
Реализация и апробация алгоритма распознавания мимики
8 мин
Содержание:
1. Поиск и анализ цветового пространства оптимального для построения выделяющихся объектов на заданном классе изображений
2. Определение доминирующих признаков классификации и разработка математической модели изображений мимики"
3. Синтез оптимального алгоритма распознавания мимики
4. Реализация и апробация алгоритма распознавания мимики
5. Создание тестовой базы данных изображений губ пользователей в различных состояниях для увеличения точности работы системы
6. Поиск оптимальной аудио-системы распознавания речи на базе открытого исходного кода
7. Поиск оптимальной системы аудио распознавания речи с закрытым исходным кодом, но имеющими открытые API, для возможности интеграции
8. Эксперимент интеграции видео расширения в систему аудио-распознавания речи с протоколом испытаний
Цели:
Определить наиболее оптимальный алгоритм под задачи распознавания мимики человеческого лица, рассмотреть способы его реализации.
Задачи:
Провести анализ существующих алгоритмов распознавания мимики, учитывая определённые нами доминирующие признаки классификации и математической модели. На основании полученных данных выбрать оптимальный вариант алгоритма для последующей его реализации и апробации.
Введение
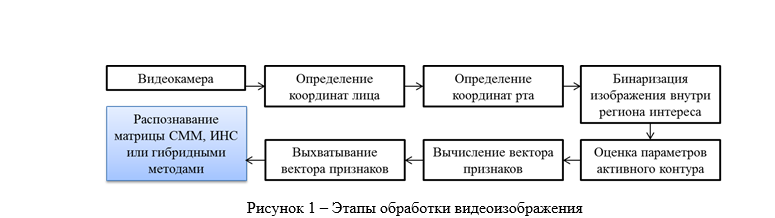
В предыдущих научных отчётах была разработана математическая модель распознавания мимики, и был синтезирован алгоритм распознавания мимики. Существуют два подхода в распознавании мимики – использование деформируемой модели на области губ и выхватывание векторных признаков области губ с последующим их анализом с помощью алгоритмов на основе гауссовых смесей. Для реализации распознавания мимики необходимо выбрать оптимальный алгоритм.
1. Алгоритмы распознавания человеческого лица:
1.1 Алгоритмы, основанные на деформируемой модели.
Деформируемая модель (deformable template model) – это шаблон некоторой формы (для двумерного случая — открытая либо замкнутая кривая, для трехмерного — поверхность). Наложенный на изображение, шаблон деформируется под воздействием различных сил, внутренних (определенных для каждого конкретного шаблона) и внешних (определенных изображением, на которое наложен шаблон) — модель меняет свою форму, подстраиваясь под входные данные [1]. Исходная грубая модель губ деформируется под действием силовых полей, заданных входным изображением (Рис.1).
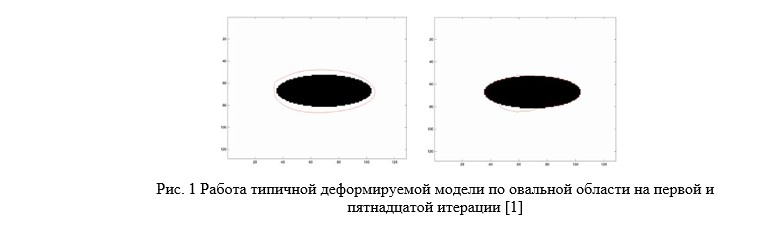
Основное преимущество над традиционными методами поиска, такими как преобразование Хафа (Hough transform [2]), в которых шаблон для поиска задается жестко, заключается в том, что деформируемые модели в процессе работы могут менять свою форму, позволяя более гибко осуществлять поиск объекта [3].
Основной недостаток деформируемых моделей [4] заключается в необходимости проведения большого числа итераций над большим количеством кадров, что значительно нагружает систему, но при вынесении основных вычислений в облако можно разгрузить систему.
Деформируемые модели можно классифицировать по типу ограничений, накладываемых на их форму, на два вида: деформируемые модели свободной формы и параметрические деформируемые модели.



 Привет, Хабр! Мой сегодняшний пост по программированию графики будет не таким объемным, как предыдущие. Почти в любом сложном деле иногда есть место несерьезному, и сегодня мы будем рендерить котиков. Точнее я хочу рассказать о реализации алгоритма рендеринга меха Shells and Fins (SAF) традиционно для Direct3D 11 и OpenGL 4. За подробностями прошу под кат.
Привет, Хабр! Мой сегодняшний пост по программированию графики будет не таким объемным, как предыдущие. Почти в любом сложном деле иногда есть место несерьезному, и сегодня мы будем рендерить котиков. Точнее я хочу рассказать о реализации алгоритма рендеринга меха Shells and Fins (SAF) традиционно для Direct3D 11 и OpenGL 4. За подробностями прошу под кат.
 Тема игры «Жизнь», не раз поднималась на
Тема игры «Жизнь», не раз поднималась на 

