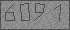Конкурс «Интернет-математика: Яндекс.Карты» — опыт нашего участия и описание победившего алгоритма
12 мин
Прошло уже больше года после завершения конкурса "Интернет-математика: Яндекс.Карты", но нас до сих пор спрашивают об алгоритме, который принёс нам победу в этом конкурсе. Узнав о том, что недавно Яндекс объявил о старте очередной "Интернет-математики", мы решили поделиться опытом нашего прошлогоднего участия и описать наш подход. Разработанный алгоритм смог с точностью 99.44% правильно определить лишние изображения в сериях панорамных снимков, например, как здесь:

В этой статье мы описываем основные идеи алгоритма и приводим его детали для интересующихся, рассказываем об извлечённых уроках и о том, как это всё вообще было.
Исходный код нашего решения доступен на github (C++ с использованием OpenCV).
В этой статье мы описываем основные идеи алгоритма и приводим его детали для интересующихся, рассказываем об извлечённых уроках и о том, как это всё вообще было.
Исходный код нашего решения доступен на github (C++ с использованием OpenCV).
 Доброго времени суток, уважаемые читатели.
Доброго времени суток, уважаемые читатели. 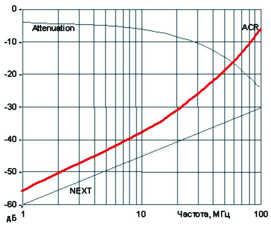 Понадобилось мне как-то сделать интерфейс для загрузки в микроконтроллер график функции «сопротивление -> температура» (график решили задавать по нескольким точкам, а потом их интерполировать). По ходу дела выяснилось, что график будет оч-чень нелинейным (180 Ом -> 100o, 6 000 Ом -> 0o, 30 000 Ом -> -30o). Поэтому пришлось мне погрузиться в тему
Понадобилось мне как-то сделать интерфейс для загрузки в микроконтроллер график функции «сопротивление -> температура» (график решили задавать по нескольким точкам, а потом их интерполировать). По ходу дела выяснилось, что график будет оч-чень нелинейным (180 Ом -> 100o, 6 000 Ом -> 0o, 30 000 Ом -> -30o). Поэтому пришлось мне погрузиться в тему