
Чисто функциональные структуры данных
7 мин
Признаюсь. Я не очень любил курс структур данных и алгоритмов в университете. Все эти стеки, очереди, кучи, деревья, графы (будь они не ладны) и прочие “остроумные” названия непонятных и сложных структур данных ни как не хотели закрепляться в моей голове. Как истинный “прагматик”, я уже на втором — третьем курсе свято верил в стандартную библиотеку классов и молился на дарованные нам (простым смертным) коллекции и контейнеры, бережно реализованные отцами и благородными донами CS. Казалось, все что можно было придумать — уже давно придумано и реализовано.
Все изменилось примерно год назад, когда я узнал, что есть другой мир. Мир отличный от нашего с вами. Более чистый и предсказуемый мир. Мир без побочных эффектов, мутаций, массивов и деструктивных апдейтов (переприсваиваний в переменную). Мир, где всем правит мудрейшая королева персистетность и ее прекрасные сестры — функция и рекурсия. Я говорю о чисто функциональном мире, где гармонично существуют, или даже живут, проекции почти всех известных нам структур данных.
И сейчас, я хочу показать вам небольшую частицу этого мира. Через замочную скважину, мы на секунду заглянем в этот удивительный мир, чтобы рассмотреть одного из наиболее ярких его обитателей — функциональное красно-черное дерево (КЧД).
Все изменилось примерно год назад, когда я узнал, что есть другой мир. Мир отличный от нашего с вами. Более чистый и предсказуемый мир. Мир без побочных эффектов, мутаций, массивов и деструктивных апдейтов (переприсваиваний в переменную). Мир, где всем правит мудрейшая королева персистетность и ее прекрасные сестры — функция и рекурсия. Я говорю о чисто функциональном мире, где гармонично существуют, или даже живут, проекции почти всех известных нам структур данных.
И сейчас, я хочу показать вам небольшую частицу этого мира. Через замочную скважину, мы на секунду заглянем в этот удивительный мир, чтобы рассмотреть одного из наиболее ярких его обитателей — функциональное красно-черное дерево (КЧД).
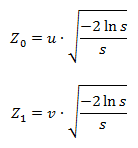
 Доброго времени суток читатель. Сегодняшний пост будет посвящен вычислению приближенного значения
Доброго времени суток читатель. Сегодняшний пост будет посвящен вычислению приближенного значения 

 Из этой статьи читатель узнает о том, как написать робота, проходящего тесты, и немножко «разомнет мозги» в теории вероятностей, разбираясь вместе с автором, почему при кажущейся сложности задачи автоматический подбор решения сходится за очень короткое время. Предупреждение: половина статьи ― «матан».
Из этой статьи читатель узнает о том, как написать робота, проходящего тесты, и немножко «разомнет мозги» в теории вероятностей, разбираясь вместе с автором, почему при кажущейся сложности задачи автоматический подбор решения сходится за очень короткое время. Предупреждение: половина статьи ― «матан». Привет. Кипят страсти, конец года, сессии, дедлайны, новый год, а так же цензура проникает во все слои интернетов, что не может не печалить.
Привет. Кипят страсти, конец года, сессии, дедлайны, новый год, а так же цензура проникает во все слои интернетов, что не может не печалить. 







{kind=link}