
Пост подготовили: Александр Вирилин xscrew — автор, руководитель службы сетевой инфраструктуры, Леонид Клюев — редактор
 Мы продолжаем знакомить вас с внутренним устройством Яндекс.Облака. Сегодня поговорим о сетях — расскажем, как устроена сетевая инфраструктура, почему в ней активно применяется непопулярная для дата-центров парадигма MPLS, какие ещё сложные решения нам приходилось принимать в процессе построения облачной сети, как мы ей управляем и какие мониторинги используем.
Мы продолжаем знакомить вас с внутренним устройством Яндекс.Облака. Сегодня поговорим о сетях — расскажем, как устроена сетевая инфраструктура, почему в ней активно применяется непопулярная для дата-центров парадигма MPLS, какие ещё сложные решения нам приходилось принимать в процессе построения облачной сети, как мы ей управляем и какие мониторинги используем.
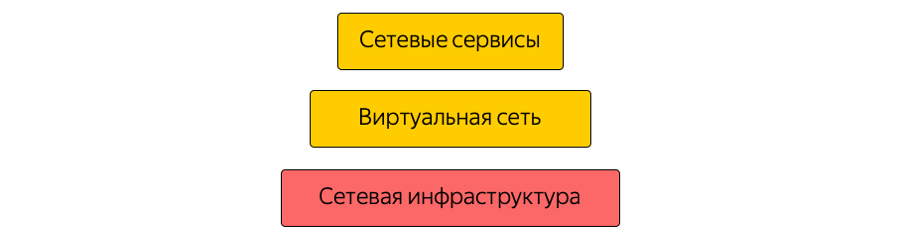
Сеть в Облаке состоит из трёх слоёв. Нижний слой — уже упомянутая инфраструктура. Это физическая «железная» сеть внутри дата-центров, между дата-центрами и в местах присоединения к внешним сетям. Поверх сетевой инфраструктуры строится виртуальная сеть, а поверх виртуальной сети — сетевые сервисы. Эта структура не является монолитной: слои пересекаются, виртуальная сеть и сетевые сервисы напрямую взаимодействуют с сетевой инфраструктурой. Поскольку виртуальную сеть часто называют overlay, то сетевую инфраструктуру мы обычно называем underlay.
Сейчас инфраструктура Облака базируется в Центральном регионе России и включает в себя три зоны доступности — то есть три географически распределенных независимых дата-центра. Независимые — не зависящие друг от друга в контексте сетей, инженерных и электрических систем и т. д.
О характеристиках. География расположения дата-центров такова, что время приема-передачи в оба конца между ними (round-trip time, RTT) всегда составляет 6–7 мс. Суммарная емкость каналов уже перевалила за 10 терабит и постоянно наращивается, потому что Яндекс обладает собственной волоконно-оптической сетью между зонами. Поскольку мы не арендуем каналы связи, то можем оперативно наращивать ёмкость полосы между ДЦ: в каждом из них используется оборудование спектрального уплотнения.
Вот максимально схематичное представление зон:

Реальность, в свою очередь, немного другая:
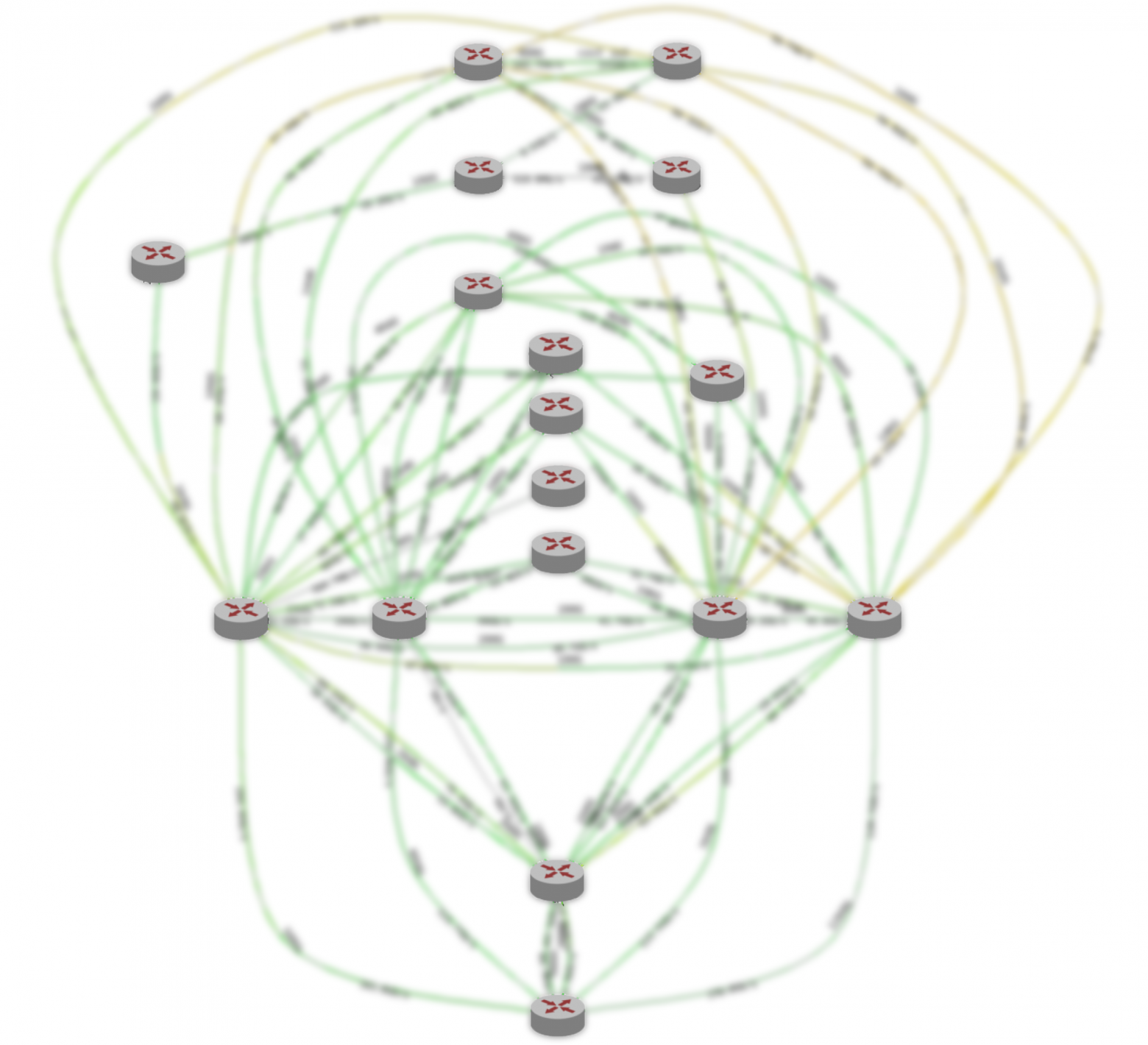
Здесь изображена текущая опорная сеть Яндекса в регионе. Поверх неё работают все сервисы Яндекса, часть сети используется Облаком. (Это картинка для внутреннего пользования, поэтому сервисная информация сознательно скрыта. Тем не менее, можно оценить количество узлов и соединений.) Решение задействовать опорную сеть было логичным: мы могли ничего не изобретать, а переиспользовать текущую инфраструктуру — «выстраданную» за годы развития.
