При разработке продукта редко обращают должное внимание на его производительность при высокой интенсивности входящих запросов. Этим занимаются мало или не занимаются вообще – не хватает времени, специалистов или оправдываются типичной фразой: «У нас на проде и так всё быстро работает, зачем ещё что-то проверять?». В таких случаях может наступить момент, когда прекрасно работающий продакшн внезапно падает из-за нахлынувшего потока посетителей, например, под Хабраэффектом. Тогда становится ясно, что заниматься исследованиями производительности действительно необходимо.
Эта задача многих ставит в тупик, поскольку есть потребность, но нет ясного понимания, что и как надо измерять и как интерпретировать результат, порой даже нет сформированных нефункциональных требований. Далее я расскажу о том, с чего стоит начать, если вы решили пойти по этому пути, и объясню, какие метрики важны при исследовании производительности, и как ими пользоваться.
Немного теории
Представим, что у нас есть сферическое приложение в вакууме – оно получает запросы и отдаёт на них ответы. Для простоты, это может быть микросервис с одним методом, который никуда не ходит и не зависит от других компонент или приложений. В данном случае нас мало интересует то, на чём он написан, как именно работает и в каком окружении запущен.
Что мы вообще хотим знать о производительности? Наверное, хорошо знать максимальный поток входящих запросов, при котором сервис работает стабильно, его производительность при этом потоке и время, которое тратится на выполнение одного запроса. Совсем хорошо, если получится определить причины, которые ограничивают дальнейший рост производительности.
Очевидно, что измерять надо время ответа на запрос, соответственно под потоком входящих запросов или интенсивностью будет пониматься количество запросов в единицу времени, как правило, за секунду, а под производительностью – количество ответов в эту же единицу времени. Времена ответов могут быть разбросаны в широком диапазоне, поэтому для начала имеет смысл их представить в виде среднего за секунду.
Кроме того, на самых различных уровнях могут возникать проблемы: начиная с того, что сервис отвечает ошибкой (и хорошо, если это пятисотка, а не «200 ОК {"status": "error"}»), и заканчивая тем, что он перестает отвечать вообще или ответы начинают теряются на уровне сети. Неудачные запросы нужно уметь отлавливать, и их удобно представлять в виде процента от общего количества. График зависимости производительности, времени ответа и процента ошибок от интенсивности выглядит примерно так:
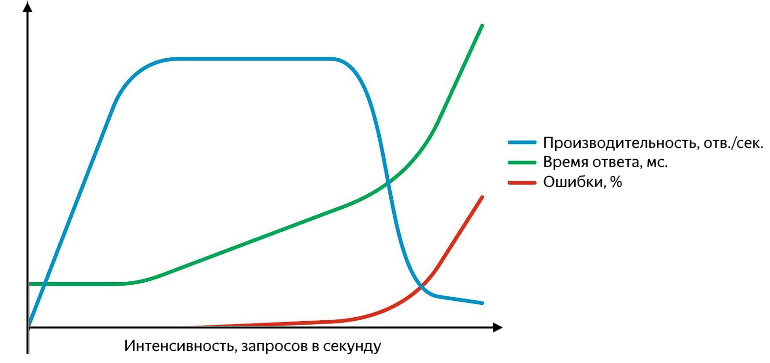
С ростом интенсивности запросов увеличиваются время ответа и процент ошибок
Пока производительность растёт в линейной зависимости от интенсивности – у сервиса всё в полном порядке. Он успешно обрабатывает весь входящий поток запросов, время ответа при этом не меняется, ошибок нет. Продолжая увеличивать интенсивность, получим замедление роста производительности до момента насыщения, в котором производительность достигает своего максимума и начинает расти время ответа. Последующее увеличение интенсивности приведёт к разладке – существенному увеличению времени ответа и падению производительности, начнётся активный рост ошибок. На этапе роста и насыщения имеются две важные точки – нормальная и максимальная производительность.
