Capacity Tier (или как мы называем его у себя внутри вима — каптир) появился ещё во времена Veeam Backup and Replication 9.5 Update 4 под именем Archive Tier. Заложенная в него идея — это дать возможность перемещать бекапы, которые выпали из так называемого operational restore window, на объектные хранилища. Это помогало расчищать дисковое пространство тем пользователям, у которых его было мало. А называлась сия опция Move Mode.
Для выполнения этого нехитрого (как кажется) действия достаточно было соблюсти два условия: все точки из перемещаемого бекапа должны быть за границами вышеназванного operational restore window, которое задаётся в явном виде в UI. И второе: цепочка должна быть в так называемом «запечатанном виде»(sealed backup chain или Inactive Backup Chain). То есть с течением времени в этой цепочке не происходит изменений.
Но в VBR v10 концепция дополнилась новыми функциями — появился Copy Mode, Sealed Mode и штука со сложновыговариваемым названием Immutability.
Вот об этих увлекательных вещах мы сегодня и поговорим. Сначала о том, как это работало в VBR9.5u4, а потом об изменениях в десятой версии.

И да простят меня поборники чистого языка, но слишком много терминов невозможно перевести.
Так что здесь будет тьма англицизмов.
И много гифок.
И картинок.
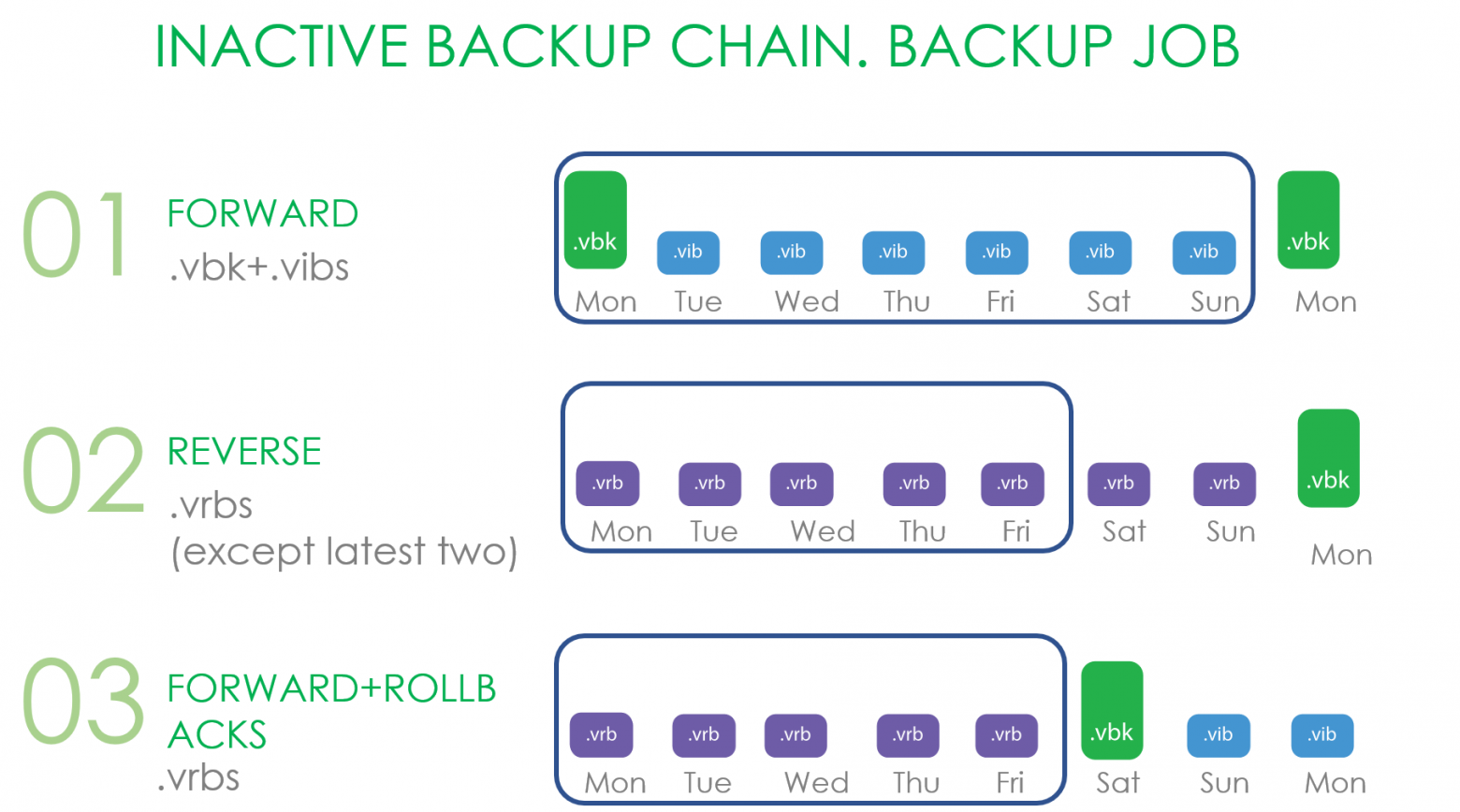
Ну что же, начинаем с разбора operational restore window и sealed backup (или как они называбтся в документации Inactive Backup Chain). Без их понимания дальнейшее объяснить не получится.
Как мы видим на картинке, у нас есть некая бекапная цепочка с блоками данных, которая расположена на Performance tier SOBR репозитория, к которому подключён Capacity Tier. Наше окно операционного бекапа равно трём дням.
Соответственно, созданный в понедельник .vbk запечатывает предыдущую цепочку, окно которой установлено на три дня. И, значит, спокойно можно начинать отвозить в капасити тир всё что старше этих трёх дней.

Но что именно подразумевалось под sealed цепочкой и что могло отправляться в капасити тир в update 4?
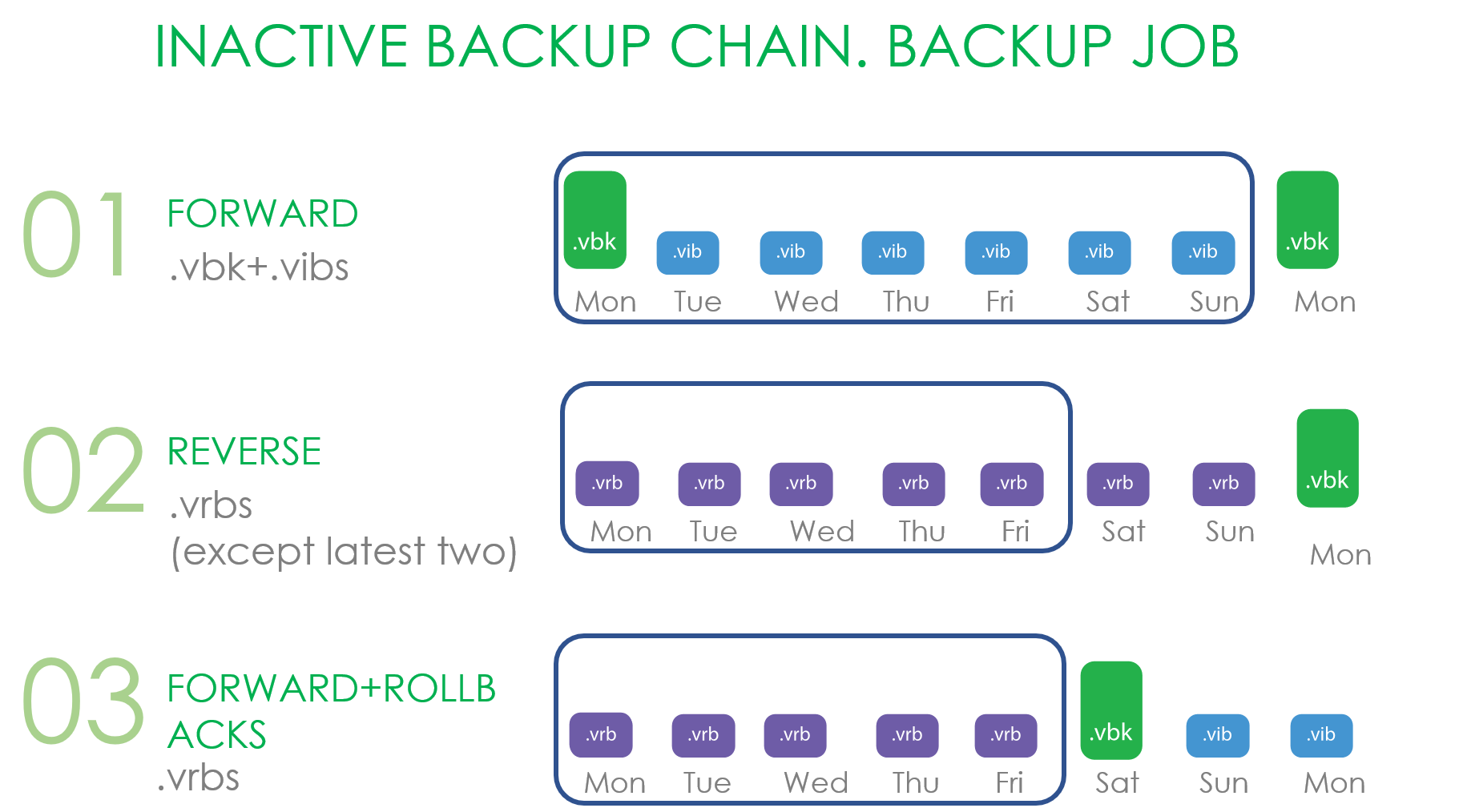
Для Forward Incremental признаком запечатывания цепочки является создание нового фул бекапа. И не важно, как этот фульник получается: считаются и synthetic full, и active full бекапы.
В случае Reverse это все файлы, не попадающие в операционное окно.
В случае Forward increment с роллбеками это все роллбеки и .vbk, если на перфоманс экстенте есть ещё один .vbk
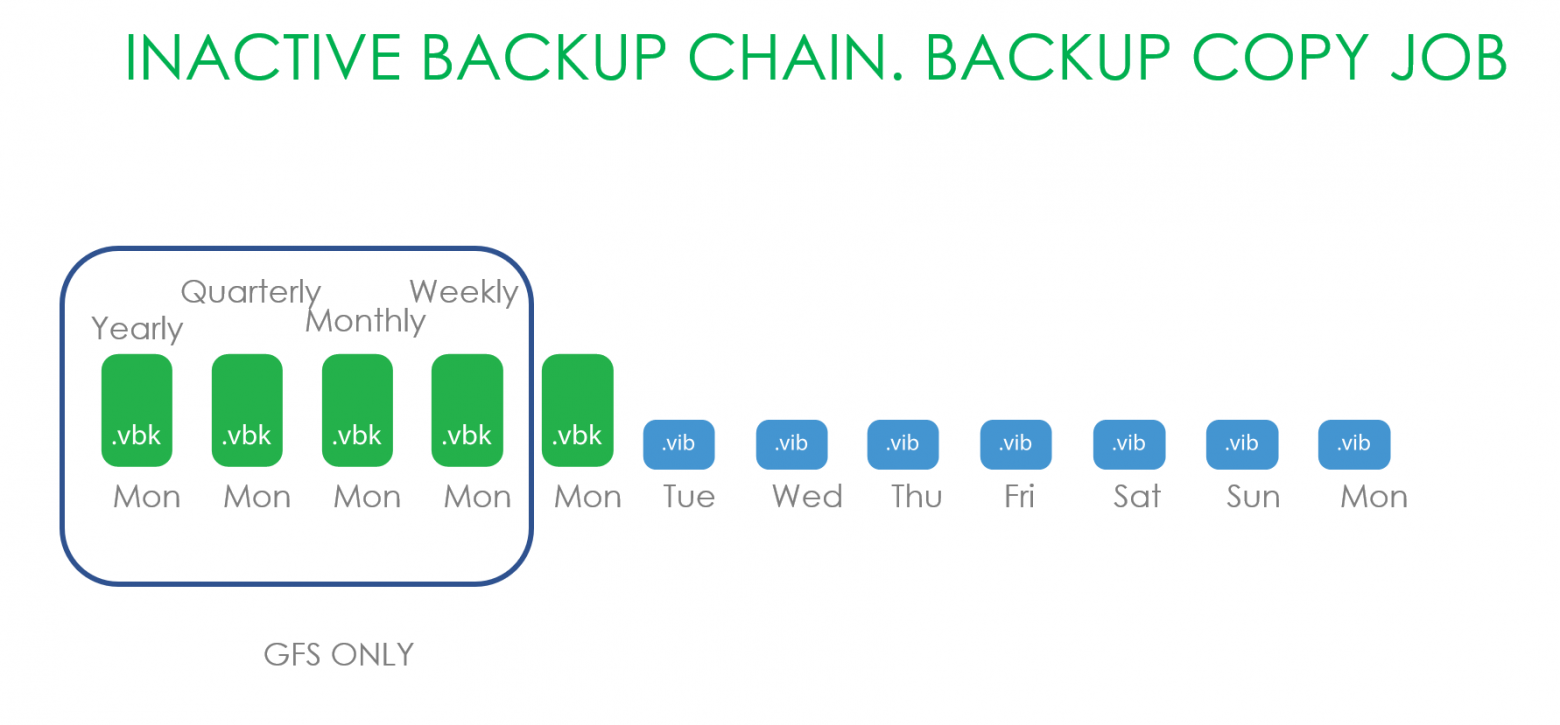
Теперь рассмотрим вариант работы с Backup Copy цепочками. Здесь отвозилось только попадающее под GFS ретеншн. Потому что всё хранящееся в более свежих backup copy цепочках может быть тем или иным способом изменено.
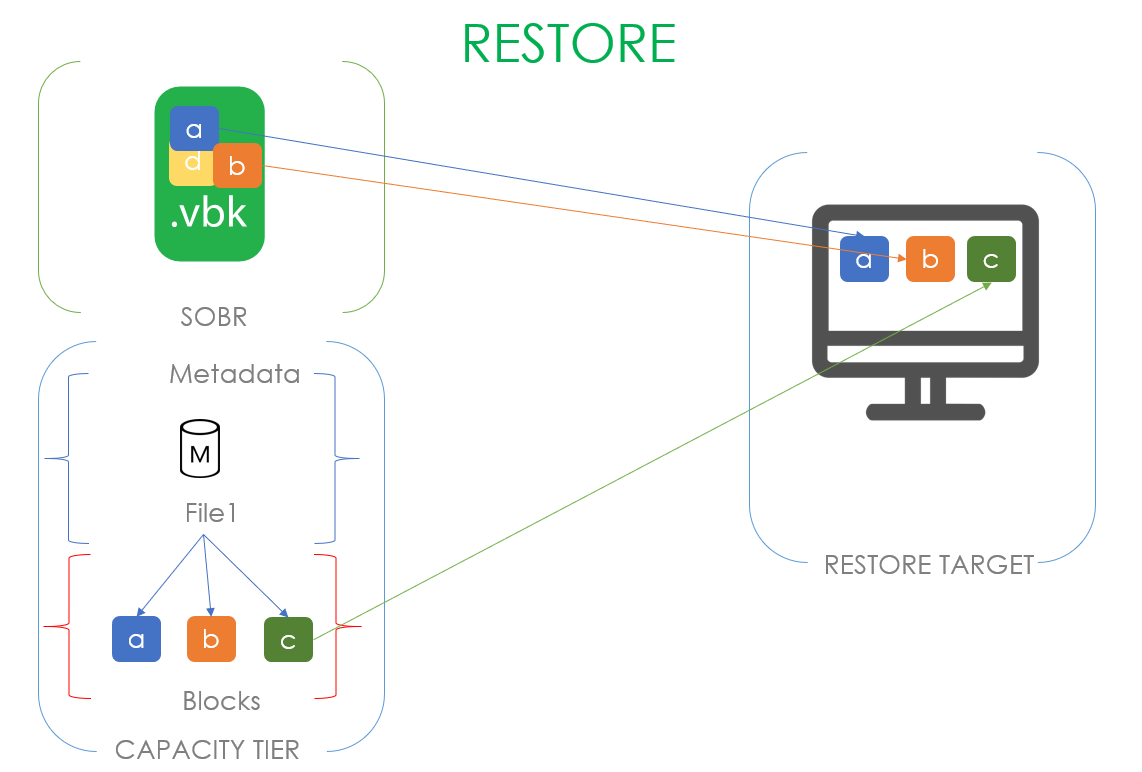
Теперь заглянем под капот. Там происходит процесс, называемый дегидрацией — оставление пустышек бекапных файлов на экстенте и перетаскивание блоков из этих файлов на капасити тир. Для оптимизации этого процесса используется так называемый индекс дегидрации, который позволяет не копировать блоки, которые уже были скопированы в капасити тир.
Рассмотрим, как это выглядит на примере: предположим, что у нас есть .vbk, вышедший из операционного окна и принадлежащий запечатанной цепочке. Значит, мы имеем полное право перенести его в капасити тир. В момент переезда создаётся файл метаданных в капасити тире и блоки переносимого файла. В файле метаданных на уровне ссылок описывается, из каких блоков состоит наш файл. В случае на картинке наш первый файл состоит из блоков a, b, c и в метаданных размещены ссылки на эти блоки. Когда у нас появляется второй .vbk файл, готовый к переезду и состоящий из блоков a, b и d, мы, анализируя индекс дегидрации, понимаем, что переносить надо только блок d. А его файл метаданных будет содержать ссылки на два предыдущих блока и один новый.

