
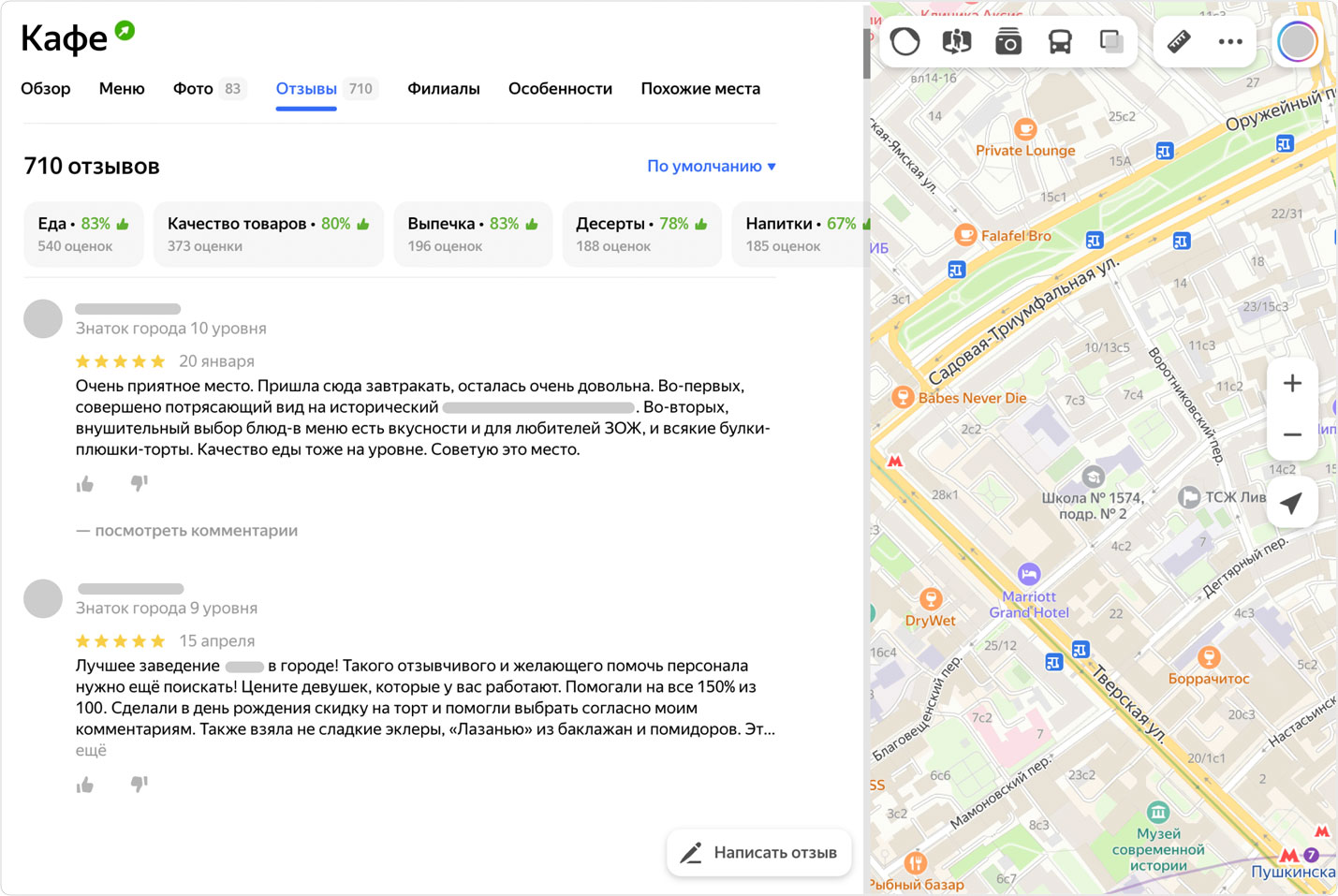
Существует классический способ выбрать, в какое кафе сходить или в какую организацию обратиться: достаточно почитать отзывы (которые, конечно, должны быть защищены от ботов). И такой способ правда популярен — в том числе, уверен, и среди читателей этого поста.
Для тех, кому важно выбрать быстрее, существует топ отзывов, а также рейтинг заведения. Но в случае с топом по-прежнему нужно вчитываться в мнения людей, а рейтинг скрывает за собой множество деталей — непонятно, учитывает ли он нюансы про еду, обслуживание, спектр услуг и так далее.