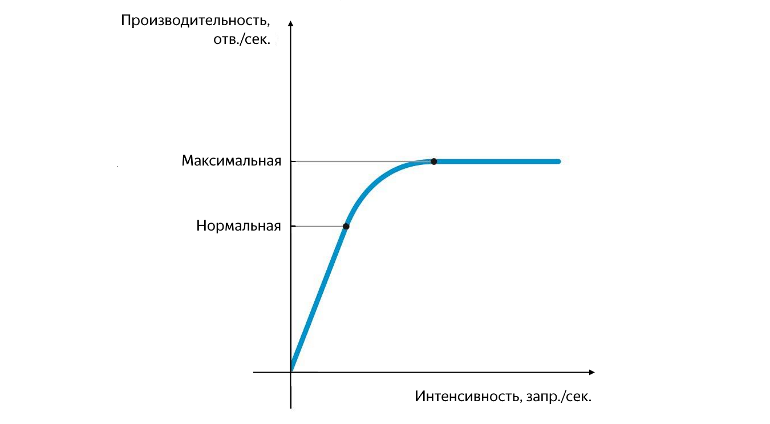
Положение нормальной и максимальной производительности
Нормальная производительность достигается в момент, когда начинает уменьшаться скорость её роста, а максимальная – в момент, когда скорость её роста обращается в ноль. Разделение производительности на нормальную и максимальную очень важно. При интенсивности, которая соответствует нормальной производительности, приложение должно работать стабильно, а значение нормальной производительности характеризует порог, после которого начинает проявляться узкое место (bottleneck) сервиса, оказывая отрицательное влияние на его работу. При достижении максимальной производительности узкое место начинает полностью ограничивать дальнейший рост, работа сервиса нестабильна, и, как правило, в этот момент начинает появляться хоть и маленький, но стабильный фон ошибок.
Проблема может быть вызвана разными причинами – забились очереди, недостаточно потоков, исчерпан пул, полностью утилизирован ЦПУ или ОЗУ, недостаточная скорость чтения/записи с диска и тому подобное. Важно понимать, что исправление одного узкого места приведёт к тому, что производительность будет ограничена со стороны следующего и так далее. Полностью избавиться от узкого места нельзя, его можно только перенести.
Эксперименты
В первую очередь необходимо определить величину интенсивности, при которой сервис достигает нормальной и максимальной производительности, и соответствующее им среднее время ответа. Для этого в эксперименте достаточно просто увеличивать поток входящих запросов. Сложнее определиться со значением максимальной интенсивности и временем проведения эксперимента.
Можно отталкиваться от того, что написано в нефункциональных требованиях (если они есть), от максимальной пользовательской нагрузки с прода или просто брать значения с потолка. Если интенсивности входящего потока будет недостаточно – сервис не успеет выйти на насыщение и надо будет повторять эксперимент. Если же интенсивность будет слишком высокой – сервис очень быстро достигнет насыщения, а затем и разладки. На такой случай удобно иметь мониторинг, чтобы при существенном увеличении количества ошибок не тратить время зря и остановить эксперимент.
В своих экспериментах мы плавно увеличиваем интенсивность от 0 до 1000 запросов в секунду в течение 10 минут. Этого достаточно, чтобы сервис достиг насыщения, а потом, если нужно, корректируем время и величину интенсивности в следующем эксперименте, чтобы получить более точный результат. На графиках выше всё было плавно и красиво, но в реальном мире бывает сложно с первого взгляда определить значение нормальной производительности.
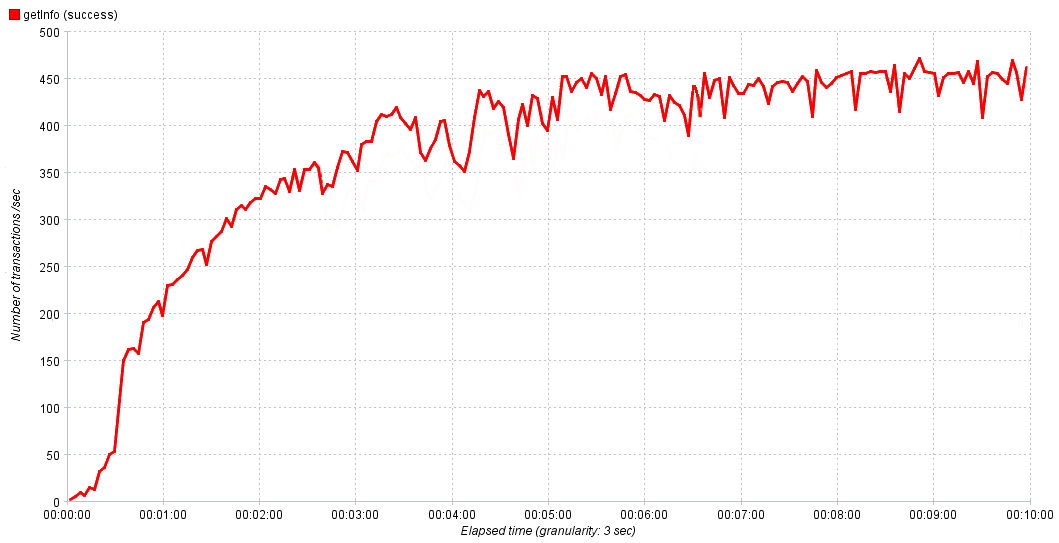
Реальная зависимость производительности сервиса от времени
Мы в таком случае за нормальную производительность принимаем 80-90% от максимальной. Если после выхода на насыщение наблюдаем активный рост ошибок – имеет смысл их исследовать, потому что они являются следствием узкого места, их изучение поможет его локализовать и передать на исправление.