В чем отличие между первой картинкой и второй? В первую очередь, зоны доступности не связаны между собой напрямую: между ними расположены технические площадки. Площадки не содержат серверного оборудования — на них размещаются только сетевые устройства по обеспечению связности. К техническим площадкам подключаются точки присутствия, где происходит стыковка Яндекса и Облака с внешним миром. Все точки присутствия работают на весь регион. Кстати, важно отметить, что с точки зрения внешнего доступа из интернета все зоны доступности Облака равнозначны. Другими словами, они обеспечивают одинаковую связность — то есть одну и ту же скорость и пропускную способность, а также одинаково низкие задержки.
Кроме того, на точках присутствия находится оборудование, к которому — при наличии on-premise-ресурсов и желании расширить локальную инфраструктуру облачными мощностями — могут подключиться клиенты по гарантированному каналу. Это можно сделать с помощью партнёров или самостоятельно.
Опорная сеть используется Облаком как MPLS-транспорт.
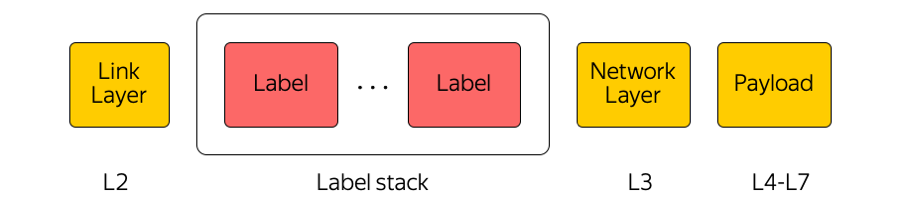
Multi protocol label switching (мультипротокольная коммутация по меткам) — крайне широко используемая в нашей отрасли технология. Например, когда какой-либо пакет передаётся между зонами доступности или между зоной доступности и интернетом, то транзитное оборудование обращает внимание только на верхнюю метку, «не думая» о том, что под ней. Таким образом MPLS позволяет скрыть сложность Облака от транспортного уровня. Вообще, мы в Облаке очень любим MPLS. Мы даже сделали её частью нижнего уровня и используем непосредственно на коммутационной фабрике в дата-центре:

(На самом деле между Leaf-свитчами и Spines огромное количество параллельных линков.)
MPLS и правда совсем не часто можно встретить в сетях дата-центров. Зачастую используются совсем другие технологии.
Мы используем MPLS по нескольким причинам. Во-первых, мы посчитали удобным унифицировать технологии control plane и data plane. То есть вместо одних протоколов в сети дата-центра, других протоколов в опорной сети и мест стыка этих протоколов — единый MPLS. Тем самым мы унифицировали технологический стек и снизили сложность сети.
Во-вторых, в Облаке мы используем различные сетевые appliances, например Cloud Gateway и Network Load Balancer. Им нужно коммуницировать между собой, отправлять трафик в интернет и наоборот. Эти сетевые appliances могут горизонтально масштабироваться при росте нагрузки, а поскольку Облако строится по модели гиперконвергентности, они могут быть запущены в абсолютно любом месте с точки зрения сети в дата-центре, то есть в общем пуле ресурсов.
Таким образом, эти appliances могут запуститься за любым портом стоечного свитча, где находится сервер, и начать общаться по MPLS со всей остальной инфраструктурой. Единственной проблемой в построении такой архитектуры была сигнализация.
Классический стек протоколов MPLS достаточно сложный. Это, кстати, является одной из причин нераспространённости MPLS в сетях дата-центров.
Мы, в свою очередь, не стали использовать ни IGP (Interior Gateway Protocol), ни LDP (Label Distribution Protocol), ни другие протоколы распространения меток. Используется только BGP (Border Gateway Protocol) Label-Unicast. Каждый appliance, который запускается, например, в виде виртуальной машины, строит сессию BGP до стоечного Leaf-свитча.
