
Мы уже писали про возможность создания сценариев с распознаванием речи, но тогда функционал данной системы был несколько ограничен. Не так давно компания Google открыла доступ к системе распознавания речи. И мы, конечно же, этим воспользовались. Многие компании реализуют разные сценарии взаимодействия со своими клиентами с помощью Voximplant. Автоматизация с помощью распознавания речи и поиск в уже распознанном позволяют бизнесу тратить меньше сил на ручную работу и больше — на то, что действительно важно. Далее мы подробно расскажем про несколько основных кейсов, ради которых делали интеграцию, и про проблемы, с которыми столкнулись в процессе, а также приведем несколько примеров использования нового функционала.
Freeform — это сложно
Начнем с того, что freeform распознавание — это очень сложная техническая задача. Если на ограниченном словаре (например, адреса) получить качество распознавания в 90+% реально, то в случае freeform это уже практически недостижимая на сегодняшний день планка. Одно дело, когда человек что-то диктует, то есть на выходе получается структурированный текст. И совсем другое – телефонный разговор, где при общении возникает миллион дополнительных моментов, ухудшающих качество распознавания: от банальных междометий, кашля и индивидуальных особенностей речи до шумов, потерь пакетов и других, имеющих самую разную природу. К тому же распознавание в реальном времени требует достаточно приличных вычислительных мощностей, а нам нужно, чтобы все это хорошо масштабировалось и было доступно из облака. Можем вас заверить, что мы много и долго тестировали самые разнообразные решения для freeform распознавания. Каждый раз где-то чего-то не хватало, поэтому когда коллеги из Google анонсировали свое распознавание, мы с радостью побежали его тестировать.
Возможности Google Cloud Speech API
В настоящий момент Google Cloud Speech API находится в состоянии открытой беты. Существует ряд ограничений по количеству и скорости запросов, которые можно ему скармливать. Предлагается несколько вариантов работы с API: синхронный режим, асинхронный режим и стриминг. Синхронный режим позволяет отправлять куски аудио данных длительностью до минуты и на запрос возвращает ответ с результатом распознавания. Асинхронный режим позволяет обрабатывать большие файлы, но для этого их нужно загружать в Google Cloud Storage. Стриминг позволяет передавать данные частями и получать результат распознавания в реальном времени, то есть хорошо подходит для dictation и IVR. По аудио формату — 8/16 KHz. Поддерживается ряд разных кодеков в зависимости от режима: ulaw, flac, amr или просто PCM. Вендор рекомендует использовать 16 KHz и не использовать дополнительную обработку сигнала – это только ухудшает качество распознавания. Наш опыт показал, что нюансов, на самом деле, сильно больше. Например, лучше не пытаться распознавать куски длительностью более 20 секунд, если кусок слишком маленький, то можно на выходе не получить результат и т.д. Многие из этих проблем – следствие бета-версии. Думаем, что их поправят к релизу.
Кейс №1: Транскрибирование
Одним из самых востребованных кейсов является распознавание записей разговоров. Наверное, не нужно долго объяснять, почему это такая полезная функция. Поиск в тексте сильно проще поиска в аудио, поэтому любого рода анализ будет после преобразования в текст ускорен и упрощен. Для включения транскрибирования необходимо в функцию записи передать дополнительный параметр transcribe:
require(Modules.ASR);
//..
call.record({language: ASRLanguage.RUSSIAN_RU, transcribe: true, stereo: true});
//...
