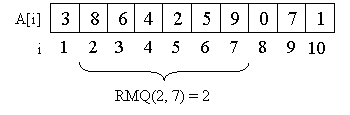Упрощенный алгоритм Бойера-Мура
3 мин
Прочитав статью об алгоритмах поиска подстроки в строке, я обнаружил, что там не рассказывается об алгоритме Бойера-Мура. Пара слов о нём всё-таки там есть, а именно, говорится, что алгоритм Бойера-Мура заслужил себе звание «алгоритма по умолчанию», потому что он в среднем дает лучшее время поиска (с чем я полностью согласен). Под катом рассказано об упрощенной версии этого алгоритма. В принципе, большинство скорее всего изучало этот алгоритм на 1-м или 2-м курсе ВУЗа (как и я), поэтому они могут пропустить эту статью, ничего нового тут нет.
 Эта статья представляет собой описание компонента HexaPath, реализующего поиск пути по алгоритму А* в гексагональной сетке. В сети мной было найдено большое количество описаний алгоритма на примере квадратной сетки и некоторое количество реализаций, но ни одного упоминания о шестиугольной сетке. И я написал свою реализацию. Выкладываю исходники. Вдруг кому-нибудь понадобится это, а писать самому будет лень.
Эта статья представляет собой описание компонента HexaPath, реализующего поиск пути по алгоритму А* в гексагональной сетке. В сети мной было найдено большое количество описаний алгоритма на примере квадратной сетки и некоторое количество реализаций, но ни одного упоминания о шестиугольной сетке. И я написал свою реализацию. Выкладываю исходники. Вдруг кому-нибудь понадобится это, а писать самому будет лень.