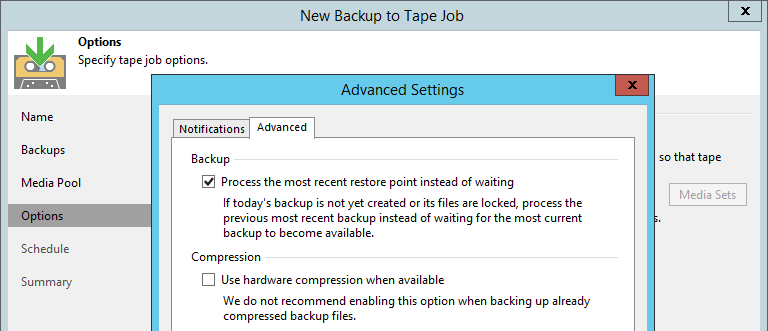
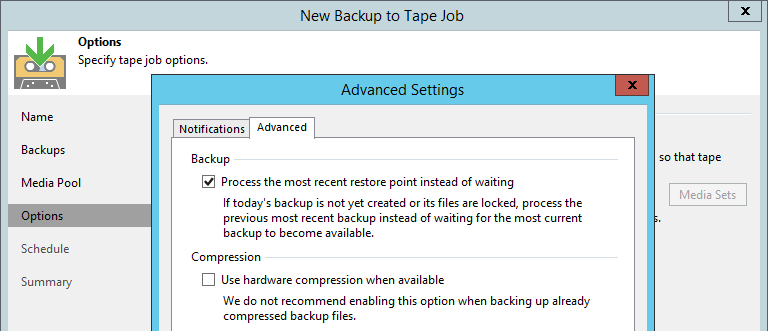
Помимо этого стало возможным выбирать время старта самой GFS-джобы. Многим пользователям не нравился запуск в полночь и последующее ожидание в течение почти целого дня, пока сорс-джоба не завершится. Теперь это время можно, например, выставить на поздний вечер, когда уже есть что копировать на ленту. Более того, по запросам пользователей мы вынесли в расширенные настройки опцию, которую раньше можно было активировать только с помощью реестрового ключа. Достаточно выбрать Process the most recent restore point instead of waiting – и на кассету копируется то, что есть в репозитории на момент старта тейп-джобы (точка за вчерашний день, например), ожидания нет вообще.
Речь пойдёт о ситуации, когда в один медиа-пул добавлено больше одной библиотеки. Поддерживали мы такое и раньше, но время от времени приходили клиенты с жалобами о не совсем предсказуемом поведении.

К примеру, стартовала тейп-джоба, заняла два драйва в первой библиотеке, но настройки параллелизма позволяют ей использовать сразу 4 драйва. Должна ли эта джоба переключаться на вторую библиотеку медиа-пула и использовать её тоже, или это будет перерасходом ресурсов?
Другой случай. Выбрана опция переключаться по условию «нет доступных кассет», в первой библиотеке только одна кассета, но на неё потенциально помещаются все данные. Однако настройки позволяют писать параллельно на две кассеты. Задействовать ли вторую библиотеку в этом случае?
Мы решили привести эту область в порядок, дав возможность настроить поведение явным образом.

У библиотек в медиа-пуле появились роли – активная и пассивная. А у самого медиа-пула – два режима: отказоустойчивый, или фейловер (failover) и параллельная запись (paralleling). Теперь, в зависимости от требований, можно настроить медиа-пул по-разному.
Есть более сложная ситуация, которую мы пока не поддерживаем – несколько активных библиотек при наличии пассивных. Обратная связь покажет, есть ли потребность в таких конфигурациях и надо ли «допиливать» фичу в будущем. Стандартная практика.
WORM – Write Once Read Many – кассеты, которые нельзя стереть или перезаписать на уровне железа, можно только дописывать данные. Их обязательное использование регламентируется правилами некоторых организаций, например, работающих в области медицины. Основная проблема с такими кассетами раньше была в том, что VBR при инвентаризации или каталогизации записывал заголовок, который в дальнейшем уже нельзя было стереть, и тейп-джобы падали с ошибкой при такой попытке.