Все сценарии обработки вызовов в Voximplant пишутся на JavaScript, поэтому тут все достаточно прозрачно. Данный код говорит, что после окончания записи будет необходимо отправить данные в специальную подсистему, которая займется взаимодействием с Google Speech API. И через какое-то время в истории звонков в дополнение к записи появится текстовый файл с результатами распознавания. Результат будет выглядеть так:
Left 00:00:00 - 00:00:03 : <Unrecognized>
Right 00:00:00 - 00:00:35 : Здравствуйте Вас приветствует центр информационной поддержки Филипс Для более эффективного обслуживания пожалуйста будьте готовы назвать модель Вашего аппарата Спасибо вы находитесь в главном меню для получения информации о поддержки телевизоров Philips нажмите 1 по вопросам поддержки мобильных телефонов Philips нажмите 2 аудио видео техники а также беспроводных и проводных телефонов Philips нажмите 3 малой бытовой техники и других продуктов Philips нажмите 4
Right 00:00:38 - 00:01:18 : вы находитесь в главном меню для получение информации о поддержки телевизоров Philips нажмите 1 по вопросам поддержки мобильных телефонов Philips нажмите 2 аудио видео техники а также беспроводных и проводных телефонов Philips нажмите 3 малой бытовой техники и других продуктов Philips нажмите 4 соединение с консультантом означает ваше согласие на обработку компании Philips предоставляемых вами персональных данных попросил вашего внимания что в целях улучшения качества обслуживания разговор может быть записан
Left 00:01:05 - 00:01:44 : Алло добрый день а можете подсказать nanosuit кофемашина Saeco вот и она из-за таких непонятные звуки Понятно Что мне там гарантии уже давным давно закончилась. От производителя лучше можно как-то через вызвать телемастера там специалиста чтобы он посмотрел что в итоге сне
Right 00:01:20 - 00:02:01 : Прости меня зовут Иван Я представляю компанию Philips буду рад вам помочь мастер приезжает если только в случае это есть машина на гарантии Вы можете обратиться именно в сервисный центр чтобы починить возможности данной услуги Подскажите город из которого вращается
Left 00:01:49 - 00:02:33 : Москва Давайте номер продиктую x xxx xxxx
Right 00:02:07 - 00:02:30 : я могу направить на ваш номер телефона контакты сервисных центров в Москве в них будет указан номер телефона Вы можете позвонить и уточнить информацию до записываем 125
Right 00:02:32 - 00:03:17 : 66 67 включение 2 минут ожидайте отправлю на сервисный центр Подскажите даже Позвони буквально минуту временная регистрация обращений регистрации позволю быстрее оказать вам поддержку при повторном обращении с представительством будет удобно фамилия имя отчество и адрес электронной почты если используете хорошо это по вашему желанию. При повторном обращении называется пожалуйста номер Вашего телефона ускорит решение ваших вопросов
Left 00:02:34 - 00:03:14 : Ага хорошо спасибо Рыжкова Юлия Германовна мне очень длинной
Left 00:03:14 - 00:03:26 : Ладно хорошо спасибо до свидания
Right 00:03:17 - 00:03:25 : Спасибо вам также что выбрали Philips Мы работаем чтобы получали удовольствие от нашей продукции всё доброе
К сожалению, пока API не выдает timestamps при распознавании, поэтому нельзя максимально точно разбить по времени, что и когда было сказано. Но даже так это очень хорошо.
Кейс №2. IVR
Ключевое слово «автоматизация». Сейчас только ленивый не пишет и не рассказывает про то, как изменится мир благодаря machine learning, AI и так далее. Наверное, мы не со всем согласны в этих рассказах. Особенно про AI. Но то что автоматизация позволяет ускорить и улучшить ряд процессов, мы отлично знаем, так как активно предлагаем нашим клиентам автоматизировать процессы взаимодействия с их клиентами, на которые нужно раньше было тратить дорогое время сотрудников. Интеллектуальные IVRы с распознаванием речи будут лавинообразно распространяться в ближайшем будущем именно благодаря прогрессу в machine learning и в распознавании речи. В США, если вы позвоните в Department of Motor Vehicles, вас ждет долгое и увлекательное общение с их IVR, где попасть на живого человека практически невозможно. Максимум – можно попросить перезвонить вам позже. Если повезет, где-нибудь на следующей неделе. Мы не считаем, что такой уж крайний вариант – это правильно. Все-таки нужно давать возможность людям попасть на живого человека, если общение не складывается. Но тренд уже давно понятен.