Мы поняли, что нужно учиться систематизировать отзывы и выделять главное. Этот пост — про то, как мы стремились состыковать интересы пользователей с доступными нам технологиями в машинном обучении и на фронтенде. Рассказывать буду достаточно подробно, чтобы вы прошли этот путь вместе со мной и увидели все пробы и ошибки. Возможно, по дороге у вас возникнут свои мысли о том, как можно решать подобную задачу.
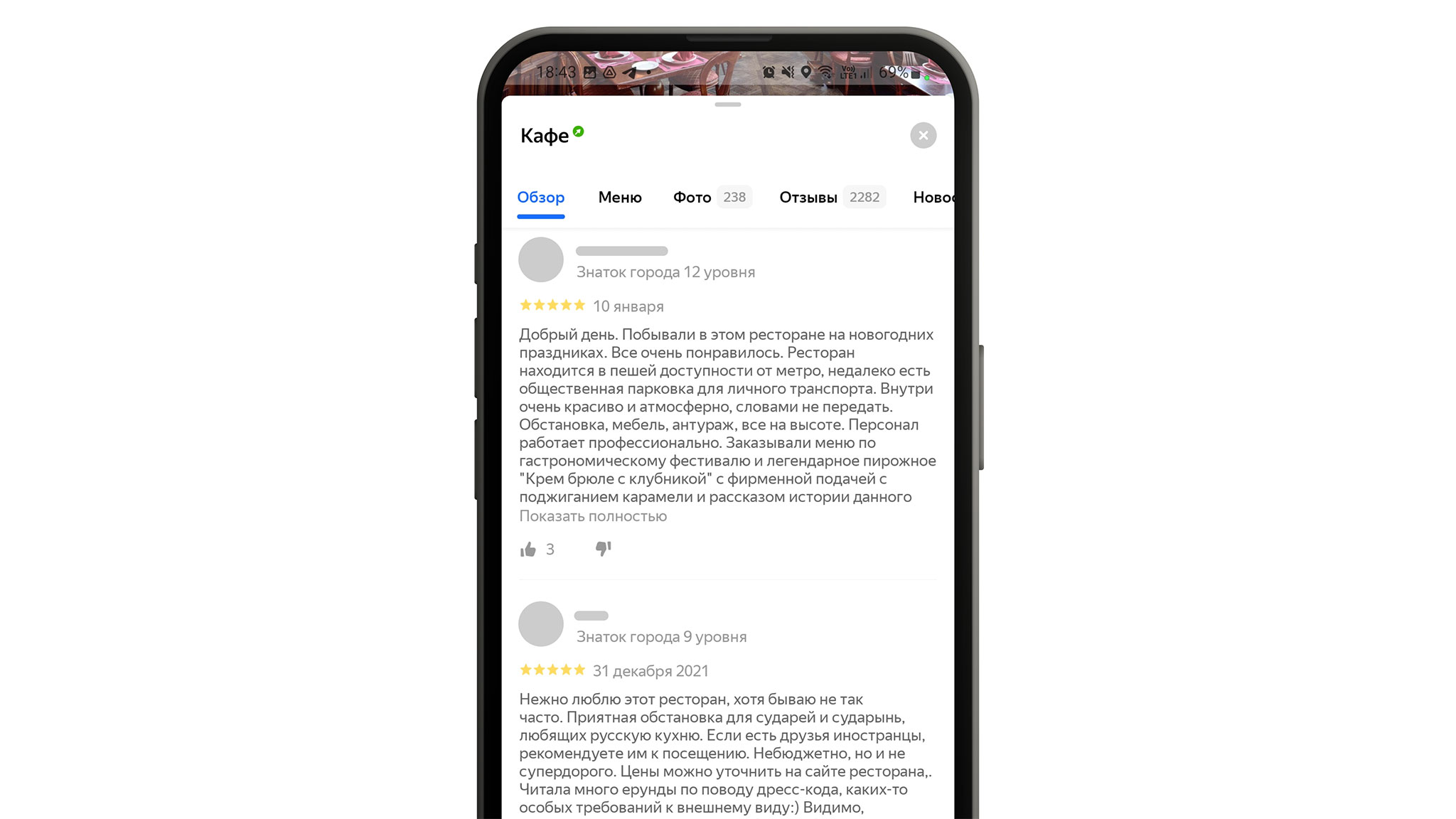
Первые шаги
С 2017 года мы активно собирали мнения посетителей о заведениях и компаниях и накопили огромное количество отзывов в разных категориях. Например, есть рестораны и медцентры с тысячами, а иногда и с десятками тысяч отзывов. Наше решение должно было помочь людям за несколько секунд оценить, хотят они в это место или нет. А владельцам компаний — быстро узнать, чем довольны клиенты, а чем нет.