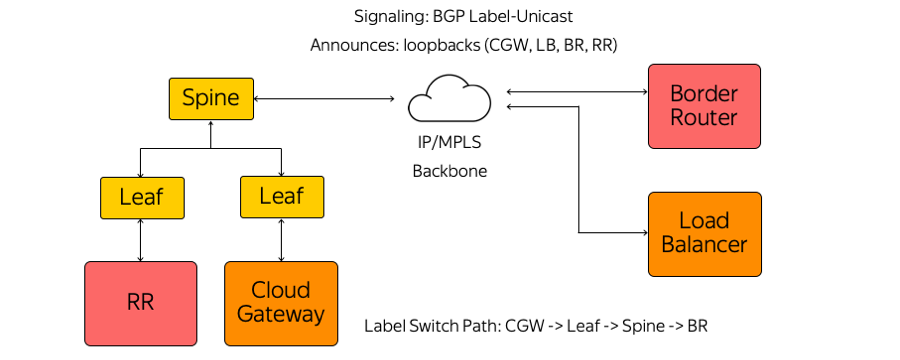
BGP-сессия строится по заранее известному адресу. Нет необходимости автоматически настраивать свитч под запуск каждого appliance. Все свитчи настроены заранее и единообразно.
В рамках сессии BGP каждый appliance отправляет свой loopback и получает loopbacks остальных устройств, с которыми ему нужно будет обмениваться трафиком. Примеры таких устройств — route reflectors нескольких видов, пограничные маршрутизаторы и другие appliances. В итоге на устройствах появляется информация о том, как им достичь друг друга. Из Cloud Gateway через Leaf-свитч, Spine-свитч и сеть до пограничного маршрутизатора строится Label Switch Path. Свитчи — это L3-коммутаторы, которые ведут себя как Label Switch Router и «не знают» об окружающей их сложности.
MPLS на всех уровнях нашей сети, помимо прочего, позволила нам использовать концепцию Eat your own dogfood.
C точки зрения сети эта концепция подразумевает, что мы живем в той же инфраструктуре, которую предоставляем пользователю. Здесь схематично изображены стойки в зонах доступности:
Cloud host принимает на себя нагрузку от пользователя, содержит его виртуальные машины. А буквально соседний хост в стойке может нести на себе инфраструктурную с точки зрения сети нагрузку, включающую в себя route reflectors, сервера менеджмента, мониторинга и т. д.
Для чего это было сделано? Существовал соблазн запускать route reflectors и все инфраструктурные элементы в отдельном отказоустойчивом сегменте. Тогда, если бы где-то в дата-центре сломался пользовательский сегмент, инфраструктурные сервера продолжили бы управлять всей сетевой инфраструктурой. Но нам такой подход показался порочным — если мы не доверяем собственной инфраструктуре, то как мы можем предоставлять её нашим клиентам? Ведь поверх неё работает абсолютно всё Облако, все виртуальные сети, пользовательские и облачные сервисы.
Поэтому мы отказались от отдельного сегмента. Наши инфраструктурные элементы запускаются в той же сетевой топологии и с той же сетевой связностью. Естественно, они запускаются в тройном экземпляре — подобно тому, как наши клиенты запускают в Облаке свои сервисы.
Вот примерная схема одной из зон доступности:

В каждой зоне доступности около пяти модулей, а в каждом модуле около сотни стоек. Leaf — стоечные свитчи, они внутри своего модуля связаны уровнем Spine, а межмодульная связность обеспечивается через сетевой Interconnect. Это следующий уровень, включающий в себя так называемые Super-Spines и Edge-свитчи, которые уже связывают между собой зоны доступности. Мы сознательно отказались от L2, речь идёт только про L3 IP/MPLS-связность. Для распространения маршрутной информации используется протокол BGP.
На самом деле параллельных соединений гораздо больше, чем на картинке. Такое большое количество соединений ECMP (Equal-сost multi-path) накладывает особые требования к мониторингу. Кроме того, возникают неожиданные, на первый взгляд, лимиты в оборудовании — например, количество ECMP-групп.

Яндекс за счёт мощных инвестиций строит сервисы таким образом, чтобы отказ одного сервера, серверной стойки, модуля или даже целого дата-центра никогда не приводил к полной остановке сервиса. Если у нас случаются какие-то сетевые проблемы — предположим, сломался стоечный свитч, — внешние пользователи этого никогда не видят.
Яндекс.Облако — особый случай. Мы не можем диктовать клиенту, как ему строить собственные сервисы, и решили нивелировать эту возможную единую точку отказа. Поэтому все сервера в Облаке подключаются к двум стоечным свитчам.
Мы точно так же не используем какие-либо протоколы резервирования на уровне L2, а сразу начали использовать только L3 с BGP — опять же, из соображения унификации протоколов. Такое подключение обеспечивает каждому сервису IPv4- и IPv6-связность: какие-то сервисы работают по IPv4, а какие-то — по IPv6.
Физически каждый сервер подключается двумя 25-гигабитными интерфейсами. Вот фото из дата-центра:

Здесь вы видите два стоечных свитча со 100-гигабитными портами. Видны расходящиеся breakout-кабели, делящие 100-гигабитный порт свитча на 4 порта по 25 гигабит на сервер. Мы называем такие кабели «гидра».
Сетевая инфраструктура Облака не содержит никаких проприетарных решений для управления: все системы или опенсорсные с кастомизацией под Облако, или полностью самописные.

Как происходит управление этой инфраструктурой? В Облаке не то чтобы запрещено, но крайне не приветствуется заходить на сетевое устройство и вносить какие-то корректировки. Существует текущее состояние системы, и нам нужно применить изменения: прийти к какому-то новому, целевому состоянию. «Пробежаться скриптом» по всем железкам, что-то изменить в конфигурации — так делать не стоит. Вместо этого мы вносим изменения в шаблоны, в единую систему source of truth и коммитим наше изменение в систему контроля версий. Это очень удобно, потому что всегда можно сделать rollback, посмотреть историю, узнать ответственного за коммит и т. д.
Когда мы внесли изменения, генерируются конфиги и мы их выкатываем на лабораторную тестовую топологию. С точки зрения сети это маленькое облако, которое полностью повторяет весь существующий продакшен. Мы сразу увидим, если желаемые изменения что-то ломают: во-первых, по мониторингам, а во-вторых, по фидбеку от наших внутренних пользователей.