В 9.5 Update 4 реализована полноценная поддержка таких кассет. Добавлены WORM-медиа-пулы, обычный и GFS, куда можно поместить только кассеты этого типа.
У новых кассет синяя, «замороженная» иконка. С точки зрения пользователя работа с WORM-кассетами не отличается от работы с обычными.
«Вормовость» кассет изначально определяются по суффиксу баркода, если же баркод на них обычный или нечитаемый, информацию отдаёт драйв при первой вставке кассеты. Поместить WORM-кассеты в обычный медиа-пул и писать на них не получится. Из забавного: уже нашлись пользователи, наклеивавшие WORM-баркоды на обычные кассеты и удивившиеся изменениям в своей инфраструктуре после обновления.
Попутно с внедрением неперезаписываемых кассет стали работать с чипом. Стандартные атрибуты в чипе раньше нами не использовались, сейчас в некоторые из них пишем и читаем, но не воспринимаем как основной источник данных. Главный ориентир – по-прежнему заголовок кассеты. Это решение оказалось правильным: по прошествии месяца после релиза видим, как «зоопарк» железа пользователей преподносит сюрпризы в плане работы с чипом.
В заключение – о самой востребованной по количеству отзывов фиче этого Update. Стал доступен бэкап NDMP-томов на кассеты. В инфраструктуру VBR необходимо добавить NDMP-сервер, после чего в файловой тейп-джобе станет можно выбрать тома с этого хоста. Они ложатся на кассеты в виде файлов со специальным атрибутом, чтобы отличать их от обычных при каталогизации.
В первой реализации есть определённые ограничения: не поддерживаются расширения (extensions), плюс возможен бэкап и рестор только полного тома, но не отдельных файлов. Бэкап работает через dump (в случае NetApp – ufsdump), тут есть свои особенности: максимальное число инкрементальных точек – 9, после чего форсируется полная резервная копия.
Это были лишь наиболее крупные нововведения в области резервного копирования на магнитную ленту в VBR 9.5 Update 4. Прочие изменения приведу списком:
Для разнообразия приведу несколько ссылок и на русскоязычные ресурсы:
– Ребята из QA, напишете статью?
– Почему бы и нет!

Ленточные накопители в XXI веке
Хранение данных на магнитных лентах (кассетах, «тейпах», как мы в R&D их называем) не ограничивается ушедшим в прошлое компьютером ZX-Spectrum, одна игра для которого могла грузиться в оперативную память 48 kb с магнитофонной кассеты по несколько минут. За четверть века скорости и ёмкости кассет возросли на 6-7 порядков. Это не совсем корректное сравнение, и за законом Мура стандарт LTO не поспевает. Тем не менее, современные технологии позволяют записать на километровую ленту одной кассеты 12 терабайт данных (до 30 терабайт в режиме компрессии), таким образом, 160-долларовый накопитель оставляет конкурентов позади по стоимости долговременного хранения большого объёма данных даже с учётом вложений в оборудование для записи/чтения. Данные на таких кассетах надёжно хранятся 15-30 лет.
Зайду с другой стороны. В последнее время вирусы-вымогатели вышли на новый уровень. Они могут ждать своего часа в инфраструктуре крупной компании неделями и месяцами, а с появлением очередной уязвимости нулевого дня – уничтожить (не без помощи человека, ведь на кону большие деньги) не только все данные, но и все резервные копии, до которых только можно добраться. Вот свежий пример, когда компании пришлось заплатить вымогателям. Так называемые air gap, т. е. физически изолированные от инфраструктуры бэкапы стали, по сути, единственным надёжным спасением от таких историй. Магнитная лента тут – одно из неустаревающих решений.

Но одной спецификации и технологических железных и барий-ферритовых новинок от ведущих производителей (IBM, HPE, Oracle, Dell) для надёжной защиты данных недостаточно, нужен хороший софт. У нас в Veeam целая команда занимается ленточными бэкапами, около 10 человек ежедневно анализируют, планируют, исследуют, разрабатывают и тестируют. Результаты этой работы вы могли видеть в предыдущих статьях (раз, два). Что же было сделано за последний год?