В целом нам хотелось получить своего рода суммаризацию: 3–4 предложения о том, почему то или иное заведение классное и его стоит посетить. Зачастую суммаризация предполагает работу с большими генеративными текстовыми моделями, куда надо «положить» все отзывы. Но на первом этапе мы решили не вкладываться в большие генеративные модели, так как они требовали больших вложений при неподтверждённых продуктовых гипотезах.
Для начала мы решили собрать MVP и работать с аспектами — характеристиками, которые есть у каждого заведения: хорошо ли там готовят, как там внутри, удобное ли расположение, насколько чисто и всё в этом духе. По сути, это любое произвольное свойство организации. Оно может быть более общее — «чистота», а может более узкое — «суши». В аспекты мы включили те сущности, которые можно похвалить или поругать.
Чтобы двигаться дальше, нам надо было научиться делать несколько вещей:
- определять, что важно людям в разных заведениях. То есть какие аспекты искать;
- выделять эти аспекты в отзывах;
- оценивать тональность высказываний.
Первый этап. MVP
Мы начали со внутреннего инструмента Яндекса — библиотеки регулярных выражений под названием Remorph. С её помощью мы писали шаблоны, по которым фильтруется текст. Для старта выбрали категорию «Кафе и рестораны», в которой люди очень часто ищут подходящее место, и с этим есть реальная сложность. К тому же эта тематика и нам самим очень нравилась.
Что мы сделали? Взяли аспект, подобрали к нему синонимы и подготовили схемы, как находить отзывы на этот аспект. Например, мы ищем «бургер» и слова вокруг него. Если они подходят по некоторой схеме, которую мы сделали, — берём. Грубо говоря, мы просим Remorph: «Найди в этом тексте кусок отзыва, который подходит под эту регулярку». А сама регулярка при этом формулируется примерно так: «Дай мне прилагательное для этого существительного».
Так Remorph начал находить аспект и какой-то контекст, например: «Бургер» → «лучший» или «вкусный». То есть часть задачи решалась. Кроме этого, нам надо было научиться автоматически понимать, почему слово «лучший» или «вкусный» — это позитивная тональность, а «пресный» или «непрожаренный» — негативная. Если с позитивной и негативной всё понятно, то нейтральная тональность — это чаще всего констатация факта: «В этом отеле есть бассейн».
Для расчёта примерной тональности мы тоже сделали простой подход:
- Взяли контекстное слово. Например, «лучший».
- Нашли все отзывы, где это слово встречалось рядом с аспектом: «лучший» → «бургер».
- Посчитали средний рейтинг этих отзывов.
- Выбрали порог, когда считаем отзыв негативным, а когда позитивным. Например: для отзывов, где есть слово «недожаренный», средний рейтинг — 3. Такие определили как негативные.
В процессе работы с регулярками мы сразу поняли плюсы этого подхода: они очень точные и находят ровно то, что ты попросишь их искать. Также мы поняли и минусы: умрёшь, пока будешь писать все возможные регулярки. А ещё с ними нельзя находить синонимы.