Если мониторинги говорят, что всё спокойно, то мы продолжаем выкатку — но применяем изменение только к части топологии (две и более доступности «не имеют права» сломаться по одной и той же причине). Кроме того, мы продолжаем пристально следить за мониторингами. Это достаточно сложный процесс, о котором мы расскажем чуть ниже.
Убедившись, что всё хорошо, мы применяем изменение ко всему продакшену. В любой момент времени можно откатиться и вернуться к предыдущему состоянию сети, оперативно отследить и исправить проблему.
Нам нужны разные мониторинги. Один из самых востребованных — мониторинг End-to-End-связности. В любой момент времени каждый сервер должен иметь возможность покоммуницировать с любым другим сервером. Дело в том, что если где-то есть проблема, то мы хотим как можно раньше узнать, где именно (то есть какие сервера имеют проблемы с доступом друг к другу). Обеспечение End-to-End-cвязности — наша основная задача.
На каждом сервере перечислен набор всех серверов, с которыми он должен иметь возможность коммуницировать в любой момент времени. Сервер берёт случайное подмножество этого набора и отправляет на все выбранные машины ICMP-, TCP- и UDP-пакеты. Тем самым проверяется, есть ли потери на сети, не увеличилась ли задержка и т. д. «Прозванивается» вся сеть в пределах одной из зон доступности и между ними. Результаты отправляются в централизованную систему, которая их для нас визуализирует.
Вот как выглядят результаты, когда всё не очень хорошо:
Здесь видно, между какими сегментами сети есть проблема (в данном случае это A и B) и где всё хорошо (A и D). Здесь могут отображаться конкретные сервера, стоечные свитчи, модули и целые зоны доступности. Если что-либо из перечисленного станет источником проблемы, мы это увидим в реальном времени.
Кроме того, есть событийный мониторинг. Мы пристально следим за всеми соединениями, уровнями сигналов на трансиверах, BGP-сессиями и т. д. Предположим, из какого-то сегмента сети строится три BGP-сессии, одна из которых прервалась ночью. Если мы настроили мониторинги так, что падение одной BGP-сессии для нас не критично и может подождать до утра, то мониторинг не будит сетевых инженеров. Но если падает вторая из трёх сессий, происходит автоматический звонок инженеру.
Помимо End-to-End- и событийного мониторинга, мы используем централизованный сбор логов, их реалтайм-анализ и последующий анализ. Можно посмотреть корреляции, выявить проблемы и узнать, что творилось на сетевом оборудовании.
Тема мониторинга достаточно большая, тут огромный простор для улучшений. Хочется привести систему к большей автоматизации и настоящему self-healing.
У нас множество планов. Необходимо совершенствовать системы управления, мониторинга, коммутационной IP/MPLS-фабрики и многое другое.
Ещё мы активно смотрим в сторону white box-свитчей. Это готовое «железное» устройство, коммутатор, на который можно накатить свой софт. Во-первых, если всё сделать правильно, можно будет к коммутаторам «относиться» так же, как к серверам, выстроить по-настоящему удобный CI/CD-процесс, инкрементально раскатывать конфиги и т. д.
Во-вторых, если есть какие-то проблемы, лучше держать у себя группу инженеров и разработчиков, которые эти проблемы исправят, чем подолгу ждать исправления от вендора.
Чтобы всё получилось, ведётся работа в двух направлениях:
Это всё, что мы хотели рассказать о нашей сетевой инфраструктуре. Вот ссылка на Телеграм-канал Облака с новостями и советами.
 Мы продолжаем знакомить вас с внутренним устройством Яндекс.Облака. Сегодня поговорим о сетях — расскажем, как устроена сетевая инфраструктура, почему в ней активно применяется непопулярная для дата-центров парадигма MPLS, какие ещё сложные решения нам приходилось принимать в процессе построения облачной сети, как мы ей управляем и какие мониторинги используем.
Мы продолжаем знакомить вас с внутренним устройством Яндекс.Облака. Сегодня поговорим о сетях — расскажем, как устроена сетевая инфраструктура, почему в ней активно применяется непопулярная для дата-центров парадигма MPLS, какие ещё сложные решения нам приходилось принимать в процессе построения облачной сети, как мы ей управляем и какие мониторинги используем.Сеть в Облаке состоит из трёх слоёв. Нижний слой — уже упомянутая инфраструктура. Это физическая «железная» сеть внутри дата-центров, между дата-центрами и в местах присоединения к внешним сетям. Поверх сетевой инфраструктуры строится виртуальная сеть, а поверх виртуальной сети — сетевые сервисы. Эта структура не является монолитной: слои пересекаются, виртуальная сеть и сетевые сервисы напрямую взаимодействуют с сетевой инфраструктурой. Поскольку виртуальную сеть часто называют overlay, то сетевую инфраструктуру мы обычно называем underlay.

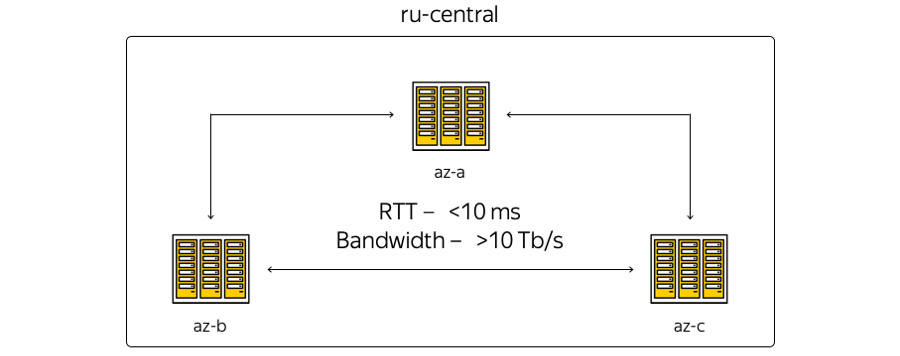
Сейчас инфраструктура Облака базируется в Центральном регионе России и включает в себя три зоны доступности — то есть три географически распределенных независимых дата-центра. Независимые — не зависящие друг от друга в контексте сетей, инженерных и электрических систем и т. д.