Глоссарий
Встаёт выбор между вольностями по отношению к родному языку и усложняющими читаемость канцеляризмами. Я предпочитаю первое, поэтому заранее прошу прощения, если кому-то жаргонные словечки из списка ниже будут резать глаз. Здесь же вкратце напомню, что означает тот или иной термин.
Корифеям VBR эту часть можно пропустить
Джоба – job – задание резервного копирования. Собственно, весь VBR построен на джобах. Помимо бэкапа и репликации, это может быть и копирование на магнитную ленту (backup to tape job, тейп-джоба). Оговорюсь, что восстановление из резервной копии (рестор) – тоже джоба, но в данной статье под этим словом будет подразумеваться именно бэкап.
Сторадж – storage – исторически сложившееся название. Это файлы в репозитории (repository – хранилище), содержащие в себе резервные копии – полные и инкрементальные. В одном сторадже может быть как одна, так и несколько виртуальных машин.
Цепочка – chain – последовательность связанных друг с другом стораджей. Для восстановления данных из n-ного инкрементального стораджа нужны все предыдущие от (n-1)-го до 1-го и полный сторадж, на который ссылается первый инкрементальный.
Сорс, таргет – source, target. Сорс – исходная сущность, которую обрабатывает джоба. В случае бэкапов/реплик это, как правило, виртуальная машина в гипервизоре. В случае тейп-джоб сорсом является сама бэкап-джоба (ну или файлы в случае file to tape-джобы). Таргет для бэкап-джоб – это репозиторий, где хранятся бэкапы. Для тейп-джоб же это медиа-пул.
Медиа-пул – media pool – пул носителей информации, в нашем случае – кассет. Логический контейнер, создаваемый пользователем и содержащий в себе кассеты одной или нескольких библиотек. Итак, тейп-джоба всегда имеет медиа-пул в качестве таргета, то есть данные пишутся не на какую-то конкретную кассету и не на любую кассету в библиотеке, а на определённый их набор. Медиа-пул имеет настройку времени хранения данных, по истечении которого кассета может быть перезаписана. Пользователь может создавать обычные (standard) и GFS-пулы. Каждый из этих видов теперь может быть ещё WORM и не-WORM, об этом ниже.
Медиа-сет – media set – набор кассет в медиа-пуле, на которые непрерывно пишутся бэкапы/файлы. Для GFS-пулов медиа-сеты имеют привязку также к интервалу (например, годовой – yearly), кассеты ротируются только внутри своего интервала.
Драйв, чейнджер – элементы тейп-библиотеки. Драйв читает и перематывает кассету, чейнджер – это робот, который перемещает кассеты между слотами хранения, слотами выгрузки и драйвом. Есть и стэндэлон-драйвы (standalone – отдельно стоящий), роль чейнджера тут выполняет человек. Для драйва обязателен корректно установленый драйвер производителя на Windows-машине, куда подключена библиотека; с чейнджером же можем работать и без драйверов, по native SCSI.
Сторадж – storage – исторически сложившееся название. Это файлы в репозитории (repository – хранилище), содержащие в себе резервные копии – полные и инкрементальные. В одном сторадже может быть как одна, так и несколько виртуальных машин.
Цепочка – chain – последовательность связанных друг с другом стораджей. Для восстановления данных из n-ного инкрементального стораджа нужны все предыдущие от (n-1)-го до 1-го и полный сторадж, на который ссылается первый инкрементальный.
Сорс, таргет – source, target. Сорс – исходная сущность, которую обрабатывает джоба. В случае бэкапов/реплик это, как правило, виртуальная машина в гипервизоре. В случае тейп-джоб сорсом является сама бэкап-джоба (ну или файлы в случае file to tape-джобы). Таргет для бэкап-джоб – это репозиторий, где хранятся бэкапы. Для тейп-джоб же это медиа-пул.