Поиск формы
При этом мы не только постигали регулярки и разрабатывали классификатор тональности на коленке, но также искали продуктовую форму для аспектов. Для этого команда провела уйму UX-исследований, а затем онлайн-экспериментов в продакшене. Всё это заняло почти полгода. В итоге путём проб и ошибок мы нашли победителя. Между собой мы назвали это «градусниками»:

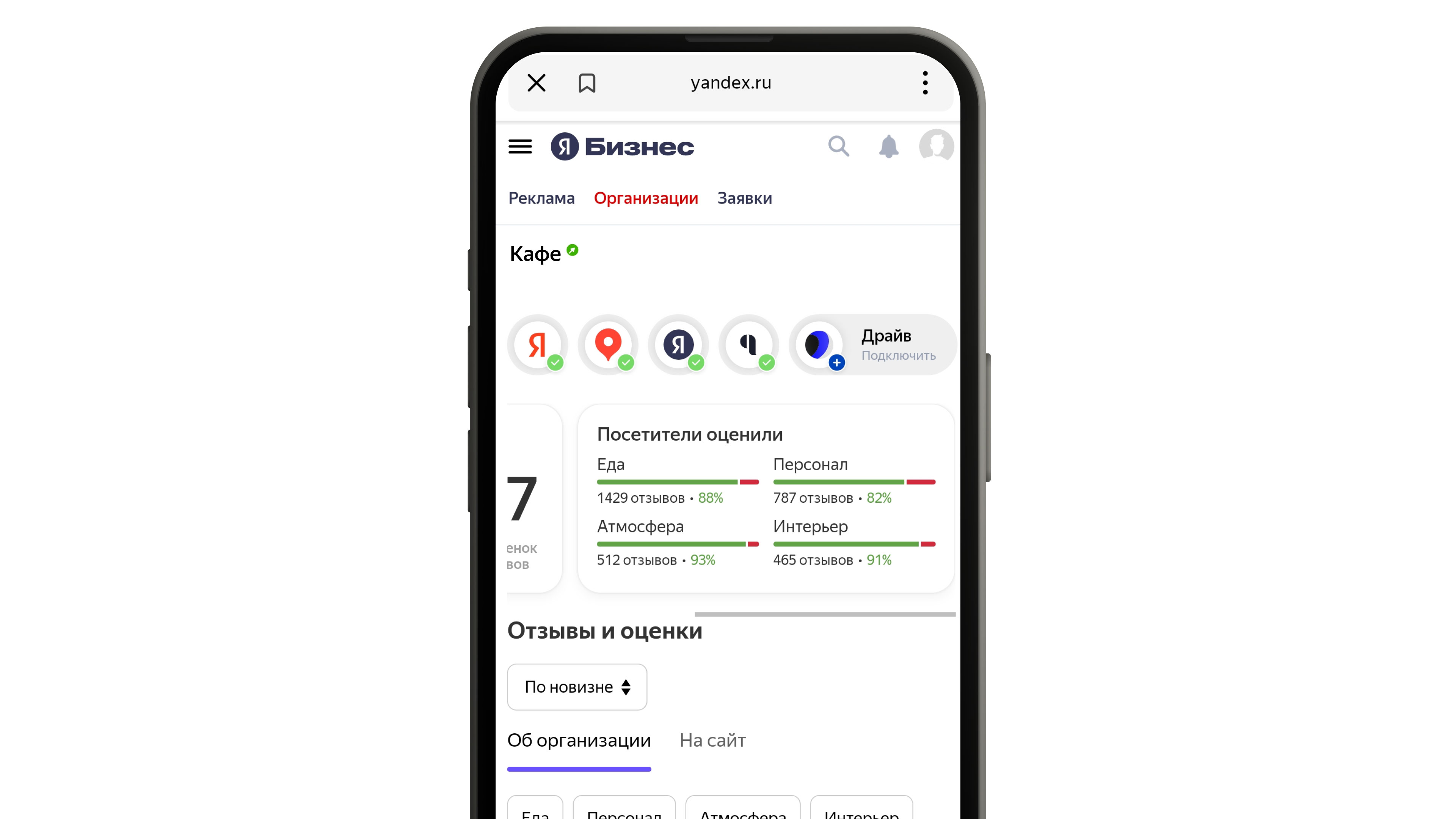
Это агрегированные аспекты, которые мы посчитали важными для конкретной организации. Они показываются над отзывами, а сами отзывы мы не трогаем.
Название «градусников» было говорящим: они отражали температуру того, как посетители заведения относятся к определённому аспекту.