О характеристиках. География расположения дата-центров такова, что время приема-передачи в оба конца между ними (round-trip time, RTT) всегда составляет 6–7 мс. Суммарная емкость каналов уже перевалила за 10 терабит и постоянно наращивается, потому что Яндекс обладает собственной волоконно-оптической сетью между зонами. Поскольку мы не арендуем каналы связи, то можем оперативно наращивать ёмкость полосы между ДЦ: в каждом из них используется оборудование спектрального уплотнения.
Вот максимально схематичное представление зон:
Реальность, в свою очередь, немного другая:
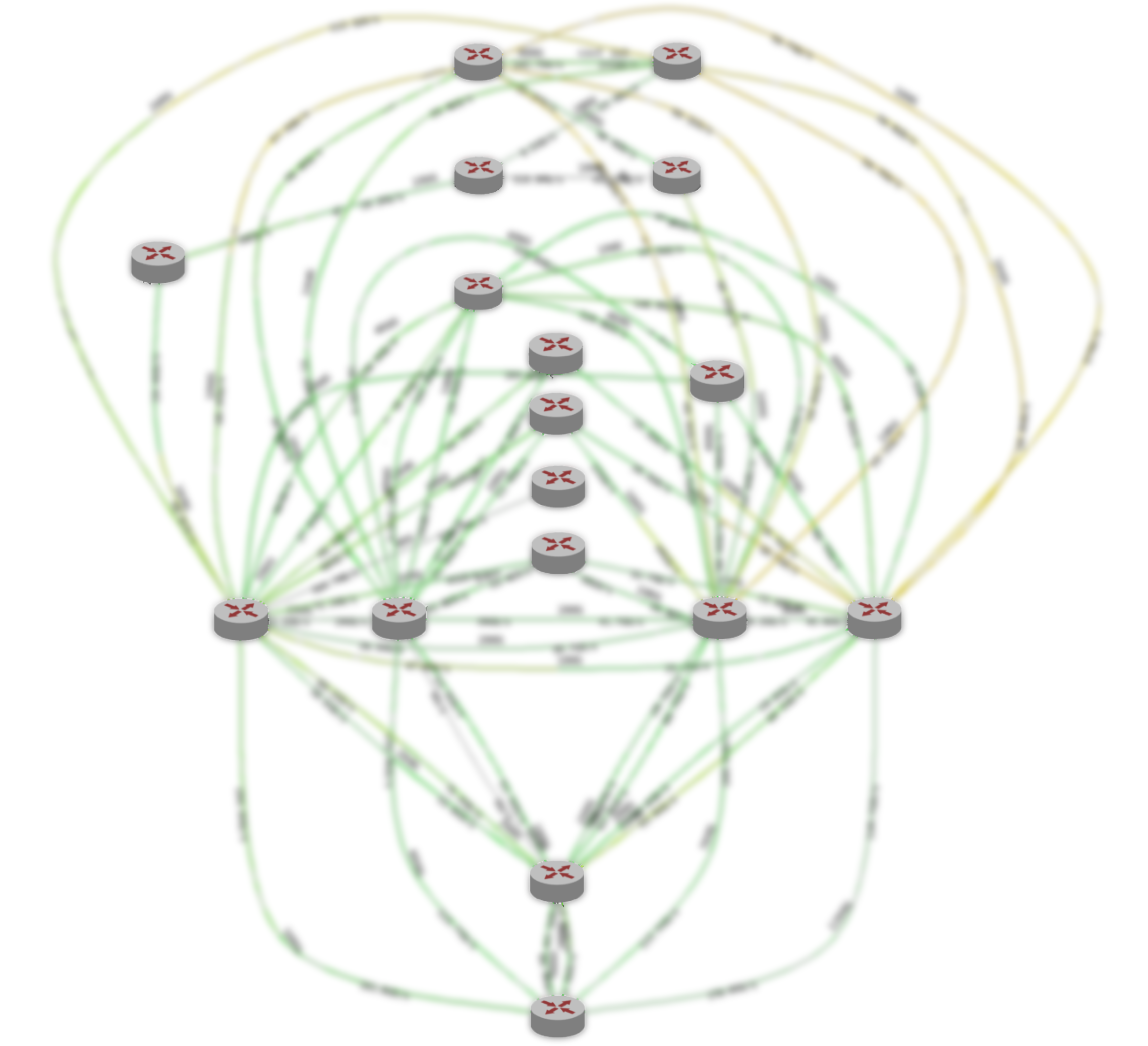
Здесь изображена текущая опорная сеть Яндекса в регионе. Поверх неё работают все сервисы Яндекса, часть сети используется Облаком. (Это картинка для внутреннего пользования, поэтому сервисная информация сознательно скрыта. Тем не менее, можно оценить количество узлов и соединений.) Решение задействовать опорную сеть было логичным: мы могли ничего не изобретать, а переиспользовать текущую инфраструктуру — «выстраданную» за годы развития.
В чем отличие между первой картинкой и второй? В первую очередь, зоны доступности не связаны между собой напрямую: между ними расположены технические площадки. Площадки не содержат серверного оборудования — на них размещаются только сетевые устройства по обеспечению связности. К техническим площадкам подключаются точки присутствия, где происходит стыковка Яндекса и Облака с внешним миром. Все точки присутствия работают на весь регион. Кстати, важно отметить, что с точки зрения внешнего доступа из интернета все зоны доступности Облака равнозначны. Другими словами, они обеспечивают одинаковую связность — то есть одну и ту же скорость и пропускную способность, а также одинаково низкие задержки.