В случае Voximplant у нас уже давно есть возможность такие сценарии реализовывать. Раньше точность распознавания в отдельных случаях была недостаточной. В случае API от Google можно задавать speech_context, что позволяет реализовывать сценарий с выбором из заранее заданного списка фраз и вариантов. Причем если человек скажет что-то не из контекста, то распознавание все равно сработает. Но если он скажет что-то из контекста, то оно сработает с гораздо более высокой точностью. Воспользоваться этой функцией в сценарии VoxEngine можно следующим образом:
require(Modules.ASR);
//..
mycall.say("скажите фразу", Language.RU_RUSSIAN_FEMALE);
mycall.addEventListener(CallEvents.PlaybackFinished, function (e) {
mycall.sendMediaTo(myasr);
});
//...
var myasr = VoxEngine.createASR(
ASRLanguage.RUSSIAN_RU,
["да", "нет", "верно", "все верно", "не верно"]);
myasr.addEventListener(ASREvents.Result, function (e) {
if (e.confidence > 0) mycall.say("фраза " + e.text + " достоверность " + e.confidence, Language.RU_RUSSIAN_FEMALE);
else mycall.say("не удалось распознать фразу", Language.RU_RUSSIAN_FEMALE);
});
myasr.addEventListener(ASREvents.SpeechCaptured, function (e) {
mycall.stopMediaTo(myasr);
});
//...
Кейс №3. Стриминг
По некоторым техническим причинам, связанным с работой самого бэкенда от Google, нам пришлось прилично пошаманить для реализации стриминг-режима. Надеемся, в ближайшем будущем такая необходимость отпадет. Итак, чтобы распознавать целый разговор в реальном времени (или просто большие части речи) потребуется модифицировать сценарий:
require(Modules.ASR);
var full_result = "", ts;
//..
mycall.say("скажите фразу", Language.RU_RUSSIAN_FEMALE);
mycall.addEventListener(CallEvents.PlaybackFinished, function (e) {
mycall.sendMediaTo(myasr);
});
//...
// Убираем словарь - пусть будет чистый freeform (его всегда можно добавить при необходимости)
var myasr = VoxEngine.createASR(ASRLanguage.RUSSIAN_RU);
myasr.addEventListener(ASREvents.Result, function (e) {
// Сюда будут прилетать события распознавания как и раньше
full_result += e.text + " ";
// Если за 5 секунд не случится CaptureStarted, то можно останавливаться
ts = setTimeout(recognitionEnded, 5000);
});
myasr.addEventListener(ASREvents.SpeechCaptured, function (e) {
// После захвата фразы не выключаем отправку данных на распознавание
/*mycall.stopMediaTo(myasr);*/
});
myasr.addEventListener(ASREvents.CaptureStarted, function() {
// Если пришло событие о начале распознавания сбрасываем таймаут
clearTimeout(ts);
});
function recognitionEnded() {
// Останавливаем распознавание
myasr.stop();
}
//...