Соответственно, процесс обратного заполнения этих пустышек данными называется регидрацией. Здесь используется уже свой индекс регидрации, опирающийся на самый старый .vbk файл на локальном перфоманс экстенте. То есть если пользователь хочет вернуть файл из капасити тира, мы сначала создаём индекс блоков самого старого полного бекапа и переносим из капасити тира только недостающие блоки. В случае, представленном на картинке, чтобы регидрировать FullBackup1.vbk согласно индексу регидрации нам не хватает только блока С, который мы и забираем из капасити тира. Если в качестве капасити тира выступает облачный обжект сторадж, это позволяет экономить колоссальные деньги.
Здесь может показаться, что эта технология идентична используемой в WAN Accelerators, но это только кажется. В акселераторах дедупликация глобальная, здесь же используется локальная в рамках каждого файла по определенному офсету. Это происходит из-за разности решаемых задач: тут нам надо копировать большие файлы фулл бекапов, и по нашим исследованиям, даже если между ними проходит большой период времени, такой алгоритм дедупликации даёт лучший результат.

Но больше индексов богу индексов! Есть ещё и индекс для восстановления данных! Когда мы запускаем восстановление машины, расположенной в капасити тире, то будем читать только уникальные блоки данных, которых нет в перфоманс тире.
На этом с вводной частью всё. Она довольно подробная, но, как говорилось выше, без этих подробностей не получится объяснить, как работают новые функции. Поэтому без лишних предисловий переходим к первой.
Во многом основан на существующих технологиях, однако несёт в себе совершенно другую логику использования.
Цель этого режима — гарантировать, что все данные, расположенные на локальном экстенте, имеют копию в капасити тире.
Если сравнить в лоб Move и Copy режимы, то получится так:
В рассмотрении нового режима предлагаю идти от простых примеров к сложным.
В самом банальном случае у нас просто появляются новые файлы с инкрементами, и мы просто копируем их в капасити тир. Безотносительно того, какой режим используется в бекапной джобе, безотносительно того, принадлежит он к запечатанной части цепочки или нет, безотносительно того, истекло ли наше операционное окно. Просто взяли и скопировали.
Процесс, стоящий за этим — это по-прежнему дегидрация в том виде, как было описано выше. В копи режиме она также следит, чтобы мы не копировали блоки, которые уже есть на нашем сторадже. Единственное отличие — это если в мув режиме мы заменяли реальные файлы файлами пустышками, то здесь мы их никак не трогаем и оставляем всё как есть. В остальном это ровно такой же индекс дегидрации, который тщательно старается экономить ваши деньги и время.

Возникает вопрос — если посмотреть в UI, то там есть возможность выбрать обе опции одновременно. Как будет работать такой совмещённый режим?

Давайте разбираться.
Начало стандартное: создаётся файл бекапа и сразу копируется. К нему создаётся инкремент и тоже копируется. Так происходит до момента, когда мы понимаем, что файлы вышли из нашего операционного окна и появилась запечатанная цепочка. В этот момент мы выполняем операцию дегидрации и замещаем эти файлы пустышками. Само собой, повторно на капасити тир ничего не копируем.
За всю эту увлекательную логику отвечает всего лишь одна галочка в интерфейсе: Copy backups to object storage as soon as they are created.

Даже лучше перефразировать вопрос так — от каких рисков мы защищаемся с его помощью? Какую проблему он помогает нам решать?
Ответ очевиден: конечно же, это восстановление данных. Если у нас на обжект сторадже есть полная копия локальных данных, то неважно, что случится с нашим продом, мы всегда можем восстановить данные с файлов, расположенных в условном амазоне.
Поэтому давайте пройдёмся по возможным сценариям, от наиболее простого к более сложным.
Самая простая напасть, которая может свалиться на наши головы — это недоступность одного из файлов в бекапной цепочке.
Более печальная история — у нас сломался один из экстентов нашего SOBR репозитория.
Ещё хуже становится, когда весь SOBR репозиторий стал недоступен, но работает капасити тир.
И совсем всё плохо — это когда умирает бекапный сервер и твоё первое желание — попробовать добежать до канадской границы за десять минут.

