Раз уж неделя «Морского боя» на Хабре продолжается, добавлю и я свои два цента.
При попытке найти оптимальную стратегию для игры за компьютер довольно быстро приходим к такому приближению:
Допустим, что состояние некоторых клеток нам уже известно, и мы хотим сделать ход, максимально приближающий нас к победе. В таком случае имеет смысл выбирать клетку, которая занята кораблём противника в наибольшем числе возможных размещений кораблей, не противоречащих имеющейся информации
В самом деле. Если возможная конфигурация только одна, то мы заканчиваем игру за один ход, расстреливая его корабли по очереди (ведь конфигурация нам известна!) Если же конфигураций больше, то нам нужно уменьшить их число как можно сильнее, тем самым увеличив имеющееся у нас количество информации. Если мы попадём в корабль, то ничего не потеряем (ведь ход остаётся у нас!), а если промахнёмся — то число оставшихся комбинаций будет минимальным из возможных после этого хода.

Понятно, что это только приближение к отпимальной стратегии. Если противник будет знать о нашем плане, он постарается разместить корабли так, чтобы они не попадали в те клетки, куда мы будем стрелять в начале игры. Правда, ему это поможет мало — мы всё равно в конце концом зажмём его в угол — но возможно, что определённая гибкость нам не помешала бы. Кроме того, не исключено, что продуманная серия ходов, первый из которых не является оптимальным, привела бы к лучшему результату. Но не будем пока усложнять и без того сложную задачу, а попытаемся просчитать все конфигурации и построить карту вероятности заполнения поля.
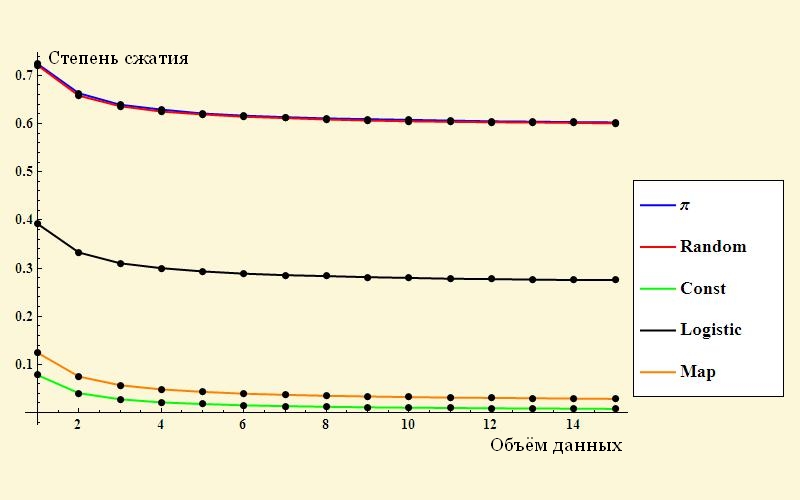
На первый взгляд, задача кажется неподъёмной. Число конфигураций представляется порядка 10
20 (на самом деле их несколько меньше — ближе к 10
15), так что на полный перебор времени уйдёт слишком много. Перебирать раскраски поля и оставлять только допустимые — не лучше: всё равно нам каждую комбинацию придётся просмотреть.
Что же ещё попробовать? Любой олимпиадник тут же ответит — динамическое программирование. Но как его организовать?


 В этой статье я расскажу об одном необычном подходе к генерации лабиринтов. Он основан на модели Амари́ нейронной активности коры головного мозга, являющейся непрерывным аналогом нейронных сетей. При определенных условиях она позволяет создавать красивые лабиринты очень сложной формы, подобные тому, что приведен на картинке.
В этой статье я расскажу об одном необычном подходе к генерации лабиринтов. Он основан на модели Амари́ нейронной активности коры головного мозга, являющейся непрерывным аналогом нейронных сетей. При определенных условиях она позволяет создавать красивые лабиринты очень сложной формы, подобные тому, что приведен на картинке. Доброго времени суток, уважаемые! Так случилось, что вопросом программирования более-менее адекватного ИИ для игры «морской бой» я озадачился где-то в конце 2004 года. Быть может я, не имея должных руководств под рукой, изобретал тогда велосипед, но и в последствии, мне попадались потрясающие своей честностью алгоритмы: стрелять наобум, время от времени подглядывая у игрока расположение кораблей, для выравнивания баланса. В последствии я несколько раз улучшал алгоритм. По последним статьям на Хабре можно судить, что тема актуальна, к тому же — мне есть что добавить к написанному другими пользователями.
Доброго времени суток, уважаемые! Так случилось, что вопросом программирования более-менее адекватного ИИ для игры «морской бой» я озадачился где-то в конце 2004 года. Быть может я, не имея должных руководств под рукой, изобретал тогда велосипед, но и в последствии, мне попадались потрясающие своей честностью алгоритмы: стрелять наобум, время от времени подглядывая у игрока расположение кораблей, для выравнивания баланса. В последствии я несколько раз улучшал алгоритм. По последним статьям на Хабре можно судить, что тема актуальна, к тому же — мне есть что добавить к написанному другими пользователями.


 На Coursera сейчас идёт курс
На Coursera сейчас идёт курс 