Кроме того, на точках присутствия находится оборудование, к которому — при наличии on-premise-ресурсов и желании расширить локальную инфраструктуру облачными мощностями — могут подключиться клиенты по гарантированному каналу. Это можно сделать с помощью партнёров или самостоятельно.
Опорная сеть используется Облаком как MPLS-транспорт.
MPLS
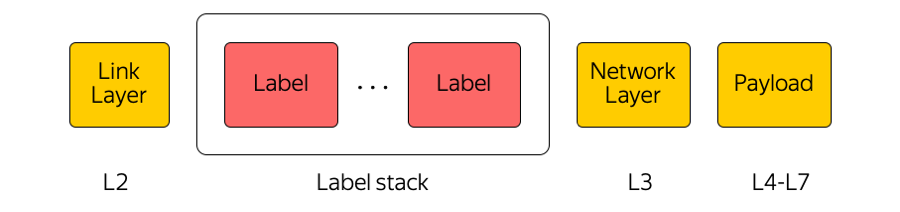
Multi protocol label switching (мультипротокольная коммутация по меткам) — крайне широко используемая в нашей отрасли технология. Например, когда какой-либо пакет передаётся между зонами доступности или между зоной доступности и интернетом, то транзитное оборудование обращает внимание только на верхнюю метку, «не думая» о том, что под ней. Таким образом MPLS позволяет скрыть сложность Облака от транспортного уровня. Вообще, мы в Облаке очень любим MPLS. Мы даже сделали её частью нижнего уровня и используем непосредственно на коммутационной фабрике в дата-центре:

(На самом деле между Leaf-свитчами и Spines огромное количество параллельных линков.)
Почему MPLS?
MPLS и правда совсем не часто можно встретить в сетях дата-центров. Зачастую используются совсем другие технологии.
Мы используем MPLS по нескольким причинам. Во-первых, мы посчитали удобным унифицировать технологии control plane и data plane. То есть вместо одних протоколов в сети дата-центра, других протоколов в опорной сети и мест стыка этих протоколов — единый MPLS. Тем самым мы унифицировали технологический стек и снизили сложность сети.
Во-вторых, в Облаке мы используем различные сетевые appliances, например Cloud Gateway и Network Load Balancer. Им нужно коммуницировать между собой, отправлять трафик в интернет и наоборот. Эти сетевые appliances могут горизонтально масштабироваться при росте нагрузки, а поскольку Облако строится по модели гиперконвергентности, они могут быть запущены в абсолютно любом месте с точки зрения сети в дата-центре, то есть в общем пуле ресурсов.
Таким образом, эти appliances могут запуститься за любым портом стоечного свитча, где находится сервер, и начать общаться по MPLS со всей остальной инфраструктурой. Единственной проблемой в построении такой архитектуры была сигнализация.
Сигнализация
Классический стек протоколов MPLS достаточно сложный. Это, кстати, является одной из причин нераспространённости MPLS в сетях дата-центров.
Мы, в свою очередь, не стали использовать ни IGP (Interior Gateway Protocol), ни LDP (Label Distribution Protocol), ни другие протоколы распространения меток. Используется только BGP (Border Gateway Protocol) Label-Unicast. Каждый appliance, который запускается, например, в виде виртуальной машины, строит сессию BGP до стоечного Leaf-свитча.
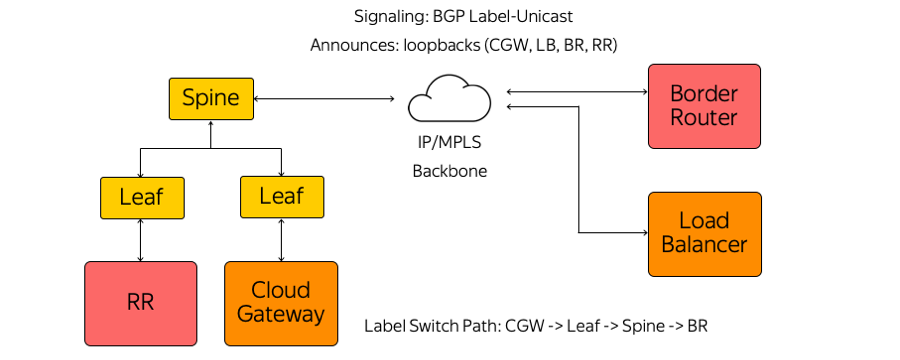
BGP-сессия строится по заранее известному адресу. Нет необходимости автоматически настраивать свитч под запуск каждого appliance. Все свитчи настроены заранее и единообразно.
В рамках сессии BGP каждый appliance отправляет свой loopback и получает loopbacks остальных устройств, с которыми ему нужно будет обмениваться трафиком. Примеры таких устройств — route reflectors нескольких видов, пограничные маршрутизаторы и другие appliances. В итоге на устройствах появляется информация о том, как им достичь друг друга. Из Cloud Gateway через Leaf-свитч, Spine-свитч и сеть до пограничного маршрутизатора строится Label Switch Path. Свитчи — это L3-коммутаторы, которые ведут себя как Label Switch Router и «не знают» об окружающей их сложности.
MPLS на всех уровнях нашей сети, помимо прочего, позволила нам использовать концепцию Eat your own dogfood.