Такая форма тоже вызывала некоторое недопонимание, поэтому и тут мы проводили дополнительные исследования. В итоге решили убрать разноцветные части и доработать вариант с процентами. К ним добавили «рукавички», и после этого всё стало гораздо понятнее:

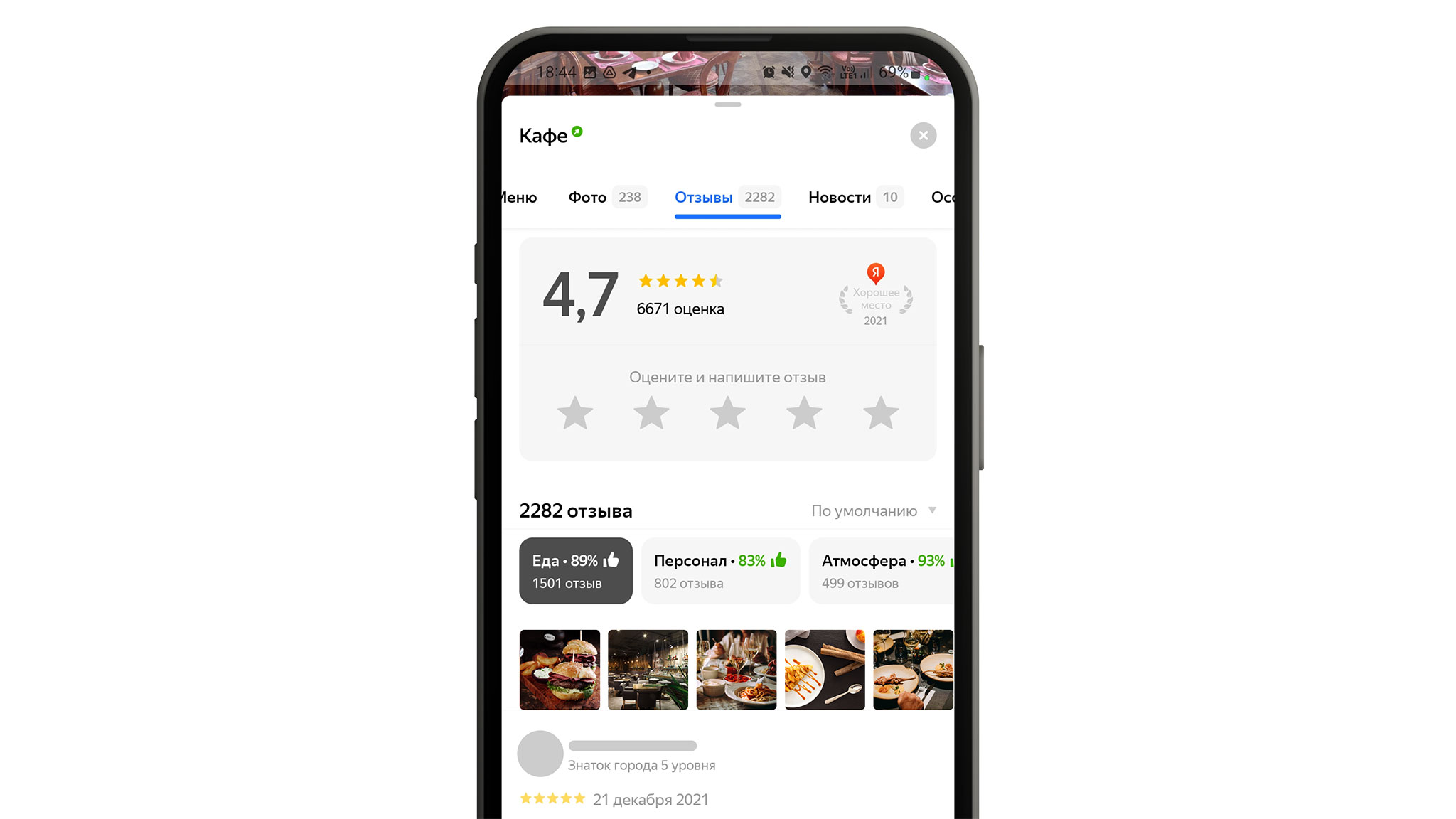
Такие блоки с оценкой появляются, когда есть как минимум десять позитивных или негативных отзывов о конкретном аспекте — при таком количестве мы считаем, что на основе этих данных уже можно сделать какие-то выводы. Сейчас пользователи могут увидеть «градусники» в профиле компаний в поиске Яндекса, в десктопной версии Яндекс Карт, а с недавнего времени и в мобильном приложении Карт. А владельцы могут посмотреть оценку характеристик их заведения в личном кабинете Яндекc Бизнеса.

В других интерфейсах



Итоги первого этапа
Что мы поняли из MVP-подхода? Регулярки работают и находят то, что нам было нужно, но далеко не всё. К тому же они находят только однотипные отзывы, которые не выходят за рамки того, что мы в них вложили. Это значило: будут случаи, когда аспект не находится, но в отзыве про него говорится.
