Разбор всех задач и результаты Яндекс.Алгоритма
17 мин
Буквально пару часов назад в Санкт-Петербурге завершился открытый чемпионат по программированию Яндекс.Алгоритм 2013. Состязания состояли из нескольких онлайн-раундов по 100 минут, за победу боролись более 3000 программистов из 84 стран. По результатам трёх отборочных раундов в финал вышли 25 лучших.

Финалисты должны были решить шесть алгоритмических задач за 100 минут. Первое место занял недавний победитель ACM ICPC 2013 в составе команды НИУ ИТМО Геннадий Короткевич (tourist), который набрал меньше всего штрафного времени. Второе место досталось выпускнику НИУ ИТМО Евгению Капуну (eatmore). Третье место занял представитель Тайваня Ши Бисюнь.
В подготовке заданий для чемпионата участвовали специалисты из нескольких стран: России, Беларуси, Польши и Японии. Главными составителями задач стали разработчики минского офиса Яндекса (как и все сотрудники компании, к участию в состязаниях они не допускались). Мы попросили всех авторов разобрать задания, которые они подготовили для участников Яндекс.Алгоритма. Кстати, все задачи не удалось решить никому, лучший результат — три решённые задачи — показали только три участника.
Финалисты должны были решить шесть алгоритмических задач за 100 минут. Первое место занял недавний победитель ACM ICPC 2013 в составе команды НИУ ИТМО Геннадий Короткевич (tourist), который набрал меньше всего штрафного времени. Второе место досталось выпускнику НИУ ИТМО Евгению Капуну (eatmore). Третье место занял представитель Тайваня Ши Бисюнь.
В подготовке заданий для чемпионата участвовали специалисты из нескольких стран: России, Беларуси, Польши и Японии. Главными составителями задач стали разработчики минского офиса Яндекса (как и все сотрудники компании, к участию в состязаниях они не допускались). Мы попросили всех авторов разобрать задания, которые они подготовили для участников Яндекс.Алгоритма. Кстати, все задачи не удалось решить никому, лучший результат — три решённые задачи — показали только три участника.
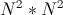 . Полный перебор крайне долгий, ведь время его работы растёт экспоненциально относительно размера входных данных. Например, время поиска максимального пути в графе из 15 вершин наивным перебором становится заметным, а при 20 — очень долгим.
. Полный перебор крайне долгий, ведь время его работы растёт экспоненциально относительно размера входных данных. Например, время поиска максимального пути в графе из 15 вершин наивным перебором становится заметным, а при 20 — очень долгим.






 Привет. В этой статье будет рассмотрен способ
Привет. В этой статье будет рассмотрен способ