А теперь давайте разберём каждую ситуацию отдельно.
Когда мы потеряли один (да пусть с ним, даже несколько) бекапных файлов, то нам достаточно будет запустить процесс рескана репозитория, и потерянный файл будет заменён файлом-пустышкой. А с помощью процесса регидрации (о котором было в начале статьи) пользователь сможет скачать данные из капасити тира в локальное хранилище.
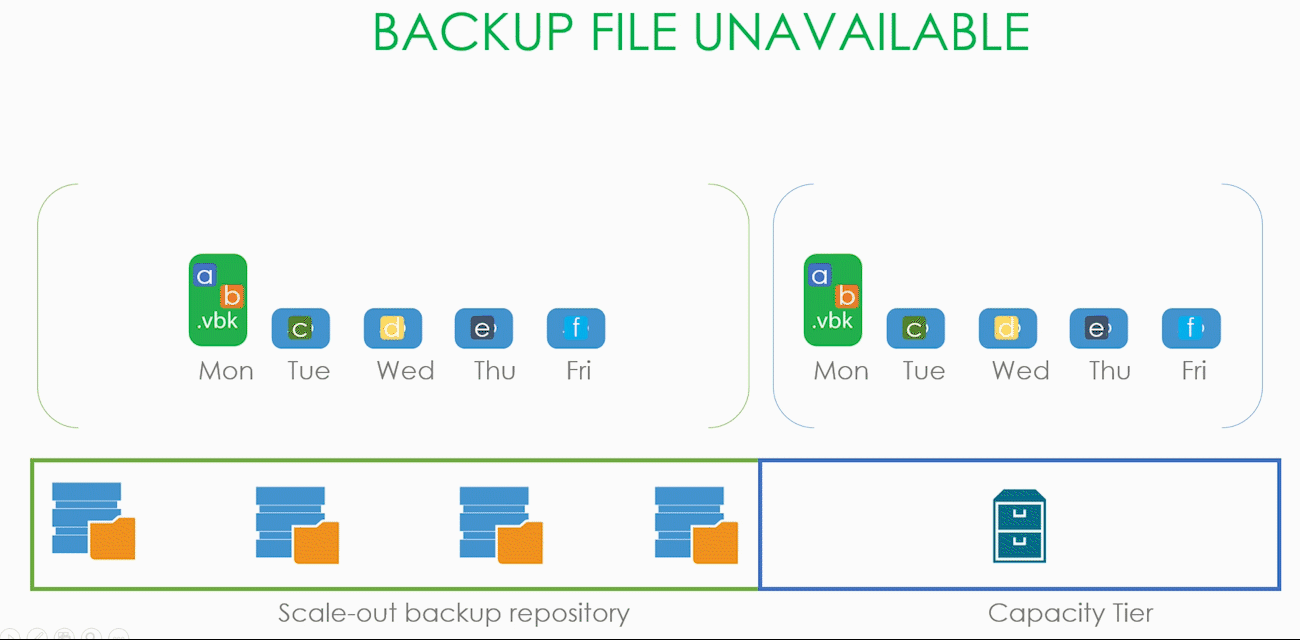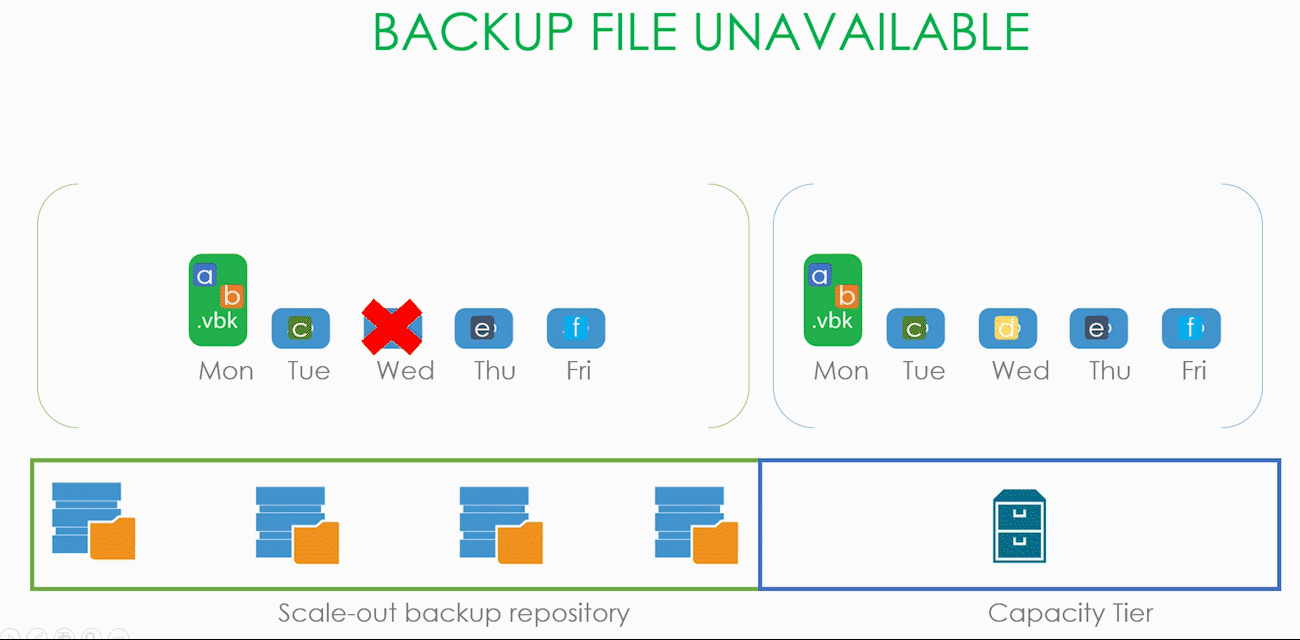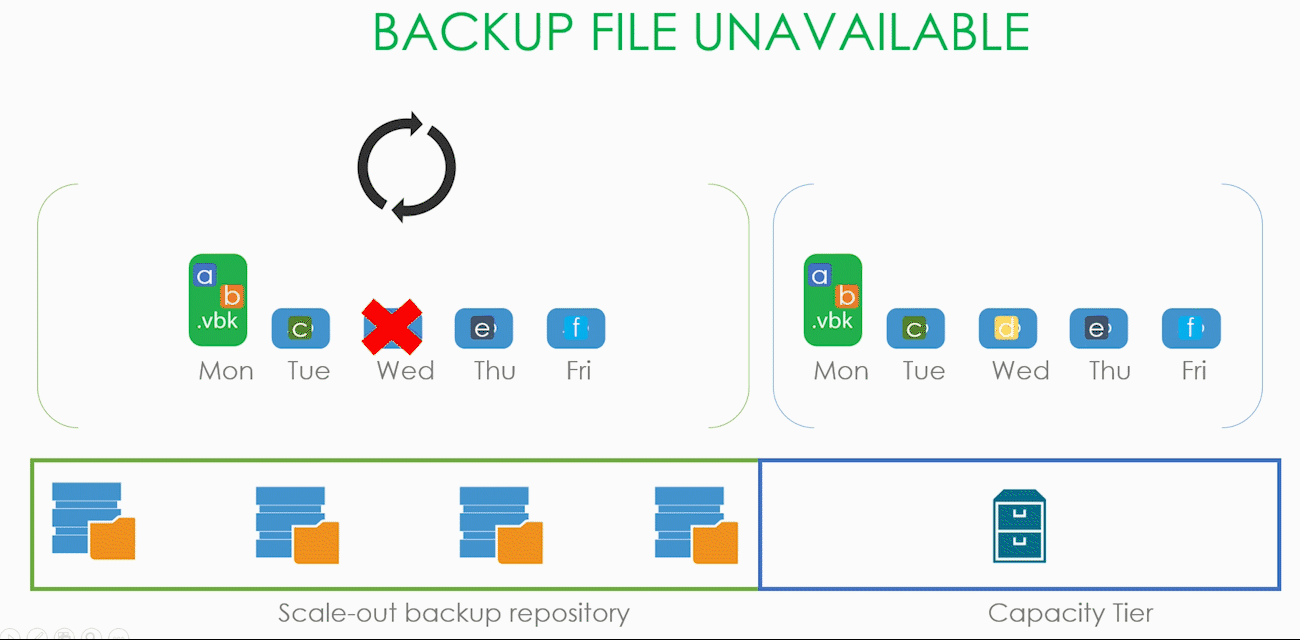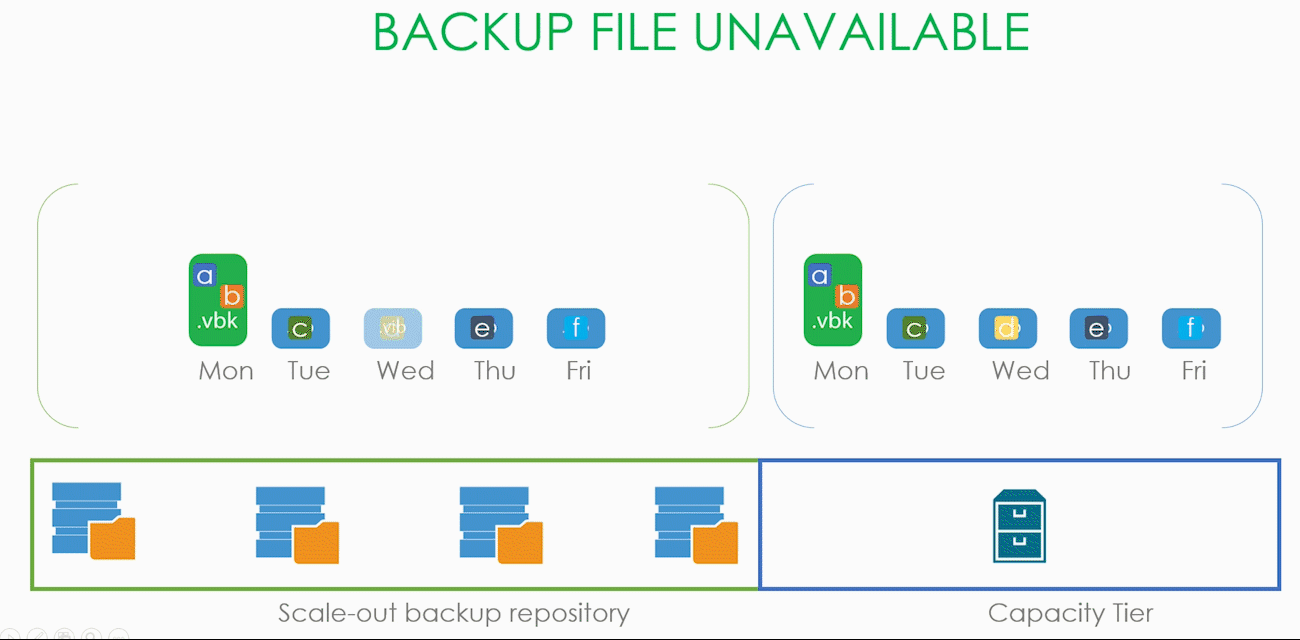
Теперь ситуация посложнее. Предположим, что наш SOBR состоит из двух экстентов, работающих в Performance режиме, а значит, наши .vbk и .vib размазаны по ним довольно неравномерным слоем. И в какой-то момент времени один из экстентов становится недоступным, а пользователю надо срочно восстановить машину, часть данных которой лежит именно на этом экстенте.
Пользователь запускает визард восстановления, выбирает точку, на которую хочет восстановить, а визард в процессе работы приходит к осознанию, что всех необходимых для восстановления данных локально у него нет и поэтому их надо скачать из капасити тира. При этом блоки, которые остались на локальном хранилище, скачиваться из облака не будут. Слава restore индексу (да, про него тоже было в начале статьи).
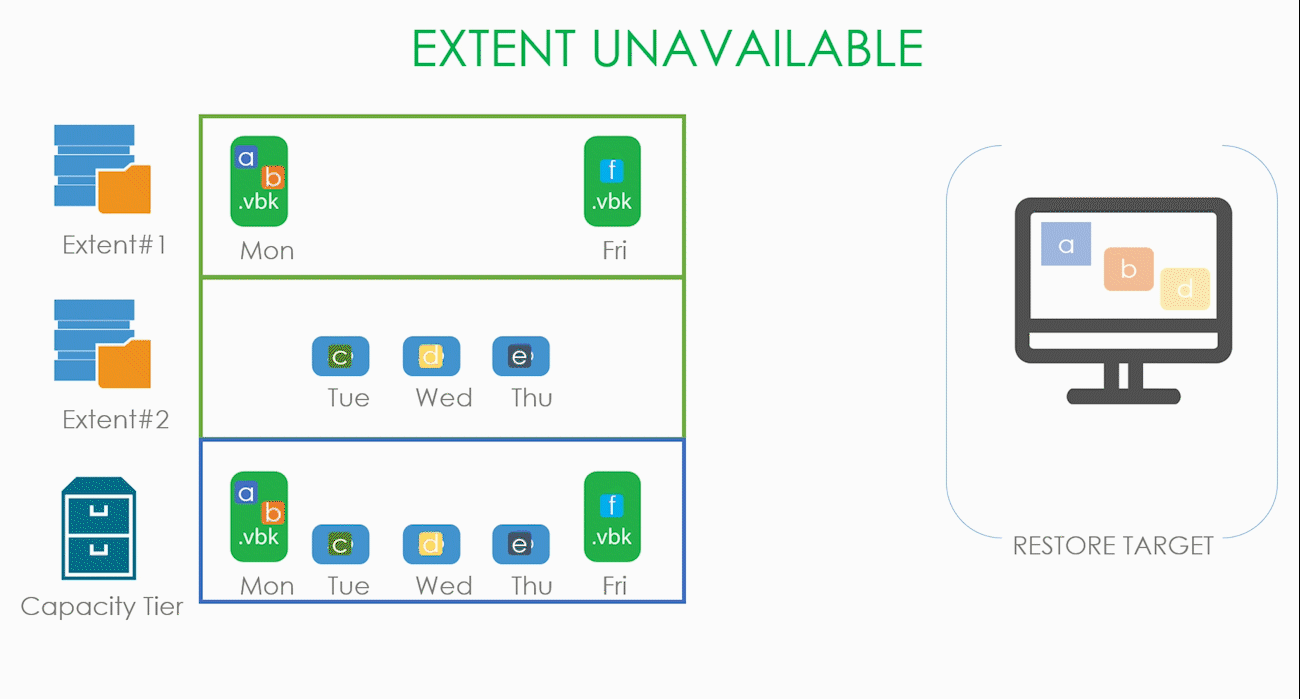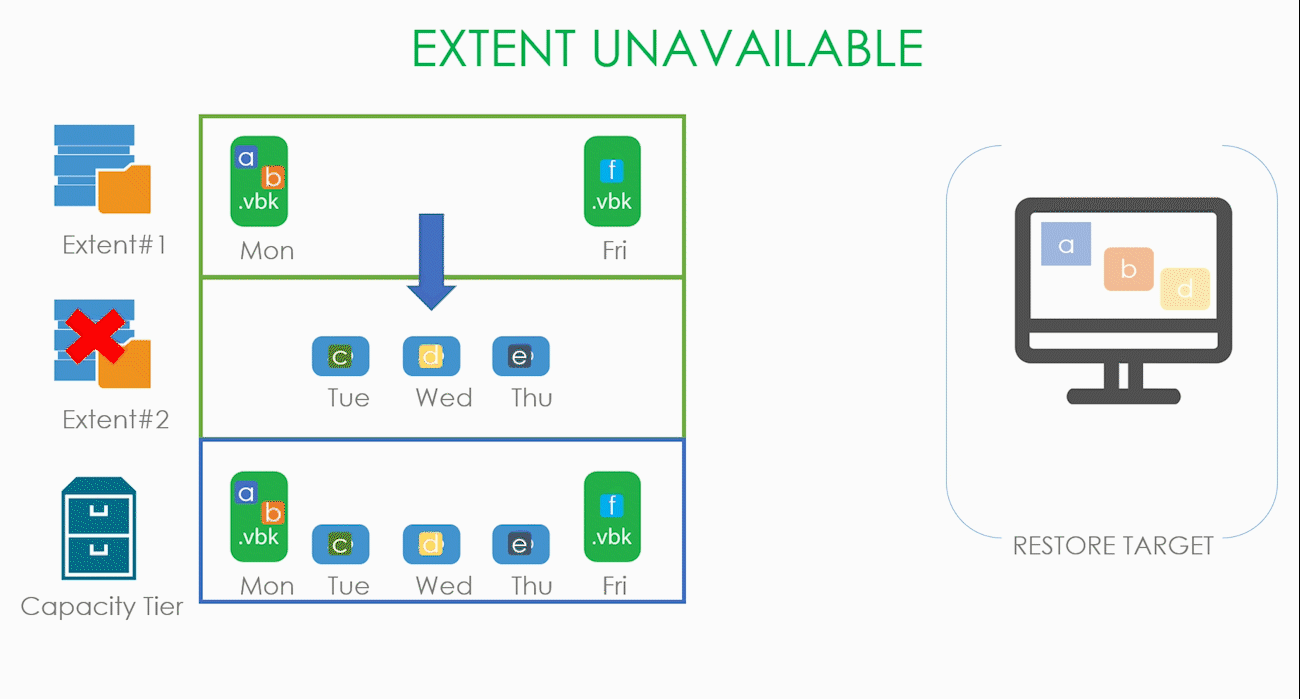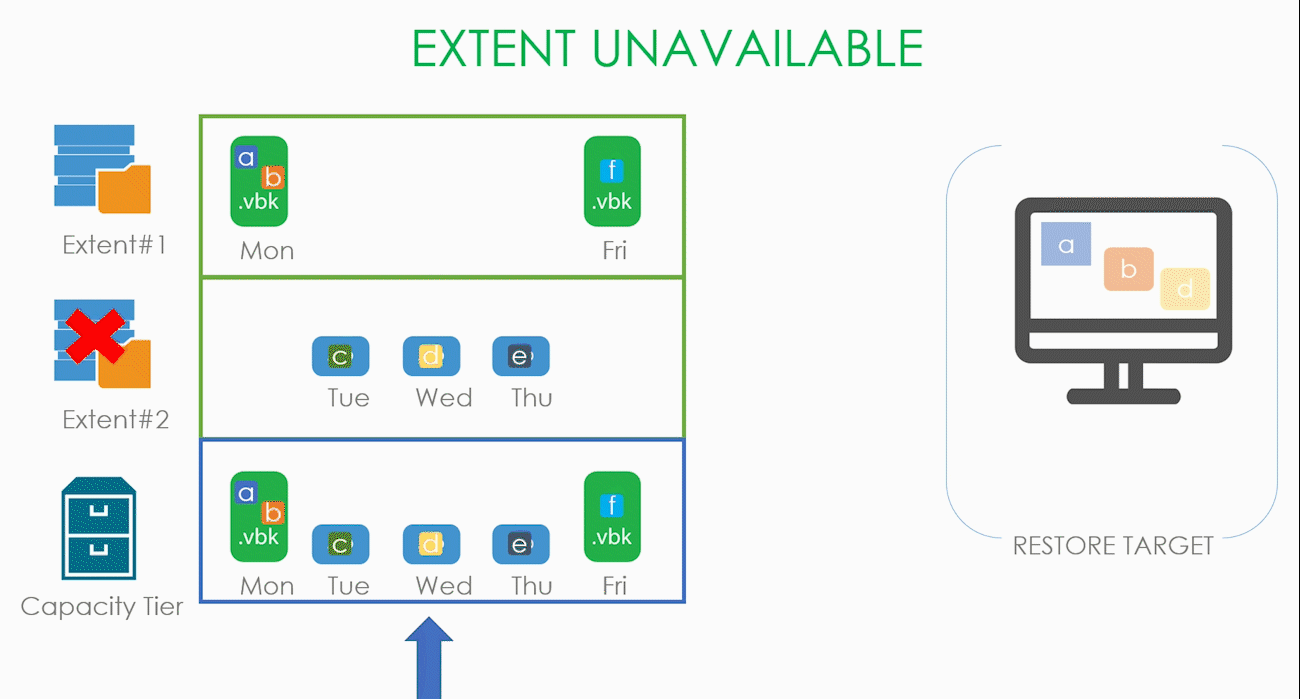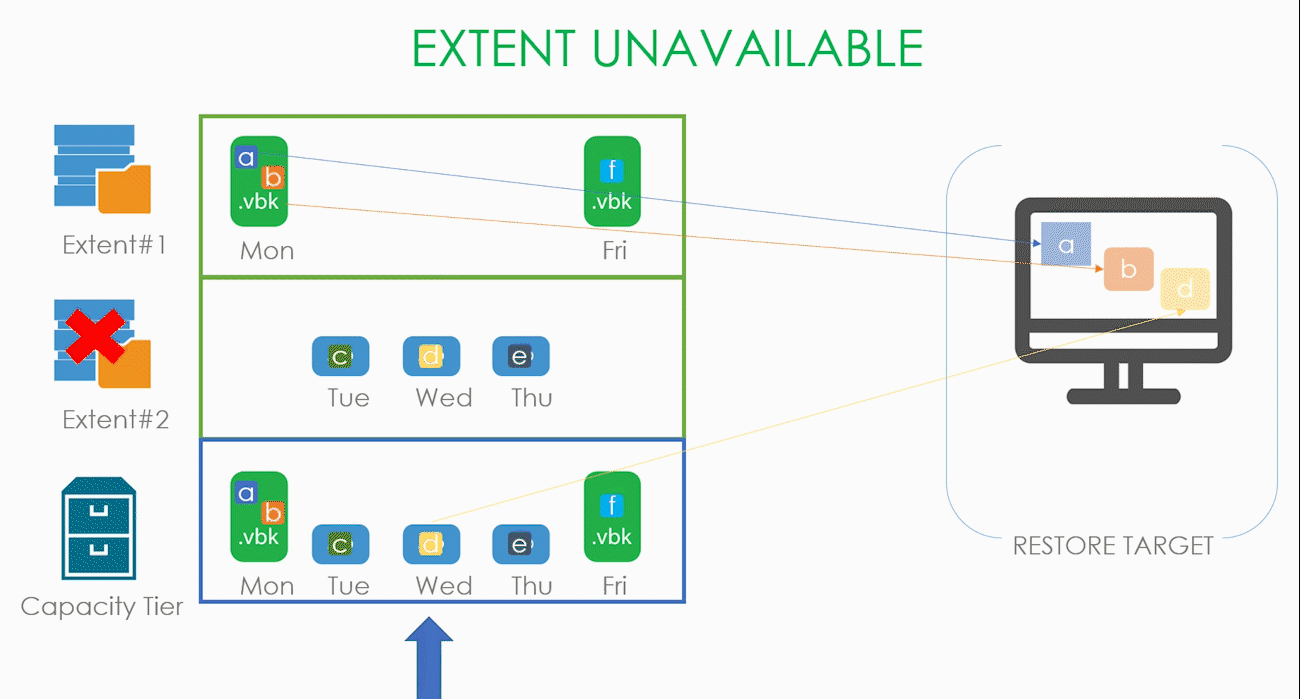
Подвид этого случая — стал недоступен весь SOBR репозиторий. В таком случае нам нечего копировать с локальных хранилищ, и все блоки скачиваются из облака.
И самая интересная ситуация — умер бекапный сервер. Тут есть два варианта: админ молодец и делал конфигурационные бекапы, и админ сам себе злобный Буратино и не делал конфигурационный бекап.
В первом случае ему будет достаточно просто где-то развернуть чистую инсталляцию VBR и восстановить его базу из бекапа штатными средствами. В завершении этого процесса всё вернётся на круги своя. Или же будет восстановлено по одному из сценариев выше.