Чтобы идти дальше, нам нужно было подготовить какое-то количество синонимов. И если для аспекта «бургер» это было просто, то для более общего аспекта «еда» перечислять синонимы долго. И ещё проблема — наш язык очень сложный. Мы увидели, что если аспект в отзыве хвалят, то обычно пишут как-то просто: «бургер отличный, понравился». А если ругают, то рассказывают почему: «развалился по дороге», «несли полчаса», «положили не тот соус». То есть сколько бы синтаксических конструкций мы ни составили для Remorph, велика вероятность, что мы не нашли бы все возможные варианты описания.
«А может, BERT?»
Мы подумали: «А не взять ли нам какую-то взрослую модель, которая умеет работать с текстами и избавит нас от проблем с низкой полнотой? А ещё смотрит не только на слова рядом с аспектом, а вообще на все слова в отзыве». И взяли модель BERT. Это всего лишь несколько энкодеров, применяемых ко входу последовательно. Сейчас мы не будем сильно углубляться в то, что это такое. Если коротко — это модель, которая предобучена на огромном массиве текстов и знает, как устроен язык.
Мы могли взять эту модель и достаточно дёшево по времени её обучить и настроить под свою задачу. А точнее, под две задачи: сделать классификацию по наличию аспекта в тексте отзыва и классификацию по тональности.
В этот момент нам сильно повезло, потому что у нас был размеченный массив текстов для категории «Кафе и рестораны». То есть в отзывах были специальные метки о том, есть ли там аспект и как о нём говорится: позитивно или негативно. Всё это мы делали в Яндекс Толоке — краудсорсинговом проекте для обработки больших массивов данных. У нас было восемь общих аспектов: «еда», «чистота», «цена», «расположение», «персонал», «напитки», «музыка», «завтраки». На них мы попробовали дообучить BERT и просто посмотреть, что получится. Спойлер: результаты оказались классными.
Мы договорились, что будем считать работу BERT успешной при определённых показателях. Если и точность, и полнота по экспертной разметке не ниже 0,9, то модель хорошо справляется с выделением аспекта. Если же качество не дотягивает, то мы повторяем цикл дообучения.
Что же мы получили? Во-первых, эта модель хорошо находила синонимы. Например, если задавался аспект «персонал», то кроме него находились и другие отзывы, где было написано, скажем, «официанты». Ещё мы увидели, что BERT не просто смотрит на наличие в отзыве каких-то позитивных или негативных слов, а находит те, что относятся именно к аспекту. Важно понимать, что часть этого знания заложена самой языковой моделью. Но всё же данные, которые мы давали на дообучении, тоже на это влияли, потому что для многих аспектов невозможно добиться хорошего качества без разметки.
| Аспект | Remorph Precision |
Remorph Recall |
BERT Precision |
BERT Recall |
| Еда | 0,899 | 0,311 | 0,987 | 0,976 |
| Цена | 0,743 | 0,729 | 1,0 | 0,97 |
| Персонал | 0,964 | 0,402 | 0,989 | 0,958 |
- Всю еду в регулярках не перечислишь. Отсюда полнота 0,3.
- На самом деле BERT, помимо названий самой еды, реагирует и на контекст. То есть в словосочетании «вкусный бешбармак» BERT находит аспект «Еда» скорее из-за слова «вкусный».
Что мы получили при сравнении Remorph и BERT?
- Показатель 0,3 означает, что из десяти отзывов об этом аспекте Remorph находит только три. А чтобы подобрать все синонимы для этой категории, мы вручную собирали и отбирали часто встречающиеся слова в отзывах про кафе («пицца», «суши» и т. д.). И всё равно полнота получилась 0,3.
- Показатель полноты с BERT по аспекту «еда» выше 0,9 — и это фантастический результат. По остальным аспектам результаты в среднем такие же.
Кроме того, мы заметили забавную особенность этой модели (напомню, она обучалась на восьми аспектах). BERT находила аспекты, которые на самом деле не видела в подготовленной разметке.

Например, мы не давали аспект «кофе» на этапе дообучения. Но BERT находила его в отзывах с весьма внушительной долей уверенности. А ещё примечательно, что она научилась находить в отзывах те признаки, которые определяют тональность. Например, BERT видела словосочетание «кофе не очень» и определяла тональность как –0,9.