Eat your own dogfood
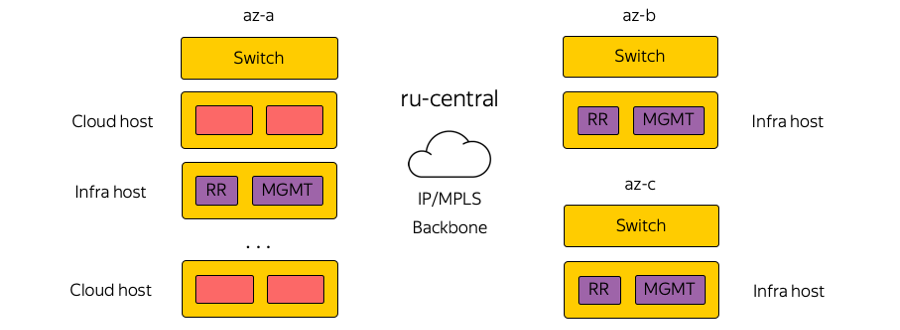
C точки зрения сети эта концепция подразумевает, что мы живем в той же инфраструктуре, которую предоставляем пользователю. Здесь схематично изображены стойки в зонах доступности:

Cloud host принимает на себя нагрузку от пользователя, содержит его виртуальные машины. А буквально соседний хост в стойке может нести на себе инфраструктурную с точки зрения сети нагрузку, включающую в себя route reflectors, сервера менеджмента, мониторинга и т. д.
Для чего это было сделано? Существовал соблазн запускать route reflectors и все инфраструктурные элементы в отдельном отказоустойчивом сегменте. Тогда, если бы где-то в дата-центре сломался пользовательский сегмент, инфраструктурные сервера продолжили бы управлять всей сетевой инфраструктурой. Но нам такой подход показался порочным — если мы не доверяем собственной инфраструктуре, то как мы можем предоставлять её нашим клиентам? Ведь поверх неё работает абсолютно всё Облако, все виртуальные сети, пользовательские и облачные сервисы.
Поэтому мы отказались от отдельного сегмента. Наши инфраструктурные элементы запускаются в той же сетевой топологии и с той же сетевой связностью. Естественно, они запускаются в тройном экземпляре — подобно тому, как наши клиенты запускают в Облаке свои сервисы.
IP/MPLS-фабрика
Вот примерная схема одной из зон доступности:
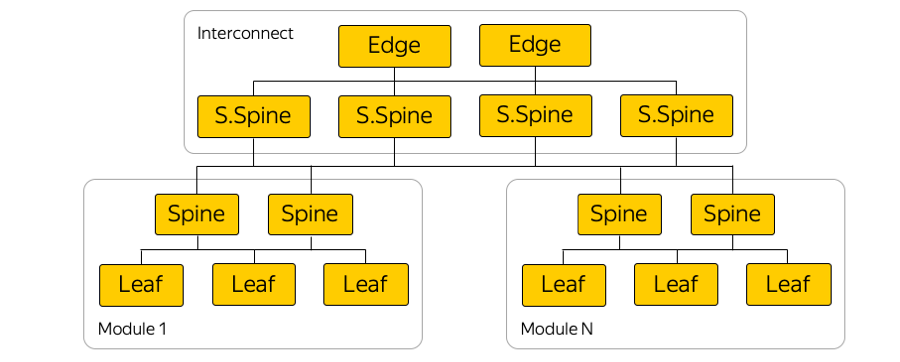
В каждой зоне доступности около пяти модулей, а в каждом модуле около сотни стоек. Leaf — стоечные свитчи, они внутри своего модуля связаны уровнем Spine, а межмодульная связность обеспечивается через сетевой Interconnect. Это следующий уровень, включающий в себя так называемые Super-Spines и Edge-свитчи, которые уже связывают между собой зоны доступности. Мы сознательно отказались от L2, речь идёт только про L3 IP/MPLS-связность. Для распространения маршрутной информации используется протокол BGP.
На самом деле параллельных соединений гораздо больше, чем на картинке. Такое большое количество соединений ECMP (Equal-сost multi-path) накладывает особые требования к мониторингу. Кроме того, возникают неожиданные, на первый взгляд, лимиты в оборудовании — например, количество ECMP-групп.
Подключение серверов
Яндекс за счёт мощных инвестиций строит сервисы таким образом, чтобы отказ одного сервера, серверной стойки, модуля или даже целого дата-центра никогда не приводил к полной остановке сервиса. Если у нас случаются какие-то сетевые проблемы — предположим, сломался стоечный свитч, — внешние пользователи этого никогда не видят.
Яндекс.Облако — особый случай. Мы не можем диктовать клиенту, как ему строить собственные сервисы, и решили нивелировать эту возможную единую точку отказа. Поэтому все сервера в Облаке подключаются к двум стоечным свитчам.
Мы точно так же не используем какие-либо протоколы резервирования на уровне L2, а сразу начали использовать только L3 с BGP — опять же, из соображения унификации протоколов. Такое подключение обеспечивает каждому сервису IPv4- и IPv6-связность: какие-то сервисы работают по IPv4, а какие-то — по IPv6.
Физически каждый сервер подключается двумя 25-гигабитными интерфейсами. Вот фото из дата-центра:

Здесь вы видите два стоечных свитча со 100-гигабитными портами. Видны расходящиеся breakout-кабели, делящие 100-гигабитный порт свитча на 4 порта по 25 гигабит на сервер. Мы называем такие кабели «гидра».
Управление инфраструктурой
Сетевая инфраструктура Облака не содержит никаких проприетарных решений для управления: все системы или опенсорсные с кастомизацией под Облако, или полностью самописные.
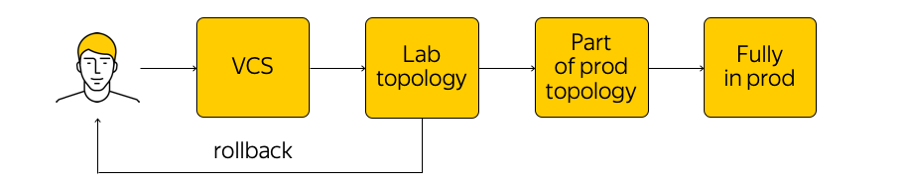
Как происходит управление этой инфраструктурой? В Облаке не то чтобы запрещено, но крайне не приветствуется заходить на сетевое устройство и вносить какие-то корректировки. Существует текущее состояние системы, и нам нужно применить изменения: прийти к какому-то новому, целевому состоянию. «Пробежаться скриптом» по всем железкам, что-то изменить в конфигурации — так делать не стоит. Вместо этого мы вносим изменения в шаблоны, в единую систему source of truth и коммитим наше изменение в систему контроля версий. Это очень удобно, потому что всегда можно сделать rollback, посмотреть историю, узнать ответственного за коммит и т. д.