Но если админ или сам себе враг, или бекап конфигурации тоже постигла былинная неудача, то даже здесь мы не бросим его на произвол судьбы. Для этого случая мы ввели новую процедуру, которая называется Import Object Storage. Она позволяет пропустить процесс воссоздания вручную SOBR репозитория и прикрепления к нему капасити тира с последующим ресканом, а просто добавить обжект сторадж в интерфейс вима и запустить Import Storage Repository процедуру. Единственное, что может встать на пути между вами и вашими бекапами — это просьба ввести пароль, если ваши бекапы были зашифрованы.
На этом про Copy Mode, пожалуй, всё и мы переходим к
Основная задумка — на выбранном экстенте SOBR репозитория не могут появляться новые бекапы. До v10 у нас был только Maintenance Mode, когда полностью запрещалась любая работа с репозиторием. Этакий хардкорный режим вывода хранилища из работы, где доступна только кнопка Evacuate, разово перевозившая бекапы на другой экстент.
А Sealed mode — это своеобразный “мягкий” вариант: мы запрещаем создавать новые бекапы и постепенно удаляем старые согласно выбранному ретеншн, но в процессе не теряем возможность восстанавливаться из хранящихся точек. Очень полезная штука, когда у нас или подходит к концу срок жизни железки и её надо будет заменить, или её просто надо освободить под что-то более важное, а брать и разово всё переносить некуда. Или нельзя удалить.
Соответственно, принцип работы довольно прост: надо запретить все write операции (появление новых данных), оставив read(ресторы) и delete(ретеншн).
Оба режима можно использовать одновременно, только надо учитывать, что у Maintenance приоритет выше.
В качестве примера рассмотрим SOBR, состоящий из двух экстентов. Предположим, первые четыре дня у нас создавались бекапы в режиме Forward Forever Incremental, а потом мы запечатываем экстент.Это ведёт к тому, что мы инициируем создание нового эктив фула на втором доступном экстенте. Если наш ретенш равен четырём, то когда вся цепочка, расположенная на запечатанном экстенте, выйдет за его пределы, она со спокойной совестью удаляется.