Медиа-пул – media pool – пул носителей информации, в нашем случае – кассет. Логический контейнер, создаваемый пользователем и содержащий в себе кассеты одной или нескольких библиотек. Итак, тейп-джоба всегда имеет медиа-пул в качестве таргета, то есть данные пишутся не на какую-то конкретную кассету и не на любую кассету в библиотеке, а на определённый их набор. Медиа-пул имеет настройку времени хранения данных, по истечении которого кассета может быть перезаписана. Пользователь может создавать обычные (standard) и GFS-пулы. Каждый из этих видов теперь может быть ещё WORM и не-WORM, об этом ниже.
Медиа-сет – media set – набор кассет в медиа-пуле, на которые непрерывно пишутся бэкапы/файлы. Для GFS-пулов медиа-сеты имеют привязку также к интервалу (например, годовой – yearly), кассеты ротируются только внутри своего интервала.
Драйв, чейнджер – элементы тейп-библиотеки. Драйв читает и перематывает кассету, чейнджер – это робот, который перемещает кассеты между слотами хранения, слотами выгрузки и драйвом. Есть и стэндэлон-драйвы (standalone – отдельно стоящий), роль чейнджера тут выполняет человек. Для драйва обязателен корректно установленый драйвер производителя на Windows-машине, куда подключена библиотека; с чейнджером же можем работать и без драйверов, по native SCSI.
Tenant to tape. Защищён провайдер – защищены клиенты
Сразу козыри на стол. Самая масштабная фича нашего апдейта, предназначенная для облачных провайдеров, использующих в своей инфраструктуре VBR. Разработка была начата ещё два года назад. Вскоре мы поняли, что справиться с такой серьёзной задачей к ближайшему релизу не успеем, взяли небольшую паузу, и в итоге выпустили фичу в 9.5 Update 4.
Если коротко, теперь у провайдеров появилась возможность копировать бэкапы своих клиентов на кассеты с помощью тейп-джобы в GFS-пул. Это даёт провайдерам – а это очень крупные дорогие нашему сердцу и коммерческому отделу ребята – две возможности:
- защитить своих клиентов (тенантов, tenant – арендатор) от потери данных в результате случайного удаления или инфраструктурных проблем («наводнение в серверной»);
- предоставить тенантам дополнительную услугу по восстановлению данных из старой резервной копии, которая уже давно удалена из облачного репозитория согласно политике хранения данных, но на кассетах по-прежнему осталась.
С точки зрения маркетинга функциональность очень «вкусная», с нашей же – не менее сложная в реализации.
Разработка
Основная возникшая проблема – шифрование данных. Большинство облачных бэкапов зашифрованы, статистика говорит о ⅔ от общего количества. Для нас эта цифра была сюрпризом, предполагали, что криптуется почти всё, но нет – многие клиенты, похоже, безоговорочно уверены в своих провайдерах.
Парадигма простая: провайдер не должен уметь расшифровать данные своих тенантов. При этом в рамках новой фичи требуется на стороне провайдера открывать стораджи с бэкапами. Нужно это для того, чтобы перекладывать блоки данных, например, для создания виртуальной полной резервной копии. Главное, делать это нужно независимо от тенанта, когда необходимые ключи не передаются на сторону провайдера во время выполнения джобы.
Решение этой проблемы, задействованное, кстати, и в другой важнейшей фиче вышедшего дополнения – Capacity Tier – состоит в добавлении дополнительного ключа шифрования. Архивный ключ (Archive key) хранится в базе провайдера в зашифрованном виде. По хитрой схеме на стороне провайдера с его помощью можно открывать сторадж, перемещать и перешифровывать блоки данных между стораджами (ведь у каждого – свой ключ), но нельзя расшифровать сами данные.