Всё это придало нам окончательной уверенности в том, что надо масштабироваться. Для этого нам пришлось переделать все процессы: сбор разметки, метод обучения, принятия и валидации результатов. Потому что разработать прототип — одна задача, а масштабировать его — совсем другая.
Масштабирование
Для масштабирования нам надо было научить модель BERT работать с бóльшим количеством категорий и аспектов. Например, в «Кафе и ресторанах» к уже привычным «еде» и «персоналу» добавились более сложные аспекты: «интерьер» и «атмосфера». В других категориях мы столкнулись с вещами вроде «окрашивания волос», «шиномонтажа» и «схода-развала».
Сначала мы попробовали собрать разметку для новых аспектов и дообучить модель. Но эта попытка провалилась: мы добавили 50 аспектов и лишь для 20 удалось получить приемлемые показатели качества. При этом сколько разметки мы ни добавляли, лучше не становилось.
Оказалось, что проблема была в низком качестве самой разметки для новых аспектов. Толокеры — работники Яндекс Толоки — размечали отзывы и хорошо справлялись с простыми вещами, но с узкоспециализированными вроде «аппаратного маникюра» у них начинались проблемы.
Например, когда в отзывах упоминалось что-нибудь про «уют», толокеры не могли понять, к какому аспекту это отнести — к «интерьеру» или к «атмосфере». С «шиномонтажом» и «сходом-развалом» толокеры путались, так как эти услуги часто оказывают в одном месте. «Шиномонтаж» вообще оказался сложным аспектом. К примеру, в отзывах встречалось такое: «разварки огонь» — это про работу с дисками, но не про шиномонтаж. Или писали: «Заклеиваюсь уже 5 раз, всегда на высшем уровне», но речь шла не про ремонт резины, а про тонирование стёкол. Такие кейсы толокеры размечали плохо из-за специфики аспекта: не всегда было понятно, что это и с какой тональностью об этом говорится в отзыве.
Чтобы преодолеть эти проблемы, мы переработали инструкции и экзамены для толокеров. И это помогло: теперь они гораздо лучше справляются с заданиями, а мы получаем качественную разметку. Кроме этого, мы стали по-другому выбирать отзывы, которые отправляем на разметку. Например, начали использовать метод Active Learning: размечать отзывы, в которых модель сомневалась. Всё это позволило нам улучшить работу BERT с новыми категориями и довольно непростыми аспектами.
Автоматизация
В итоге мы собрали конвейер по автоматизированному созданию аспектов. Сейчас на входе мы даём модели новый аспект и описание того, что он из себя представляет, а на выходе получаем новый размеченный аспект в продакшене.
Как работает этот контур?
- Собирает метрики для приёмки нового аспекта: добирает разметку для обучения, применяет Active learning.
- Контролирует качество по метрикам: итеративно переобучает новую модель, пока не добьётся для новых аспектов нужного качества, при этом без потери качества для старых.
- Находит аспект в отзывах и выкладывает новую базу отзывов в продакшен.
Как визуально выделить аспект в отзыве
У нас была ещё одна задача: упростить чтение длинных отзывов. Мы хотели научиться показывать пользователю сразу тот кусок текста, в котором говорят о конкретном аспекте. Это позволило бы не просматривать весь текст целиком и не выискивать там нужное предложение.
Тут нам помогло знание устройства BERT: при обработке текста модель ищет аспект и выделяет в отзыве те участки, которые относятся к этому аспекту. Этот механизм называется Self-attention. Мы научились использовать его, чтобы выделять в отзывах нужные места.
Теперь пользователю достаточно нажать на какой-нибудь аспект в «градуснике», и откроются все отзывы с этим аспектом. А механизм выделит жирным релевантную часть текста:

Итоги
Главный результат: у нас есть более 200 размеченных аспектов в продакшене и они уже покрывают достаточное количество категорий, кроме «Кафе и ресторанов». Например: «салоны красоты», «отели», «автосервисы» и «горнолыжные курорты». Конечно же, на этом работа не заканчивается, и мы будем развивать «градусники» дальше. Можно подвести итоги того, сколько времени ушло на их создание:
— четыре месяца на эксперименты с Remorph;
— параллельно четыре–пять месяцев мы думали о том, как всё это показать в продукте;
— месяц на сборку BERT;
— полгода на масштабирование.
И главные выводы:
— Разметка is the King!
— Надо было не стесняться и не пытаться собрать что-то на регулярках, а сразу брать BERT.