Есть ситуации, когда удаление происходит раньше. Например, это Forward incremental с периодическими фулами. Если первые два дня у нас создавались фул бекапы, а в четверг мы решаем запечатать репозиторий, то в пятницу, когда создастся новый фульник, то файл за понедельник будет удалён т.к. к этой точке нет зависимостей. И сама точка ни от кого не зависит. После чего мы дожидаемся когда будут созданы четыре точки на доступном экстенте и удаляем оставшиеся три, которые не могут быть удалены независимо друг от друга.

Проще дела обстоят с Reverse Incremental. В нём самые старые точки ни от чего не зависят и могут быть спокойно удалены. Поэтому, как только будет создан новый .vbk на новом экстенте, старые .vrb будут по одному удаляться.
Кстати, почему мы каждый раз создаём новый .vbk: если его не создавать, а продолжать старую цепочку инкрементов, то старый .vbk подвисал бы на бесконечно долгое время в любом режиме, препятствуя его удалению. Поэтому было принято решение, что как только запечатывается экстент, мы создаём фул бекап на свободном экстенте.

Сложнее дела обстоят с капасити тиром.
Сначала рассмотрим copy mode. Предположим, что у нас четыре дня активно создавались бекапы, а потом капасити тир был запечатан. Мы ничего не удаляем, а смиренно выдерживаем ретеншн, после чего удаляем данные с капасити тира.
Примерно то же самое происходит при move mode — выжидаем ретенш, удаляем старое в локальном хранилище, удаляем хранящееся в обжект сторадже.

Интересный пример с Forever forward incremental. Устанавливаем ретенш в три точки и начинаем с понедельника делать бекапы, которые исправно копируются в облако. После запечатывания хранилища бекапы продолжают создаваться, выдерживая три точки, но хранящиеся в капасити тире данные остаются зависимыми и не могут быть удалены. Поэтому мы дожидаемся четверга, когда наш .vbk выходит за рамки ретеншн, и только тогда спокойно удаляем всю сохранённую цепочку.

И небольшая оговорка: все примеры здесь показаны с одной машиной. Если у вас в бекапе их несколько, то ретенш у них будет отличаться в зависимости от того, был сделан Active Full или нет.
На этом, в принципе, и всё. Так что переходим к самой хардкорной фиче —
Как и с предыдущими пунктами, первым делом о том, какую проблему решает эта функция. Как только мы выгружаем куда-то наши бекапы на хранение, возникает острое желание гарантировать их сохранность, то есть физически запретить их удаление и любую модификацию в течении заданного ретеншена. В том числе админами, в том числе под их рутовыми учётками. Это позволяет защитить их от случайной или преднамеренной порчи. Кто работает с AWS, мог встречать подобную функцию под названием Object Lock.
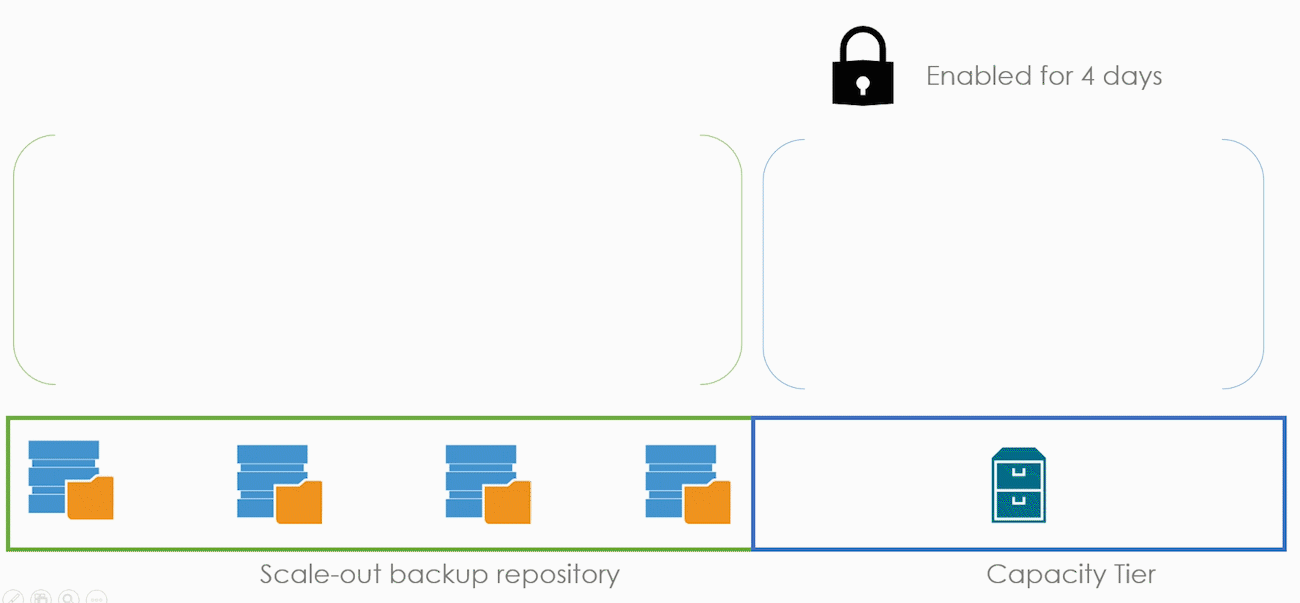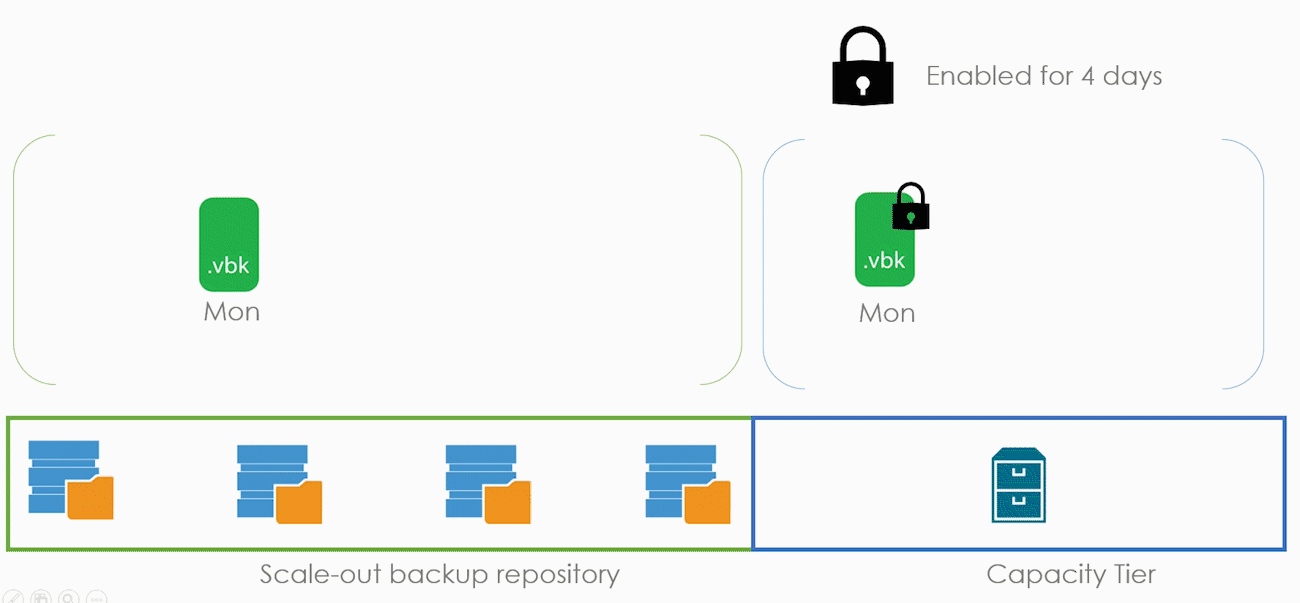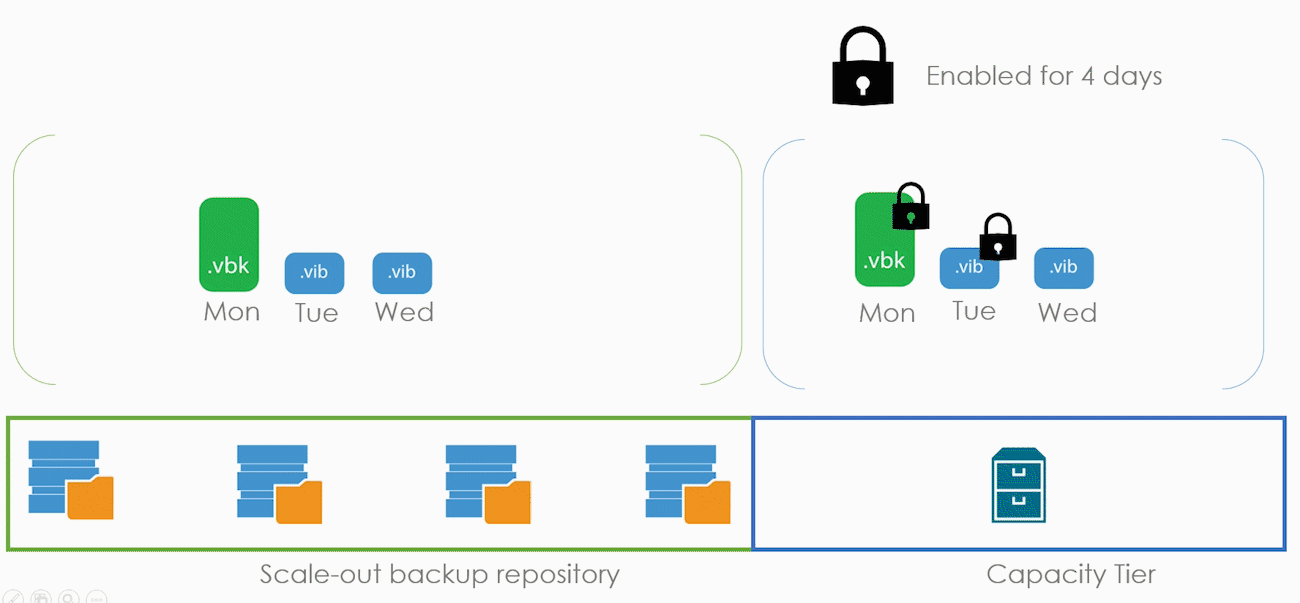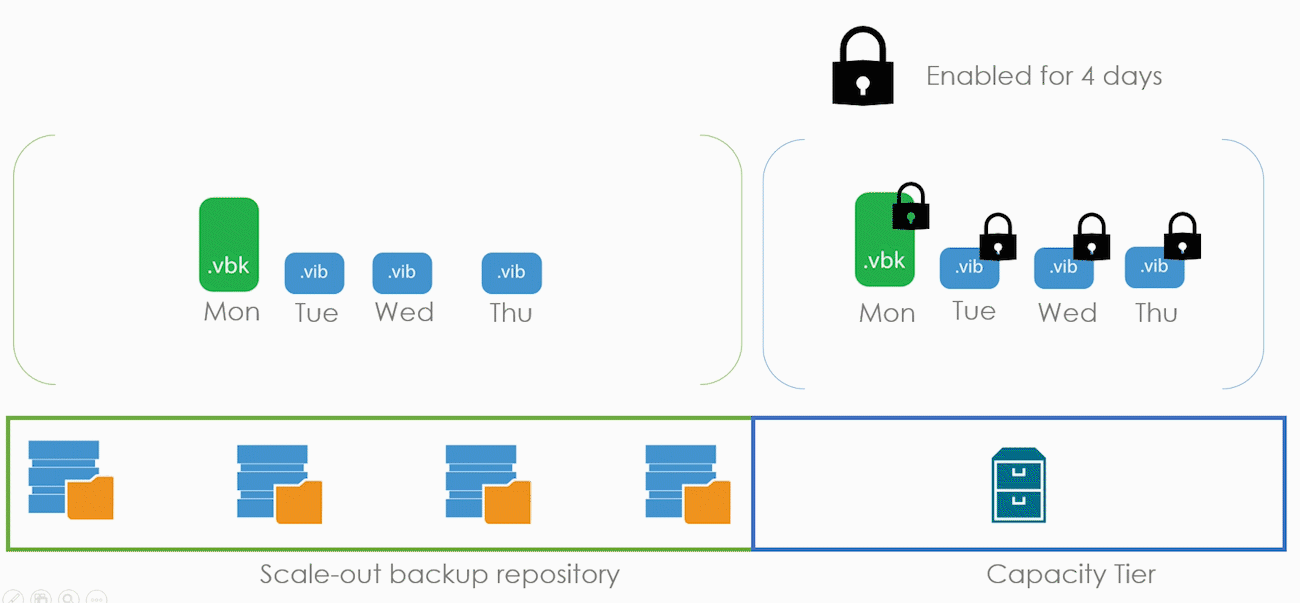
Теперь рассмотрим режим в общих словах, а потом углубимся в детали. В нашем примере Immutability будет включен для нашего капасити тира с ретенш в четыре дня. А в бекапе включен режим Copy.
Immutability никак не взаимодействует с общим ретеншном. Например, он не добавляет дополнительных точек или что-то такое. Просто в течение четырёх дней человек не может удалить файлы бекапов. Если в понедельник сделать бекап, то удалить его файл получится только в пятницу.
Все ранее объяснённые концепты дегидрации, индексов и метаданных продолжают работать точно так же. Но с одним условием — блок выставляется не только для данных, но и на метаданные. Это сделано на случай, если коварный злоумышленник решит стереть нашу базу метаданных и чтобы блоки с данными не превратились в бесполезную бинарную кашу.