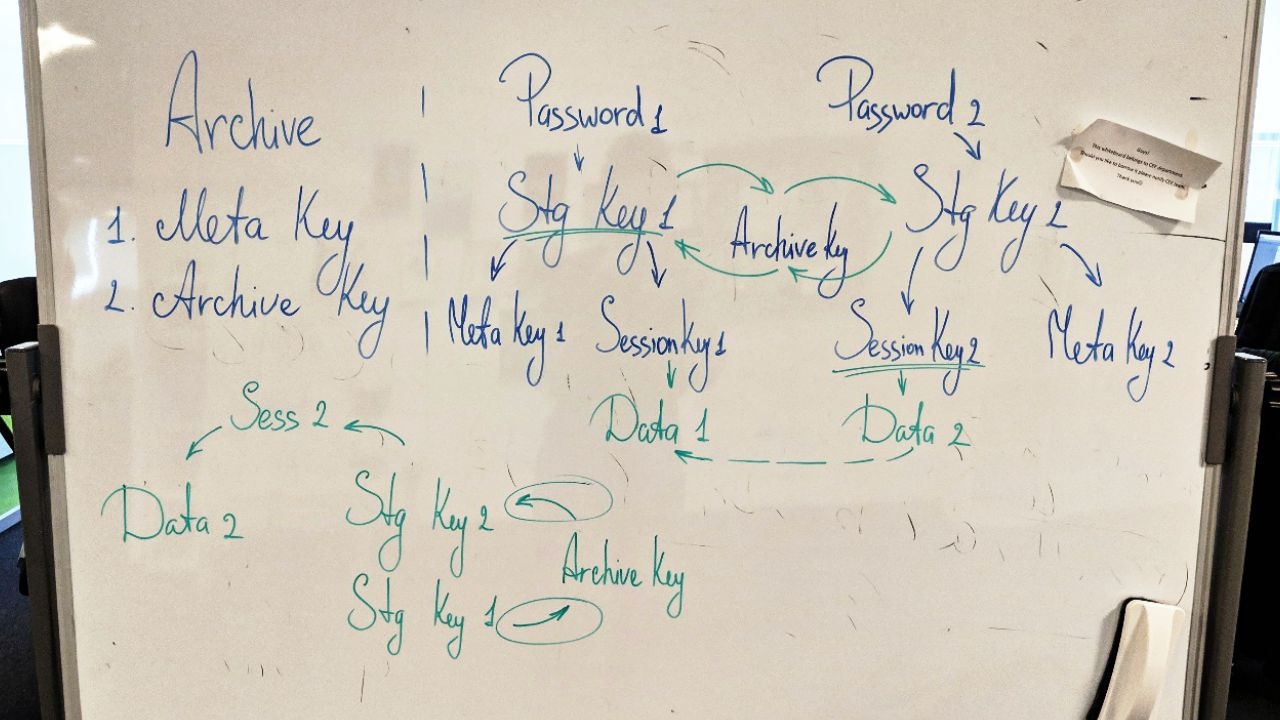
Хитрая схема (рабочий вариант)
Добавлю, что все инженеры в R&D очень любят шифрование в нашем продукте, правда, никто не знает во всех деталях, как оно работает. (Тут была ещё шутка «и почему вообще работает», но её не пропустили редакторы.)
Тестирование
На фичу были записаны сотни багов. Наиболее сложные области – шифрование, пользовательский интерфейс, проблемы при ресторе.
С точки зрения тестирования трудность представляла большая вариативность, «комбинаторика» видов и типов тенантских джоб и репозиториев – имею в виду как сорс, так и таргет при восстановлении бэкапов в инфраструктуру. Всё это нанизывается на логику в рамках модели GFS (в том числе новую – параллелизм и ежедневные медиа-сеты, об этом ниже), да и в целом на непривычную для тейпов облачную специфику. Не забудьте обильно приправить шифрованием. Если продолжать метафору, мы хорошенько объелись этим блюдом – но и распробовали со всех сторон.
Фрагмент тест-плана
В результате
Подробное описание можно найти в руководстве пользователя (пока что на англ.языке): бэкап, восстановление. Остановлюсь на основных моментах.
Бэкап
Провайдер добавляет тенантов в тейп-джобу с GFS-пулом в качестве таргета. При наличии облачной лицензии на втором шаге визарда доступна опция Tenants. Можно добавить всех тенантов сразу или по отдельности, а можно выбрать и лишь отдельную квоту (но не сабквоту) отдельного тенанта. Смешивать в одной джобе тенантские бэкапы и обычные локальные нельзя.

