
Назад, к технологиям верхнего палеолита, от любимых всеми REST, STATEless, CRUD, CGI, FastСGI и MVC
7 мин
 «Только со смертью догмы начинается наука.»
«Только со смертью догмы начинается наука.»// Галилео Галилей
«Я начал завидовать рабам. Они всё знают заранее. У них твёрдые убеждения.»
// х/ф Марка Захарова «Убить дракона» по мотивам пьесы Евгения Шварца
Уже пару лет и дня не проходит, чтобы я не услышал (или не прочитал) от людей, начинающих новые проекты, фразу типа «Возьмем серверный движок для REST API и MVC, и погнали». Сначала я думал, что у этих слов есть один источник, может книжку какую завезли во все магазины или где-то в топе поисковиков лежит статья, зомбирующая разработчиков. Если же выяснять у них, что они понимают под REST и MVC, то можно повредиться умом. Ну с MVC уже все ясно, об этом я уже давно писал, ничего не изменилось, только усугубилось, стоит набрать в Google Images «mvc» и мы увидим страшное, стрелочки в любые стороны. Ну а про REST отвечают следующее: ну как же, нам нужно из браузерного GUI и мобильного приложения вызывать серверные методы, например: setUserCity(userId, cityId) или calculateMatrix(data) или startVideoConverter(options, source, destination) а потом мы столкнемся с большой нагрузкой и архитектура REST все решит. Дальше я задаю вопросы, от которых глаза округляются уже у тех, кто недавно еще горел праведной верой, рвался в бой и точно знал, что к чему в этом мире. Теперь можно перейти к рассмотрению терминологической катастрофы, в эпицентре которой мы с вами пребываем.
Быстрый вывод графиков в Матлабе
2 мин
Автор хочет поделится своим опытом организации быстрой перерисовки графиков (точнее сказать, изображений,) в Матлабе на примере организации радиолокационного индикатора кругового обзора
Масштабировать просто. Часть вторая — кэширование
4 мин
В предыдущей части мы говорили об основных архитектурных принципах построения масштабируемых порталов. Сегодня поговорим об оптимизации правильно построенного портала. Итак: первый вид оптимизации — локальный кэш.
Физический дизайн структур хранения в СУБД Teradata
12 мин
Туториал
Что такое физический дизайн структур хранения
 Основная цель, преследуемая в ходе разработки физической модели данных, — создание таких объектов для конкретной платформы/СУБД, которые позволят достигнуть максимальной производительности запросов/приложений, создающих основную нагрузку, сведя при этом дополнительные затраты, такие как необходимость поддерживать дополнительные индексы, выполнять материализацию производных данных и т. п., к минимуму.
Основная цель, преследуемая в ходе разработки физической модели данных, — создание таких объектов для конкретной платформы/СУБД, которые позволят достигнуть максимальной производительности запросов/приложений, создающих основную нагрузку, сведя при этом дополнительные затраты, такие как необходимость поддерживать дополнительные индексы, выполнять материализацию производных данных и т. п., к минимуму.Все реляционные СУБД построены на одних принципах, но каждой платформе присущи уникальные черты в виде наличия различных типов объектов и особенностей их реализации. По этой причине процесс физического моделирования является платформенно-зависимым, в отличие от логического моделирования, основная цель которого — достоверно описать данные и бизнес-процессы.
Масштабировать просто
8 мин
От B2C-порталов ожидается прежде всего масштабирование. К сожалению, масштабирование слишком часто объявляется вопросом Технологии — достаточно выбрать модную технологию и все проблемы решены. То, что это не так, может проявиться, позднее всего, уже в production mode (на рабочей системе).
Вместо того, чтобы махать технологической булавой, расскажу о том, как при помощи продуманной архитектуры и сознательного отказа от модели данных разработать высоко доступный (highly available), масштабируемый (scalable) портал. Первая часть опишет общие концепты, а возможные сценарии и их решения последуют.
Вместо того, чтобы махать технологической булавой, расскажу о том, как при помощи продуманной архитектуры и сознательного отказа от модели данных разработать высоко доступный (highly available), масштабируемый (scalable) портал. Первая часть опишет общие концепты, а возможные сценарии и их решения последуют.
Помогаем роботу-сортировщику на почте
3 мин

Короткая предыстория
Беседовал я некоторое время назад со знакомым роботом. Устроился он временно на Почту России сортировщиком писем. Работёнка не пыльная, смотрит индекс на письме и помещает их в нужное отверстие. Но есть проблема с письмами, у которых в индексе сделана опечатка. На выяснение правильного индекса уходит много времени и пиво успевает выдыхаться.
Заноза в голове
После того разговора прошло уже достаточно времени, но дилемма почтовых индексов не выходила у меня из головы.
Казалось бы — что еще тут можно улучшить? Попробуем преобразить вид цифр индекса таким образом, чтобы даже если одна ошибка попадётся, ее можно было автоматически выявить и исправить.
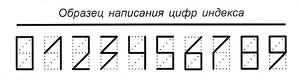
Оказывается улучшить можно.
Попробуем нарисовать новый вид цифры 0.
Если интересно, зачем и почему — прошу под кат.