И теперь настал отличный момент для объяснения нашей технологии поколения блоков. Или block generation. Для этого рассмотрим ситуацию, которая привела к её появлению.
Возьмём временную шкалу в шесть дней и снизу будем отмечать время ожидаемого истечения immutability. Берём и создаём в первый день файл, состоящий из блока данных а, и его метаданные. Если immutability установлен в три дня, логично предположить, что на четвёртый день данные будут разлочены и удалены. На второй день добавим новый file2, состоящий из блока b с теми же настройками. Блок а всё ещё должен быть удалён на четвёртый день. Но на третий день случается страшное — создаётся файл File3, состоящий из нового блока d и ссылки на старый блок а. Это значит, что для блока а его immutability флаг должен быть перевыставлен на новый срок, который сдвигается на шестой день. И тут возникает проблема — в реальных бекапах таких блоков возникает огромное количество. А чтобы продлить им immutability период, надо каждый раз совершать огромное количество запросов. И фактически это будет около-бесконечный ежедневный процесс, так как с большой долей вероятности мы при каждом копировании будем находить здоровенные пачки дедуплицированных блоков. А что значит большое количество запросов у провайдеров обжект стораджей? Правильно! Огромный счёт в конце месяца.

И чтобы не выставлять на ровном месте на солидные деньги своих любимых клиентов, был придуман механизм block generation. Это дополнительный период, который мы добавляем к выставленному периоду immutability. В примере ниже такой период равняется двум дням. Но это только для примера. В реальности там используется своя формула, дающая примерно десять дополнительных дней при месячном локе.
Продолжим рассматривать туже ситуацию, но уже с block generation. Создаём в первый день file1 из блока а и метаданных. Складываем период поколений и immutability — значит, возможность удалить файл будет на шестой день. Если на второй день мы создадим File2, состоящий из блока b и ссылки на блок а, то с предполагаемой датой удаления ничего не происходит. Она как стояла на шестой день, так и стоит. А мы тем самым пытаемся экономить деньги на количестве запросов. Единственная ситуация, когда срок может быть сдвинут, это если generation period истёк. То есть, если на третий день новый File3 будет содержать ссылку на блок а, то будет добавлен generation 2 так как Gen1 уже истёк. А ожидаемая дата удаления блока а сместится на восьмой день. Это позволяет нам драматически снизить количество запросов на продление времени жизни дедуплицированных блоков, что экономит вагон денег клиентам.

Сама технология доступна пользователям S3 и S3-совместимого железа, производители которого гарантируют, что их реализация не отличается от амазоновской. Отсюда ответ на законный вопрос, почему не поддерживается Azure — у них есть схожая фича, но она работает на уровне контейнеров, а не отдельных объектов. Кстати, в самом амазоне обжект лок есть в двух режимах: compliance и governance. Во втором случае остаётся возможность, чтобы самый великий админ над админами и рут над рутами, несмотря на обжект лок, всё же удалил данные. В случае compliance всё прибито гвоздями намертво и бекапы не удалить никому. Даже у админов амазона (по их официальным заявлениям). Мы поддерживаем именно этот режим.
И, традиционно, немного полезных ссылок:
Для выполнения этого нехитрого (как кажется) действия достаточно было соблюсти два условия: все точки из перемещаемого бекапа должны быть за границами вышеназванного operational restore window, которое задаётся в явном виде в UI. И второе: цепочка должна быть в так называемом «запечатанном виде»(sealed backup chain или Inactive Backup Chain). То есть с течением времени в этой цепочке не происходит изменений.
Но в VBR v10 концепция дополнилась новыми функциями — появился Copy Mode, Sealed Mode и штука со сложновыговариваемым названием Immutability.
Вот об этих увлекательных вещах мы сегодня и поговорим. Сначала о том, как это работало в VBR9.5u4, а потом об изменениях в десятой версии.

И да простят меня поборники чистого языка, но слишком много терминов невозможно перевести.
Так что здесь будет тьма англицизмов.
И много гифок.
И картинок.
- Без малейших сожалений. Автор статьи.
Как было
Ну что же, начинаем с разбора operational restore window и sealed backup (или как они называбтся в документации Inactive Backup Chain). Без их понимания дальнейшее объяснить не получится.
Как мы видим на картинке, у нас есть некая бекапная цепочка с блоками данных, которая расположена на Performance tier SOBR репозитория, к которому подключён Capacity Tier. Наше окно операционного бекапа равно трём дням.
Соответственно, созданный в понедельник .vbk запечатывает предыдущую цепочку, окно которой установлено на три дня. И, значит, спокойно можно начинать отвозить в капасити тир всё что старше этих трёх дней.
Но что именно подразумевалось под sealed цепочкой и что могло отправляться в капасити тир в update 4?
Для Forward Incremental признаком запечатывания цепочки является создание нового фул бекапа. И не важно, как этот фульник получается: считаются и synthetic full, и active full бекапы.
В случае Reverse это все файлы, не попадающие в операционное окно.
В случае Forward increment с роллбеками это все роллбеки и .vbk, если на перфоманс экстенте есть ещё один .vbk
Теперь рассмотрим вариант работы с Backup Copy цепочками. Здесь отвозилось только попадающее под GFS ретеншн. Потому что всё хранящееся в более свежих backup copy цепочках может быть тем или иным способом изменено.

Теперь заглянем под капот. Там происходит процесс, называемый дегидрацией — оставление пустышек бекапных файлов на экстенте и перетаскивание блоков из этих файлов на капасити тир. Для оптимизации этого процесса используется так называемый индекс дегидрации, который позволяет не копировать блоки, которые уже были скопированы в капасити тир.
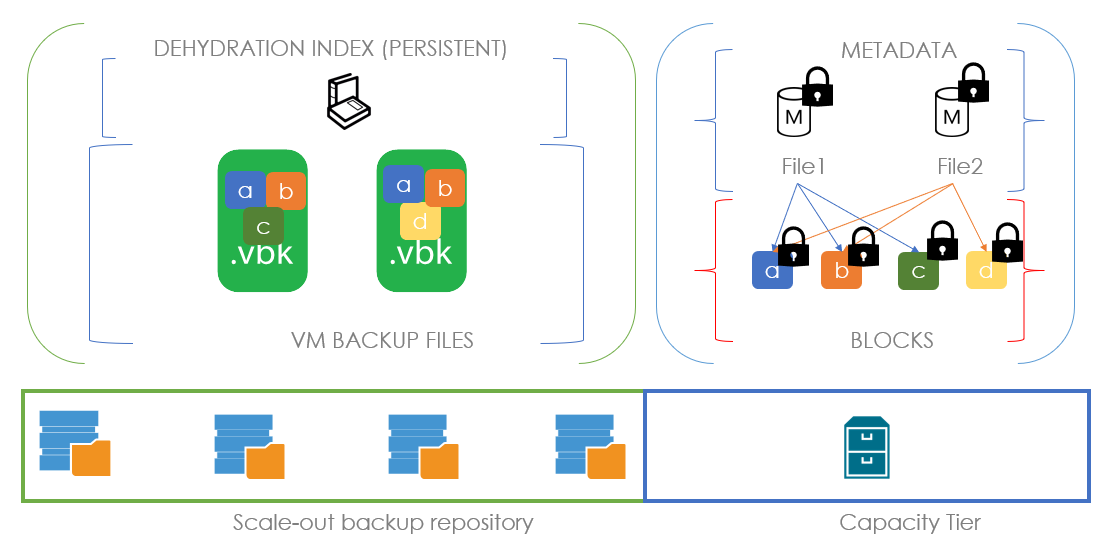
Рассмотрим, как это выглядит на примере: предположим, что у нас есть .vbk, вышедший из операционного окна и принадлежащий запечатанной цепочке. Значит, мы имеем полное право перенести его в капасити тир. В момент переезда создаётся файл метаданных в капасити тире и блоки переносимого файла. В файле метаданных на уровне ссылок описывается, из каких блоков состоит наш файл. В случае на картинке наш первый файл состоит из блоков a, b, c и в метаданных размещены ссылки на эти блоки. Когда у нас появляется второй .vbk файл, готовый к переезду и состоящий из блоков a, b и d, мы, анализируя индекс дегидрации, понимаем, что переносить надо только блок d. А его файл метаданных будет содержать ссылки на два предыдущих блока и один новый.