Остальные настойки почти полностью идентичны обычной джобе в GFS-пул.
Рестор данных возможен как на стороне провайдера, так и на стороне самого тенанта.
Восстановление на стороне провайдера
Выполняется через новый визард. Тут уже можно спуститься до отдельной джобы, восстанавливается целиком цепочка, находившаяся в репозитории в определённый день.
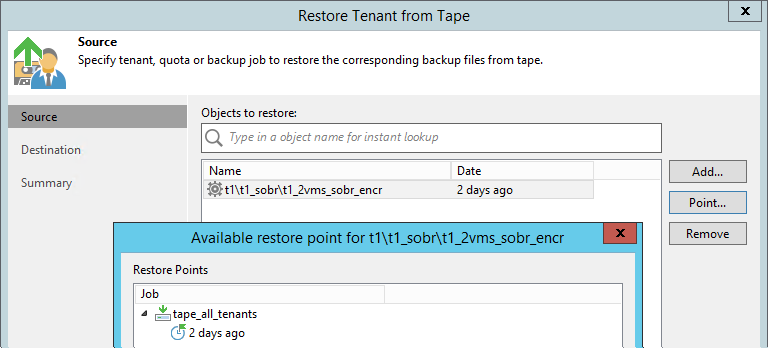
Есть три варианта рестора:
- В исходную локацию. В этом случае оригинальный бэкап, если он есть, удаляется; джобы тенанта автоматически перенастраиваются на восстановленную цепочку. Подразумевается, что такой рестор будет вообще незаметен для клиента, лишь на короткое время он будет отключён от облачного репозитория.
- В новую квоту/репозиторий. Провайдер может, например, создать для этой цели отдельный временный аккаунт, который впоследствии удалит. Бэкап появляется в инфраструктуре тенанта после синхронизации с базой провайдера.
- Просто на диск Linux- или Windows-сервера, зарегистрированного в инфраструктуре провайдера. Дальше эту цепочку можно записать на флэшку и отправить тенанту.

Восстановление на стороне тенанта
Эта опция подразумевает наличие у клиента собственной тейп-инфраструктуры и большого объёма данных для рестора. Кассету с записанными бэкапами провайдер может физически отправить клиенту службой доставки, тот каталогизирует её на своём оборудовании, расшифровывает кассеты и бэкапы и работает с резервными копиями так, как будто бы он сам их и записал на ленту. Вот такой лайфхак, чтобы не качать терабайты по WAN.
Масштабные улучшения GFS-пула
GFS-медиа-пулы появились в VBR два года назад, в версии 9.5. В вышедшем обновлении, как в связи с появлением фичи Tenant to tape, так и по просьбам пользователей, мы хорошо прокачали эту функциональность.
Ежедневные медиа-сеты
Появился новый ежедневный (daily) медиа-сет. Теперь в GFS-пуле можно хранить бэкапы за каждый день, и не только полные, но и инкрементальные. Последние занимают существенно меньше места, и сделано это в целях экономии ленты. Подразумевается, что эти кассеты постоянно ротируются в библиотеке, не отвозятся на удалённое хранение. При этом для рестора из инкрементальной точки нужны будут кассеты одного из старших медиа-сетов (недельного, месячного, квартального или годового). Включить ежедневный медиа-сет без включения недельного нельзя для того, чтобы в большинстве случаев для восстановления из инкрементальной копии требовались именно недельные кассеты. Они либо тоже всегда находятся в библиотеке, либо хранятся на не столь удалённом складе.

Логика работы тейп-джобы в GFS-медиа-пул не самая простая, технические писатели не дадут соврать. Если в двух словах, опуская детали, то в недельный и старшие медиа-сеты копируются только полные бэкапы (в том числе виртуальные полные бэкапы), по одному за каждую дату, а в ежедневный – все находящиеся в репозитории бэкапы за текущий день, ведь бэкап-джоба может запускаться чаще, чем раз в сутки.