Итак, первые результаты получены. Теперь известна нормальная и максимальная производительность приложения, а также времена ответов, соответствующие им. На этом всё? Конечно, нет! При нормальной производительности сервис должен работать стабильно, а значит, надо проверить его работу при нормальной нагрузке некоторое время. Какое? Можно опять посмотреть в нефункциональных требованиях, спросить у аналитиков или помониторить длительность периодов максимальной активности на проде. В своих экспериментах мы линейно увеличиваем нагрузку от 0 до нормальной и выдерживаем на ней в течение 10-15 минут. Этого достаточно, если максимальная пользовательская нагрузка существенно меньше нормальной, но если они сопоставимы, время эксперимента надо увеличить.
Чтобы быстро оценить результат эксперимента, удобно провести агрегацию полученных данных в виде следующих метрик:
- среднее время ответа,
- медиана,
- 90% перцентиль,
- % ошибок,
- производительность.
Что такое среднее время ответа понятно, однако среднее является адекватной мерой только в случае нормального распределения выборки, поскольку оно слишком чувствительно к «выбросам» – слишком большим или слишком малым значениям, которые сильно выбиваются из общей тенденции. Медиана же является серединой всей выборки времён ответов, половина значений меньше неё, остальная больше. Зачем она нужна?
Во-первых, исходя из её определения, она менее чувствительна к выбросам, то есть является более адекватной метрикой, а во-вторых, сравнивая её со средним, можно быстро оценить характеристику распределения ответов. В идеальной ситуации они равны – распределение времён ответов нормальное, и у сервиса всё прекрасно!
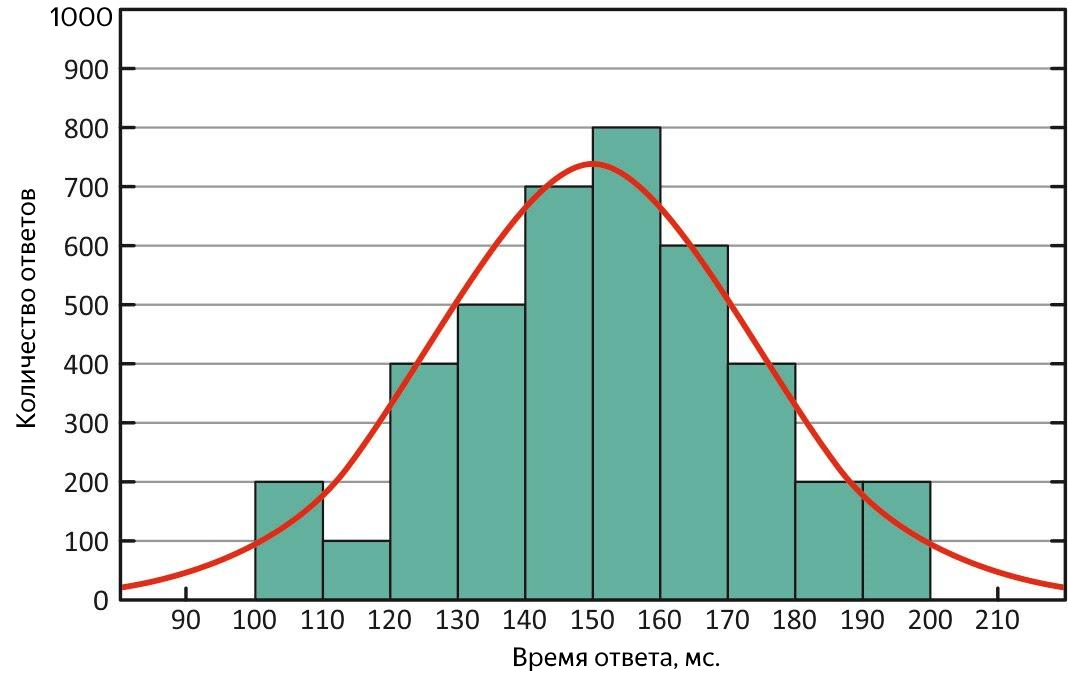
Нормальное распределение времён ответов. При таком распределении среднее и медиана равнозначны
Если среднее сильно отличается от медианы, значит, распределение перекошено, и по ходу эксперимента могли присутствовать «выбросы». Если среднее больше – были периоды, когда сервис отвечал очень медленно, проще говоря, тормозил.