Соответственно, процесс обратного заполнения этих пустышек данными называется регидрацией. Здесь используется уже свой индекс регидрации, опирающийся на самый старый .vbk файл на локальном перфоманс экстенте. То есть если пользователь хочет вернуть файл из капасити тира, мы сначала создаём индекс блоков самого старого полного бекапа и переносим из капасити тира только недостающие блоки. В случае, представленном на картинке, чтобы регидрировать FullBackup1.vbk согласно индексу регидрации нам не хватает только блока С, который мы и забираем из капасити тира. Если в качестве капасити тира выступает облачный обжект сторадж, это позволяет экономить колоссальные деньги.
Здесь может показаться, что эта технология идентична используемой в WAN Accelerators, но это только кажется. В акселераторах дедупликация глобальная, здесь же используется локальная в рамках каждого файла по определенному офсету. Это происходит из-за разности решаемых задач: тут нам надо копировать большие файлы фулл бекапов, и по нашим исследованиям, даже если между ними проходит большой период времени, такой алгоритм дедупликации даёт лучший результат.
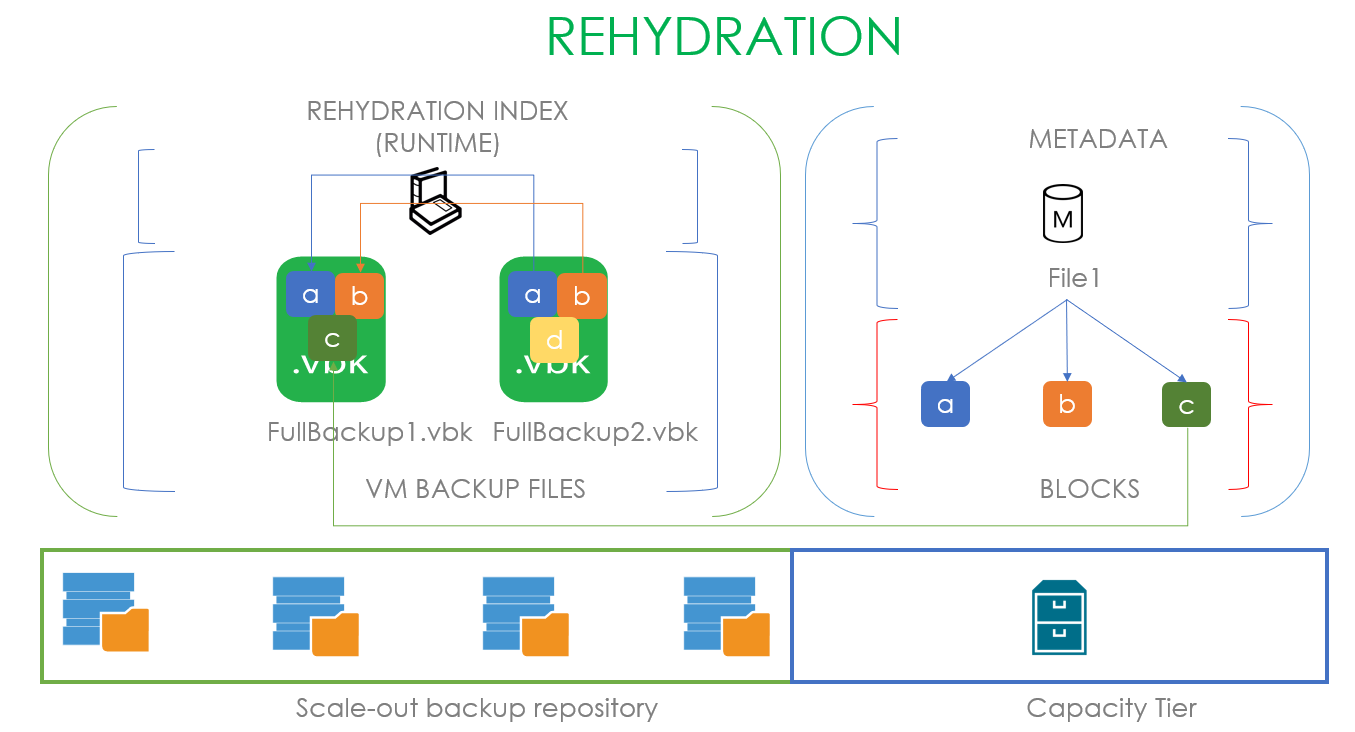
Но больше индексов богу индексов! Есть ещё и индекс для восстановления данных! Когда мы запускаем восстановление машины, расположенной в капасити тире, то будем читать только уникальные блоки данных, которых нет в перфоманс тире.
Как стало
На этом с вводной частью всё. Она довольно подробная, но, как говорилось выше, без этих подробностей не получится объяснить, как работают новые функции. Поэтому без лишних предисловий переходим к первой.
Copy mode
Во многом основан на существующих технологиях, однако несёт в себе совершенно другую логику использования.
Цель этого режима — гарантировать, что все данные, расположенные на локальном экстенте, имеют копию в капасити тире.
Если сравнить в лоб Move и Copy режимы, то получится так:
- Перемещать можно только запечатанную цепочку. В случае копи режима отвозится абсолютно всё, независимо от того, что происходит в бекапной джобе.
- Перемещение срабатывает, когда файлы выходят за границы окна операционного бекапа, а копирование срабатывает сразу, как только появляется бекапный файл.
- Отслеживание новых данных для копирования происходит постоянно, а для перемещения срабатывало раз в 4 часа.
В рассмотрении нового режима предлагаю идти от простых примеров к сложным.
В самом банальном случае у нас просто появляются новые файлы с инкрементами, и мы просто копируем их в капасити тир. Безотносительно того, какой режим используется в бекапной джобе, безотносительно того, принадлежит он к запечатанной части цепочки или нет, безотносительно того, истекло ли наше операционное окно. Просто взяли и скопировали.
Процесс, стоящий за этим — это по-прежнему дегидрация в том виде, как было описано выше. В копи режиме она также следит, чтобы мы не копировали блоки, которые уже есть на нашем сторадже. Единственное отличие — это если в мув режиме мы заменяли реальные файлы файлами пустышками, то здесь мы их никак не трогаем и оставляем всё как есть. В остальном это ровно такой же индекс дегидрации, который тщательно старается экономить ваши деньги и время.
Возникает вопрос — если посмотреть в UI, то там есть возможность выбрать обе опции одновременно. Как будет работать такой совмещённый режим?
Давайте разбираться.
Начало стандартное: создаётся файл бекапа и сразу копируется. К нему создаётся инкремент и тоже копируется. Так происходит до момента, когда мы понимаем, что файлы вышли из нашего операционного окна и появилась запечатанная цепочка. В этот момент мы выполняем операцию дегидрации и замещаем эти файлы пустышками. Само собой, повторно на капасити тир ничего не копируем.
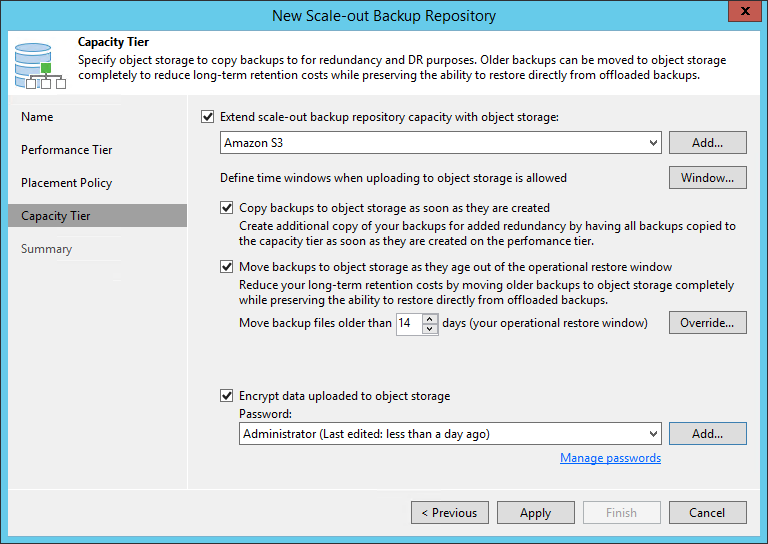
За всю эту увлекательную логику отвечает всего лишь одна галочка в интерфейсе: Copy backups to object storage as soon as they are created.
А зачем нам этот Copy режим?
Даже лучше перефразировать вопрос так — от каких рисков мы защищаемся с его помощью? Какую проблему он помогает нам решать?
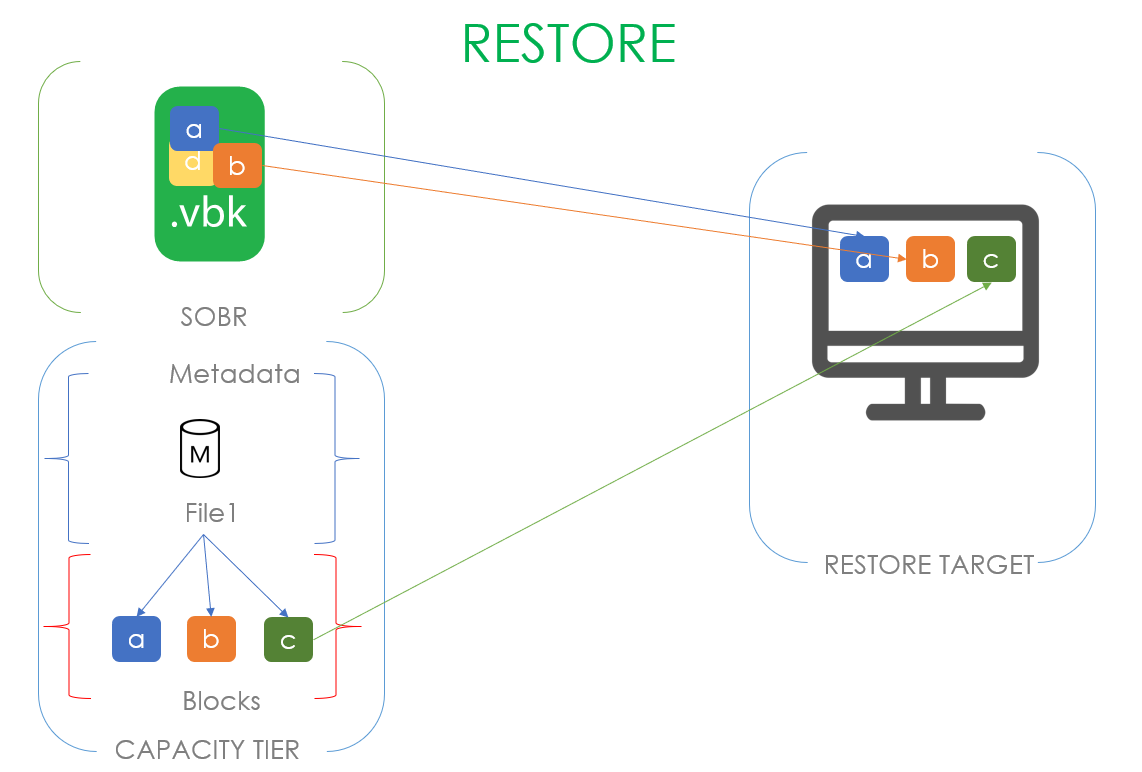
Ответ очевиден: конечно же, это восстановление данных. Если у нас на обжект сторадже есть полная копия локальных данных, то неважно, что случится с нашим продом, мы всегда можем восстановить данные с файлов, расположенных в условном амазоне.
Поэтому давайте пройдёмся по возможным сценариям, от наиболее простого к более сложным.
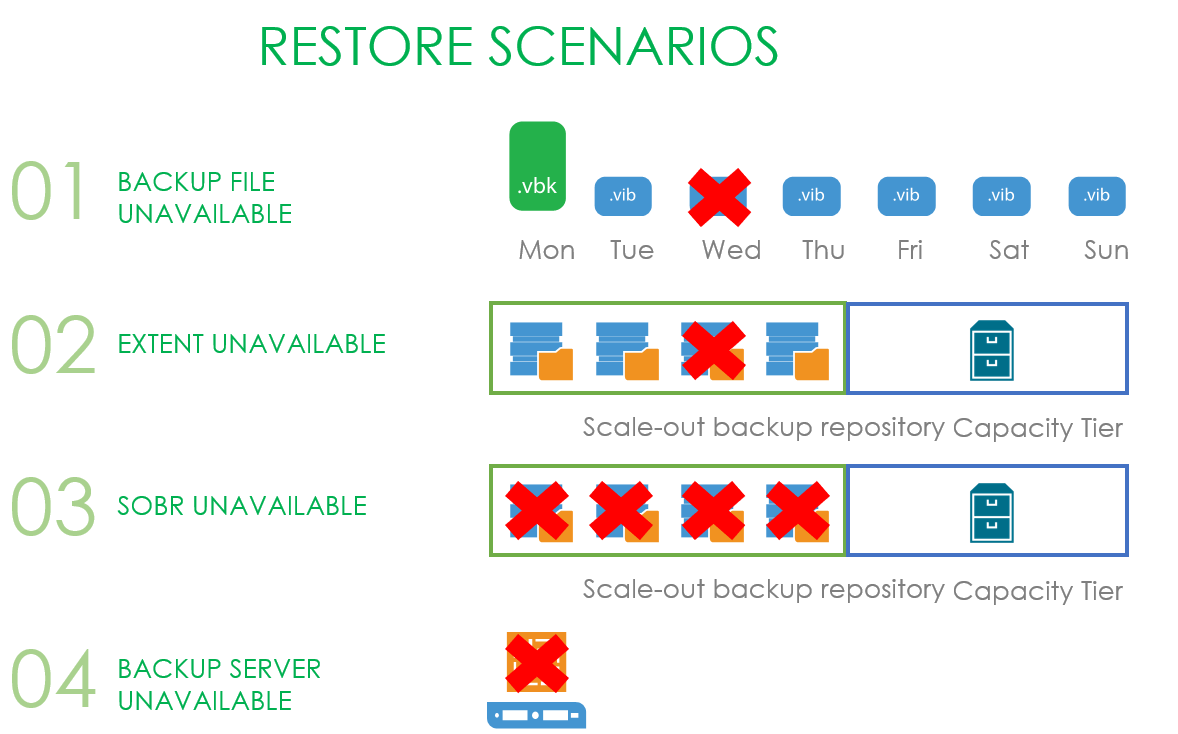
Самая простая напасть, которая может свалиться на наши головы — это недоступность одного из файлов в бекапной цепочке.
Более печальная история — у нас сломался один из экстентов нашего SOBR репозитория.
Ещё хуже становится, когда весь SOBR репозиторий стал недоступен, но работает капасити тир.
И совсем всё плохо — это когда умирает бекапный сервер и твоё первое желание — попробовать добежать до канадской границы за десять минут.
А теперь давайте разберём каждую ситуацию отдельно.
Когда мы потеряли один (да пусть с ним, даже несколько) бекапных файлов, то нам достаточно будет запустить процесс рескана репозитория, и потерянный файл будет заменён файлом-пустышкой. А с помощью процесса регидрации (о котором было в начале статьи) пользователь сможет скачать данные из капасити тира в локальное хранилище.
Теперь ситуация посложнее. Предположим, что наш SOBR состоит из двух экстентов, работающих в Performance режиме, а значит, наши .vbk и .vib размазаны по ним довольно неравномерным слоем. И в какой-то момент времени один из экстентов становится недоступным, а пользователю надо срочно восстановить машину, часть данных которой лежит именно на этом экстенте.
Пользователь запускает визард восстановления, выбирает точку, на которую хочет восстановить, а визард в процессе работы приходит к осознанию, что всех необходимых для восстановления данных локально у него нет и поэтому их надо скачать из капасити тира. При этом блоки, которые остались на локальном хранилище, скачиваться из облака не будут. Слава restore индексу (да, про него тоже было в начале статьи).
Подвид этого случая — стал недоступен весь SOBR репозиторий. В таком случае нам нечего копировать с локальных хранилищ, и все блоки скачиваются из облака.
И самая интересная ситуация — умер бекапный сервер. Тут есть два варианта: админ молодец и делал конфигурационные бекапы, и админ сам себе злобный Буратино и не делал конфигурационный бекап.
В первом случае ему будет достаточно просто где-то развернуть чистую инсталляцию VBR и восстановить его базу из бекапа штатными средствами. В завершении этого процесса всё вернётся на круги своя. Или же будет восстановлено по одному из сценариев выше.
Но если админ или сам себе враг, или бекап конфигурации тоже постигла былинная неудача, то даже здесь мы не бросим его на произвол судьбы. Для этого случая мы ввели новую процедуру, которая называется Import Object Storage. Она позволяет пропустить процесс воссоздания вручную SOBR репозитория и прикрепления к нему капасити тира с последующим ресканом, а просто добавить обжект сторадж в интерфейс вима и запустить Import Storage Repository процедуру. Единственное, что может встать на пути между вами и вашими бекапами — это просьба ввести пароль, если ваши бекапы были зашифрованы.
На этом про Copy Mode, пожалуй, всё и мы переходим к
Sealed Mode
Основная задумка — на выбранном экстенте SOBR репозитория не могут появляться новые бекапы. До v10 у нас был только Maintenance Mode, когда полностью запрещалась любая работа с репозиторием. Этакий хардкорный режим вывода хранилища из работы, где доступна только кнопка Evacuate, разово перевозившая бекапы на другой экстент.
А Sealed mode — это своеобразный “мягкий” вариант: мы запрещаем создавать новые бекапы и постепенно удаляем старые согласно выбранному ретеншн, но в процессе не теряем возможность восстанавливаться из хранящихся точек. Очень полезная штука, когда у нас или подходит к концу срок жизни железки и её надо будет заменить, или её просто надо освободить под что-то более важное, а брать и разово всё переносить некуда. Или нельзя удалить.