Параллелизм, время старта и ожидание в GFS-пулах
Теперь параллельная запись нескольких цепочек или джоб на нескольких драйвах библиотеки возможна и в GFS-медиа-пулах (раньше – только в обычных). Включается на шаге Options медиа-пула.

Важное уточнение: один и тот же файл всегда пишется в один поток, поэтому в случае нескольких больших виртуальных машин рекомендуется включать настройку per-VM на репозитории, чтобы бэкап состоял из нескольких цепочек.
Помимо этого стало возможным выбирать время старта самой GFS-джобы. Многим пользователям не нравился запуск в полночь и последующее ожидание в течение почти целого дня, пока сорс-джоба не завершится. Теперь это время можно, например, выставить на поздний вечер, когда уже есть что копировать на ленту. Более того, по запросам пользователей мы вынесли в расширенные настройки опцию, которую раньше можно было активировать только с помощью реестрового ключа. Достаточно выбрать Process the most recent restore point instead of waiting – и на кассету копируется то, что есть в репозитории на момент старта тейп-джобы (точка за вчерашний день, например), ожидания нет вообще.
Усовершенствованная работа с несколькими библиотеками
Речь пойдёт о ситуации, когда в один медиа-пул добавлено больше одной библиотеки. Поддерживали мы такое и раньше, но время от времени приходили клиенты с жалобами о не совсем предсказуемом поведении.
Было
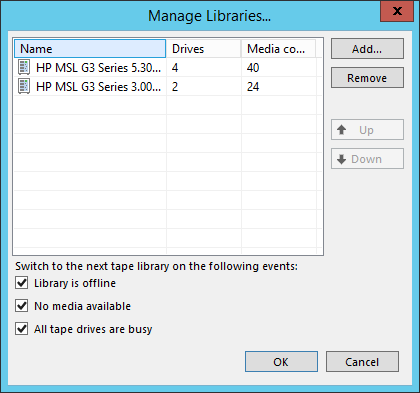
К примеру, стартовала тейп-джоба, заняла два драйва в первой библиотеке, но настройки параллелизма позволяют ей использовать сразу 4 драйва. Должна ли эта джоба переключаться на вторую библиотеку медиа-пула и использовать её тоже, или это будет перерасходом ресурсов?
Другой случай. Выбрана опция переключаться по условию «нет доступных кассет», в первой библиотеке только одна кассета, но на неё потенциально помещаются все данные. Однако настройки позволяют писать параллельно на две кассеты. Задействовать ли вторую библиотеку в этом случае?
Мы решили привести эту область в порядок, дав возможность настроить поведение явным образом.
Стало

У библиотек в медиа-пуле появились роли – активная и пассивная. А у самого медиа-пула – два режима: отказоустойчивый, или фейловер (failover) и параллельная запись (paralleling). Теперь, в зависимости от требований, можно настроить медиа-пул по-разному.
- Если у вас несколько равноправных библиотек и необходмо распараллелить запись в них – включаете режим параллельной записи, для этого всем библиотекам надо назначить активные роли. В этом случае новые кассеты и драйвы будут задействоваться сразу, как только в этом возникнет потребность, вне зависимости от того, в какой библиотеке они находятся. Приоритет всё равно есть – вначале будем пытаться найти ресурсы в библиотеке, расположенной выше по списку.
- Если же имеется одна основная библиотека и одна старенькая или стэндэлон-драйв в резерве, включаете режим фейловера, поставив основную библиотеку наверх списка и выбрав пассивную роль для резервных устройств. Переключение на такое устройство будет происходить только когда это действительно необходимо, чтобы джоба вообще хоть как-то работала. Такая ситуация будет считаться нештатной, о чём будет отправлено уведомление на почту.
Есть более сложная ситуация, которую мы пока не поддерживаем – несколько активных библиотек при наличии пассивных. Обратная связь покажет, есть ли потребность в таких конфигурациях и надо ли «допиливать» фичу в будущем. Стандартная практика.