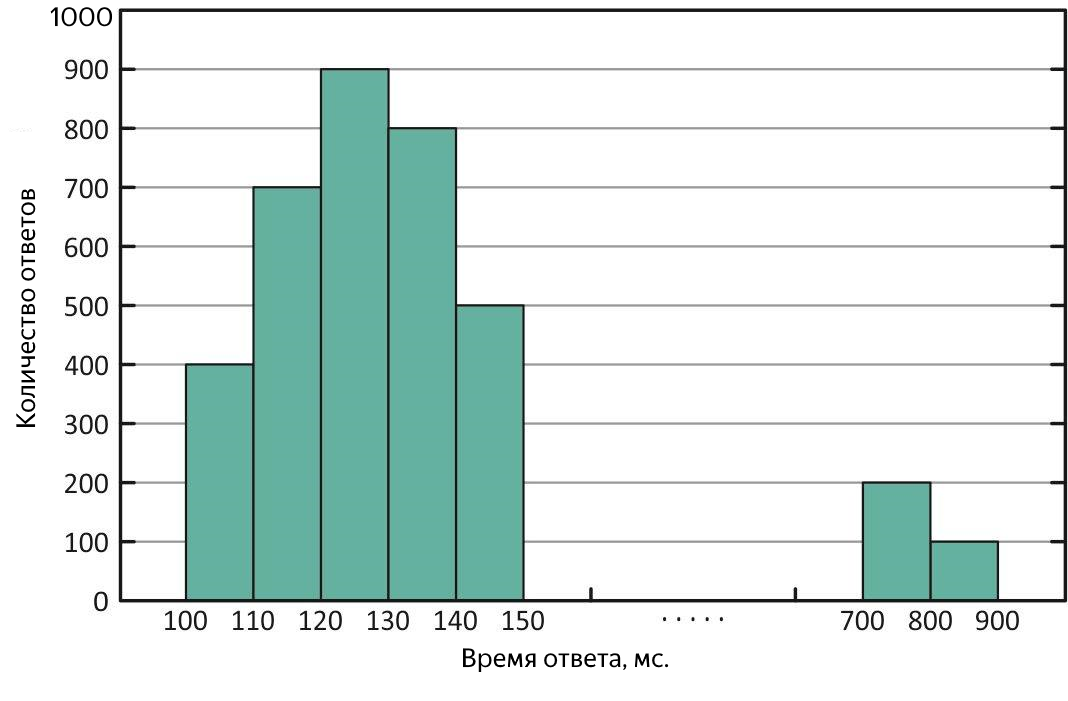
Распределение времён ответа с «выбросами» долгих ответов. При таком распределении среднее больше медианы.
Такие случаи требуют дополнительного разбора. Для оценки масштаба «выбросов» на помощь приходят квантили или перцентили.
Квантиль, в контексте полученной выборки, это значение времени ответа, до которого укладывается соответствующая часть всех запросов. Если используется % от запросов, то это перцентиль (кстати, медиана является 50% перцентилем). Для оценки «выбросов» удобно пользоваться 90% перцентилем. К примеру, в результате эксперимента была получена медиана в 100 мс, а среднее – 250 мс, превышает медиану в 2,5 раза! Очевидно, что это не совсем хорошо, смотрим на 90% квантиль, а там 1000 мс – целых 10% от всех удачных запросов выполнялись более секунды, непорядок, надо разбираться. Для поиска долгих запросов можно грепнуть по файлу с результатами эксперимента или сразу по логам сервиса, но ещё лучше представить среднее время ответа в виде графика зависимости от времени, на нём сразу будет видно и время, и характер имеющихся «выбросов».
Итоги
Итак, вы успешно провели эксперименты и получили результаты. Хороший это результат или плохой, зависит от требований, которые предъявляются к сервису, но намного важнее не полученные числа, а то, почему эти числа такие, и понимание, чем ограничивается дальнейший рост. Если у вас получилось найти узкое место – очень хорошо, если нет, то рано или поздно потребность в производительности может возрасти, и его всё равно придётся искать, поэтому иногда проще упредить ситуацию.
В этой заметке я дал базовый подход к исследованию производительности, ответив на вопросы, которые возникали у меня в самом начале. Не бойтесь исследовать производительность, это необходимо!
P.S.
Заходите в наш уютный телеграм-чатик, где можно задать вопросы, помочь советом и просто пообщаться тему исследований производительности.