Когда мы внесли изменения, генерируются конфиги и мы их выкатываем на лабораторную тестовую топологию. С точки зрения сети это маленькое облако, которое полностью повторяет весь существующий продакшен. Мы сразу увидим, если желаемые изменения что-то ломают: во-первых, по мониторингам, а во-вторых, по фидбеку от наших внутренних пользователей.
Если мониторинги говорят, что всё спокойно, то мы продолжаем выкатку — но применяем изменение только к части топологии (две и более доступности «не имеют права» сломаться по одной и той же причине). Кроме того, мы продолжаем пристально следить за мониторингами. Это достаточно сложный процесс, о котором мы расскажем чуть ниже.
Убедившись, что всё хорошо, мы применяем изменение ко всему продакшену. В любой момент времени можно откатиться и вернуться к предыдущему состоянию сети, оперативно отследить и исправить проблему.
Мониторинги
Нам нужны разные мониторинги. Один из самых востребованных — мониторинг End-to-End-связности. В любой момент времени каждый сервер должен иметь возможность покоммуницировать с любым другим сервером. Дело в том, что если где-то есть проблема, то мы хотим как можно раньше узнать, где именно (то есть какие сервера имеют проблемы с доступом друг к другу). Обеспечение End-to-End-cвязности — наша основная задача.
На каждом сервере перечислен набор всех серверов, с которыми он должен иметь возможность коммуницировать в любой момент времени. Сервер берёт случайное подмножество этого набора и отправляет на все выбранные машины ICMP-, TCP- и UDP-пакеты. Тем самым проверяется, есть ли потери на сети, не увеличилась ли задержка и т. д. «Прозванивается» вся сеть в пределах одной из зон доступности и между ними. Результаты отправляются в централизованную систему, которая их для нас визуализирует.
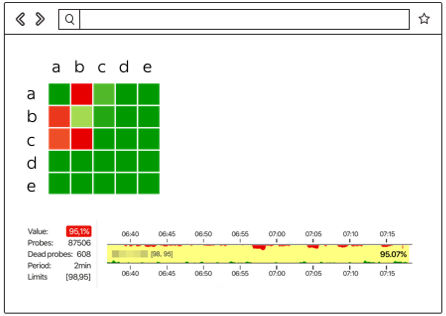
Вот как выглядят результаты, когда всё не очень хорошо:
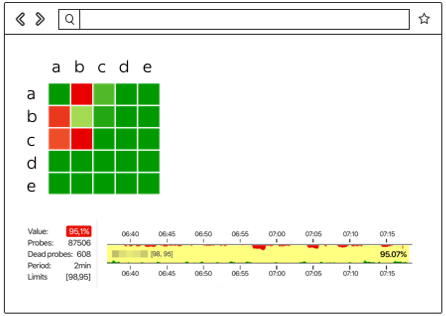
Здесь видно, между какими сегментами сети есть проблема (в данном случае это A и B) и где всё хорошо (A и D). Здесь могут отображаться конкретные сервера, стоечные свитчи, модули и целые зоны доступности. Если что-либо из перечисленного станет источником проблемы, мы это увидим в реальном времени.
Кроме того, есть событийный мониторинг. Мы пристально следим за всеми соединениями, уровнями сигналов на трансиверах, BGP-сессиями и т. д. Предположим, из какого-то сегмента сети строится три BGP-сессии, одна из которых прервалась ночью. Если мы настроили мониторинги так, что падение одной BGP-сессии для нас не критично и может подождать до утра, то мониторинг не будит сетевых инженеров. Но если падает вторая из трёх сессий, происходит автоматический звонок инженеру.
Помимо End-to-End- и событийного мониторинга, мы используем централизованный сбор логов, их реалтайм-анализ и последующий анализ. Можно посмотреть корреляции, выявить проблемы и узнать, что творилось на сетевом оборудовании.
Тема мониторинга достаточно большая, тут огромный простор для улучшений. Хочется привести систему к большей автоматизации и настоящему self-healing.
Что дальше?
У нас множество планов. Необходимо совершенствовать системы управления, мониторинга, коммутационной IP/MPLS-фабрики и многое другое.
Ещё мы активно смотрим в сторону white box-свитчей. Это готовое «железное» устройство, коммутатор, на который можно накатить свой софт. Во-первых, если всё сделать правильно, можно будет к коммутаторам «относиться» так же, как к серверам, выстроить по-настоящему удобный CI/CD-процесс, инкрементально раскатывать конфиги и т. д.
Во-вторых, если есть какие-то проблемы, лучше держать у себя группу инженеров и разработчиков, которые эти проблемы исправят, чем подолгу ждать исправления от вендора.
Чтобы всё получилось, ведётся работа в двух направлениях:
- Мы существенно снизили сложность IP/MPLS-фабрики. С одной стороны, уровень виртуальной сети и средства автоматизации от этого, наоборот, немного усложнились. С другой — сама underlay-сеть стала проще. Иными словами, есть определенное «количество» сложности, которое никуда не деть. Его можно «перекидывать» с одного уровня на другой — например, между уровнями сети или с уровня сети на уровень приложений. А можно эту сложность грамотно распределить, что мы и стараемся делать.
- И конечно, ведётся доработка нашего набора инструментов по управлению всей инфраструктурой.
Это всё, что мы хотели рассказать о нашей сетевой инфраструктуре. Вот ссылка на Телеграм-канал Облака с новостями и советами.