Поддержка WORM
WORM – Write Once Read Many – кассеты, которые нельзя стереть или перезаписать на уровне железа, можно только дописывать данные. Их обязательное использование регламентируется правилами некоторых организаций, например, работающих в области медицины. Основная проблема с такими кассетами раньше была в том, что VBR при инвентаризации или каталогизации записывал заголовок, который в дальнейшем уже нельзя было стереть, и тейп-джобы падали с ошибкой при такой попытке.
В 9.5 Update 4 реализована полноценная поддержка таких кассет. Добавлены WORM-медиа-пулы, обычный и GFS, куда можно поместить только кассеты этого типа.
У новых кассет синяя, «замороженная» иконка. С точки зрения пользователя работа с WORM-кассетами не отличается от работы с обычными.
«Вормовость» кассет изначально определяются по суффиксу баркода, если же баркод на них обычный или нечитаемый, информацию отдаёт драйв при первой вставке кассеты. Поместить WORM-кассеты в обычный медиа-пул и писать на них не получится. Из забавного: уже нашлись пользователи, наклеивавшие WORM-баркоды на обычные кассеты и удивившиеся изменениям в своей инфраструктуре после обновления.
Чип кассеты
Попутно с внедрением неперезаписываемых кассет стали работать с чипом. Стандартные атрибуты в чипе раньше нами не использовались, сейчас в некоторые из них пишем и читаем, но не воспринимаем как основной источник данных. Главный ориентир – по-прежнему заголовок кассеты. Это решение оказалось правильным: по прошествии месяца после релиза видим, как «зоопарк» железа пользователей преподносит сюрпризы в плане работы с чипом.
Бэкап NDMP-томов на ленту
В заключение – о самой востребованной по количеству отзывов фиче этого Update. Стал доступен бэкап NDMP-томов на кассеты. В инфраструктуру VBR необходимо добавить NDMP-сервер, после чего в файловой тейп-джобе станет можно выбрать тома с этого хоста. Они ложатся на кассеты в виде файлов со специальным атрибутом, чтобы отличать их от обычных при каталогизации.
В первой реализации есть определённые ограничения: не поддерживаются расширения (extensions), плюс возможен бэкап и рестор только полного тома, но не отдельных файлов. Бэкап работает через dump (в случае NetApp – ufsdump), тут есть свои особенности: максимальное число инкрементальных точек – 9, после чего форсируется полная резервная копия.
В качестве заключения
Это были лишь наиболее крупные нововведения в области резервного копирования на магнитную ленту в VBR 9.5 Update 4. Прочие изменения приведу списком:
- возможность задания порядка сорс-джоб и файлов в тейп-джобах;
- добавлена роль Tape Operator (пользователь может делать всё, кроме восстановления с ленты – на это есть Restore Operator);
- добавлены полноценные include/exclude-маски в файловой тейп-джобе (кроме NDMP);
- доработано восстановление в файловой тейп-джобе (папка восстанавливается с теми файлами, которые были там на момент бэкапа, а не со всеми, которые были в ней когда-либо за всю историю её бэкапов – очень востребованная фича, кстати);
- увеличена скорость восстановления очень большого числа файлов с кассет;
- доработан алгоритм выбора очередной кассеты для записи, в частности, при прочих равных учитываем объём записанных/прочитанных за всю её жизнь данных, берём наиболее свежую;
- улучшена стабильность продукта.
Полезные ссылки
Для разнообразия приведу несколько ссылок и на русскоязычные ресурсы:
- Ссылка для скачивания бесплатной пробной версии VBR 9.5 Update 4
- Статья на Хабре «Полезные советы по архивированию бэкапов Veeam на магнитную ленту»
- Статья на Хабре «7 полезных советов по защите резервных копий от вирусов-шифровальщиков»
- Раздел руководства пользователя, относящийся к тейпам (на англ.языке)
- Ну и вернулись на прежнее место обзорные видео «Как это работает» (правда, пока на английском языке) – можно посмотреть здесь. Про тейпы рассказывается на слайдах 95 – 102.