Соответственно, принцип работы довольно прост: надо запретить все write операции (появление новых данных), оставив read(ресторы) и delete(ретеншн).
Оба режима можно использовать одновременно, только надо учитывать, что у Maintenance приоритет выше.
В качестве примера рассмотрим SOBR, состоящий из двух экстентов. Предположим, первые четыре дня у нас создавались бекапы в режиме Forward Forever Incremental, а потом мы запечатываем экстент.Это ведёт к тому, что мы инициируем создание нового эктив фула на втором доступном экстенте. Если наш ретенш равен четырём, то когда вся цепочка, расположенная на запечатанном экстенте, выйдет за его пределы, она со спокойной совестью удаляется.
Есть ситуации, когда удаление происходит раньше. Например, это Forward incremental с периодическими фулами. Если первые два дня у нас создавались фул бекапы, а в четверг мы решаем запечатать репозиторий, то в пятницу, когда создастся новый фульник, то файл за понедельник будет удалён т.к. к этой точке нет зависимостей. И сама точка ни от кого не зависит. После чего мы дожидаемся когда будут созданы четыре точки на доступном экстенте и удаляем оставшиеся три, которые не могут быть удалены независимо друг от друга.
Проще дела обстоят с Reverse Incremental. В нём самые старые точки ни от чего не зависят и могут быть спокойно удалены. Поэтому, как только будет создан новый .vbk на новом экстенте, старые .vrb будут по одному удаляться.
Кстати, почему мы каждый раз создаём новый .vbk: если его не создавать, а продолжать старую цепочку инкрементов, то старый .vbk подвисал бы на бесконечно долгое время в любом режиме, препятствуя его удалению. Поэтому было принято решение, что как только запечатывается экстент, мы создаём фул бекап на свободном экстенте.
Сложнее дела обстоят с капасити тиром.
Сначала рассмотрим copy mode. Предположим, что у нас четыре дня активно создавались бекапы, а потом капасити тир был запечатан. Мы ничего не удаляем, а смиренно выдерживаем ретеншн, после чего удаляем данные с капасити тира.
Примерно то же самое происходит при move mode — выжидаем ретенш, удаляем старое в локальном хранилище, удаляем хранящееся в обжект сторадже.
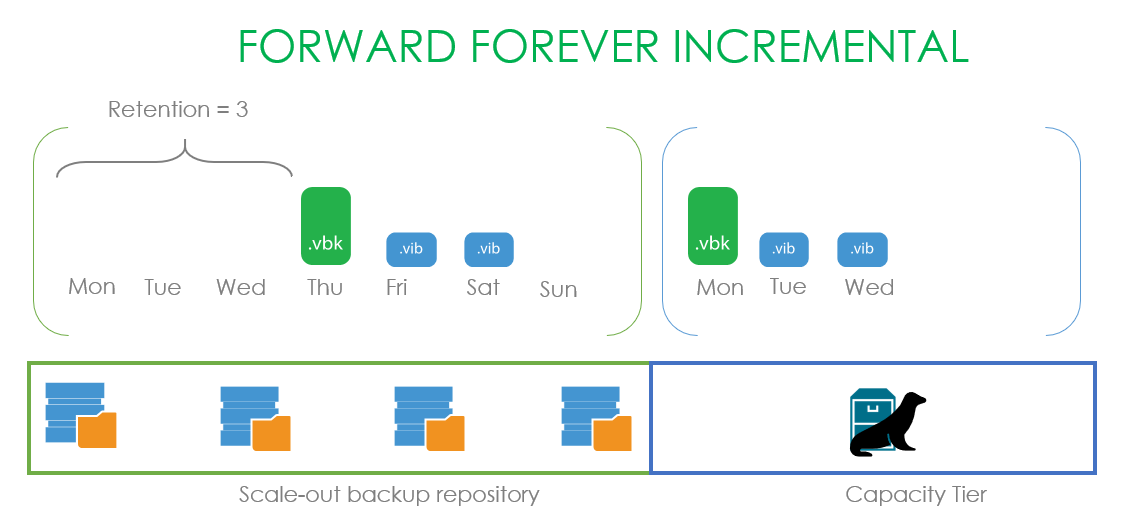
Интересный пример с Forever forward incremental. Устанавливаем ретенш в три точки и начинаем с понедельника делать бекапы, которые исправно копируются в облако. После запечатывания хранилища бекапы продолжают создаваться, выдерживая три точки, но хранящиеся в капасити тире данные остаются зависимыми и не могут быть удалены. Поэтому мы дожидаемся четверга, когда наш .vbk выходит за рамки ретеншн, и только тогда спокойно удаляем всю сохранённую цепочку.
И небольшая оговорка: все примеры здесь показаны с одной машиной. Если у вас в бекапе их несколько, то ретенш у них будет отличаться в зависимости от того, был сделан Active Full или нет.
На этом, в принципе, и всё. Так что переходим к самой хардкорной фиче —
Immutability
Как и с предыдущими пунктами, первым делом о том, какую проблему решает эта функция. Как только мы выгружаем куда-то наши бекапы на хранение, возникает острое желание гарантировать их сохранность, то есть физически запретить их удаление и любую модификацию в течении заданного ретеншена. В том числе админами, в том числе под их рутовыми учётками. Это позволяет защитить их от случайной или преднамеренной порчи. Кто работает с AWS, мог встречать подобную функцию под названием Object Lock.
Теперь рассмотрим режим в общих словах, а потом углубимся в детали. В нашем примере Immutability будет включен для нашего капасити тира с ретенш в четыре дня. А в бекапе включен режим Copy.
Immutability никак не взаимодействует с общим ретеншном. Например, он не добавляет дополнительных точек или что-то такое. Просто в течение четырёх дней человек не может удалить файлы бекапов. Если в понедельник сделать бекап, то удалить его файл получится только в пятницу.
Все ранее объяснённые концепты дегидрации, индексов и метаданных продолжают работать точно так же. Но с одним условием — блок выставляется не только для данных, но и на метаданные. Это сделано на случай, если коварный злоумышленник решит стереть нашу базу метаданных и чтобы блоки с данными не превратились в бесполезную бинарную кашу.
И теперь настал отличный момент для объяснения нашей технологии поколения блоков. Или block generation. Для этого рассмотрим ситуацию, которая привела к её появлению.
Возьмём временную шкалу в шесть дней и снизу будем отмечать время ожидаемого истечения immutability. Берём и создаём в первый день файл, состоящий из блока данных а, и его метаданные. Если immutability установлен в три дня, логично предположить, что на четвёртый день данные будут разлочены и удалены. На второй день добавим новый file2, состоящий из блока b с теми же настройками. Блок а всё ещё должен быть удалён на четвёртый день. Но на третий день случается страшное — создаётся файл File3, состоящий из нового блока d и ссылки на старый блок а. Это значит, что для блока а его immutability флаг должен быть перевыставлен на новый срок, который сдвигается на шестой день. И тут возникает проблема — в реальных бекапах таких блоков возникает огромное количество. А чтобы продлить им immutability период, надо каждый раз совершать огромное количество запросов. И фактически это будет около-бесконечный ежедневный процесс, так как с большой долей вероятности мы при каждом копировании будем находить здоровенные пачки дедуплицированных блоков. А что значит большое количество запросов у провайдеров обжект стораджей? Правильно! Огромный счёт в конце месяца.
И чтобы не выставлять на ровном месте на солидные деньги своих любимых клиентов, был придуман механизм block generation. Это дополнительный период, который мы добавляем к выставленному периоду immutability. В примере ниже такой период равняется двум дням. Но это только для примера. В реальности там используется своя формула, дающая примерно десять дополнительных дней при месячном локе.
Продолжим рассматривать туже ситуацию, но уже с block generation. Создаём в первый день file1 из блока а и метаданных. Складываем период поколений и immutability — значит, возможность удалить файл будет на шестой день. Если на второй день мы создадим File2, состоящий из блока b и ссылки на блок а, то с предполагаемой датой удаления ничего не происходит. Она как стояла на шестой день, так и стоит. А мы тем самым пытаемся экономить деньги на количестве запросов. Единственная ситуация, когда срок может быть сдвинут, это если generation period истёк. То есть, если на третий день новый File3 будет содержать ссылку на блок а, то будет добавлен generation 2 так как Gen1 уже истёк. А ожидаемая дата удаления блока а сместится на восьмой день. Это позволяет нам драматически снизить количество запросов на продление времени жизни дедуплицированных блоков, что экономит вагон денег клиентам.
Сама технология доступна пользователям S3 и S3-совместимого железа, производители которого гарантируют, что их реализация не отличается от амазоновской. Отсюда ответ на законный вопрос, почему не поддерживается Azure — у них есть схожая фича, но она работает на уровне контейнеров, а не отдельных объектов. Кстати, в самом амазоне обжект лок есть в двух режимах: compliance и governance. Во втором случае остаётся возможность, чтобы самый великий админ над админами и рут над рутами, несмотря на обжект лок, всё же удалил данные. В случае compliance всё прибито гвоздями намертво и бекапы не удалить никому. Даже у админов амазона (по их официальным заявлениям). Мы поддерживаем именно этот режим.
И, традиционно, немного полезных ссылок:
- Про Block Generation во всех подробностях.
- Вся информация про Veeam Backup & Replication 10 в лучшем виде
- О Capacity Tier в деталях