Хочется отметить один нюанс: событие CaptureStarted возникает на основании фидбэка от API Google. Там сейчас VAD достаточно добрый, и эти события могут возникать не только на речь, но и на фоновый шум. Для того чтобы точно знать, когда пора останавливать распознавание в стриминг режиме при молчании, можно в дополнение использовать наш встроенный VAD:
mycall.handleMicStatus(true);
mycall.addEventListener(CallEvents.MicStatusChange, function(e) {
if (e.active) {
// пошел голос
} else {
// прекратился голос
}
});
Демо
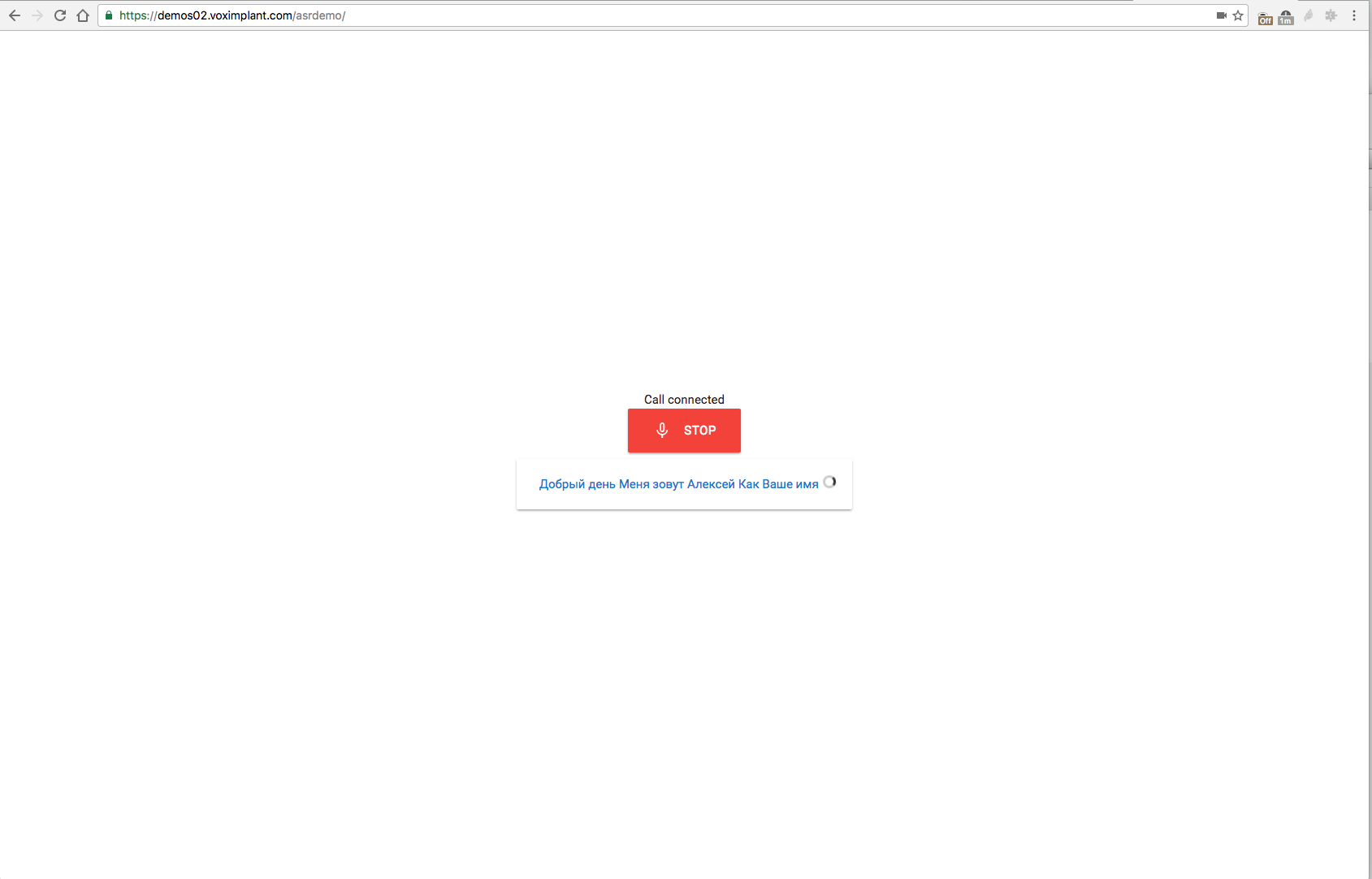
Было бы странным не дать вам потестировать все это хозяйство без лишних телодвижений (хотя мы, конечно, очень рекомендуем начать разрабатывать с помощью Voximplant :) Демо доступно по адресу https://demos02.voximplant.com/asrdemo/. Понадобится браузер с поддержкой WebRTC / ORTC (Chrome/Firefox/Edge) и микрофон. Исходники этого чудо-демо доступны на Gist.