Принципы работы СУБД. MVCC
5 мин
 Многие из нас сталкивались в своей работе с СУБД. На текущий момент базы данных в том или ином виде окружают нас повсюду, начиная с мобильных телефонов и заканчивая социальными сетями, в число которых входит и любимый нами хабр. Реляционные СУБД являются наиболее распространенными представителями семейства СУБД, и большинство из них являются транзакционными.
Многие из нас сталкивались в своей работе с СУБД. На текущий момент базы данных в том или ином виде окружают нас повсюду, начиная с мобильных телефонов и заканчивая социальными сетями, в число которых входит и любимый нами хабр. Реляционные СУБД являются наиболее распространенными представителями семейства СУБД, и большинство из них являются транзакционными.В институте нас заставляли заучивать определение ACID и стоящие за ним свойства, но почему-то стороной обходились подробности реализации этой парадигмы. В данной статье я постараюсь частично заполнить этот пробел, рассказав о MVCC, которая используется в таких СУБД как Oracle, Postgres, MySQL, etc. и является весьма простой и наглядной.
Разработка технического задания (ТЗ) на программный продукт с точки зрения заказчика. Работаем над ошибками
7 мин
В недалеком прошлом на этом замечательном ресурсе была опубликована статья Разработка технического задания (ТЗ) на программный продукт с точки зрения заказчика. Статья — сама по себе неплохая — содержит, к сожалению, ряд неточностей, о которых следует упомянуть. Сделаем это в «один проход» по абзацам. По второму абзацу:
Надо сказать, что у каждой из этих заинтересованных сторон свои требования и свое видение того, каким должно быть «хорошо написанное ТЗ». Например, у заказчика и исполнителя могут быть совершенно противоположные мнения на этот счет.Уточнения:
- Технические задания не пишут (составляют, подготавливают, оформляют и пр.), а разрабатывают, см. хотя бы п. 1.2 ГОСТ 34.602-89;
- Если заказчик и исполнитель руководствуются требованиями ГОСТов, то совершенно противоположных мнений у них в принципе быть не может и не должно. Если же взаимодействие осуществляется «по понятиям» — как сейчас принято — то без «плюрализЬма мнений» тут, конечно, никак не обойтись.
Опыт разработки сервис-ориентированной системы
4 мин
Некоторое время назад мы вместе с небольшой командой программистов начали разработку достаточно интересного с технической точки зрения аналитического проекта. Основной его целью была обработка данных, получаемых с различных веб-страниц. Нужно было обрабатывать эти данные, приводя в удобный вид и после этого анализировать собранную статистику.
До тех пор, пока у нас не было большого количества всевозможных данных, мы не имели каких-то нестандартных проблем и все решения были достаточно прямолинейными. Но проект разрастался, и размер собираемой информации, хотя сначала и не очень быстро, но все же увеличивался. Росла и кодовая база. И через некоторое время мы осознали весьма печальный факт — из-за всяких костылей и быстро-фиксов мы нарушили почти все возможные принципы проектирования. И если сначала организация кода была не столь важна, то со временем стало понятно, что без хорошего рефакторинга далеко мы не уедем.
До тех пор, пока у нас не было большого количества всевозможных данных, мы не имели каких-то нестандартных проблем и все решения были достаточно прямолинейными. Но проект разрастался, и размер собираемой информации, хотя сначала и не очень быстро, но все же увеличивался. Росла и кодовая база. И через некоторое время мы осознали весьма печальный факт — из-за всяких костылей и быстро-фиксов мы нарушили почти все возможные принципы проектирования. И если сначала организация кода была не столь важна, то со временем стало понятно, что без хорошего рефакторинга далеко мы не уедем.
Нужно ли читать код используемых библиотек?
4 мин
В какое прекрасное время мы живём! Вот пишешь ты программу и понадобилась тебе библиотека для чего-нибудь — она точно найдется! Многие библиотеки лежат в opensource и даже распространяются по приятным лицензиям типа LGPL, взял — и решил проблему. Делов-то: способ подключения описан в readme, библиотека предоставляет красивые интерфейсы, демка есть (она даже компилируется и работает). Вообще ООП со всеми его идеями абстракций, интерфейсов, инкапсуляции внутренних данных — мощнейшая штука (тут без иронии).
Но давайте подумаем, где и когда начинается «абстракция». Вот, например, есть у меня автомобиль, на котором я раз в неделю езжу в супермаркет. В этом случае он для меня вполне себе абстракция уровня «руль, три педали и пара рычажков», предоставляющая нужный мне функционал. Причём я могу пользоваться им долгие годы, не особо задумываясь что там под капотом — двигатель или волшебные гномы, зачем-то пьющие бензин и крутящие колёса. Но если я работаю автомехаником, конструктором автомобилей ну или попросту профессиональным водителем — я уже не могу позволить себе смотреть на машину столь «свысока», знать её внутреннее устройство — это моя работа. Покупатель молока в магазине может вообще ни разу в жизни не видеть живую корову, но вот фермер, который эту корову выращивает, просто обязан знать всё о её здоровье\содержании\питании\уходе\дойке. Ну и т.д. Есть чёткое разделение на «пользователей» продукта и его «создателей». Первые могут позволить себе не задумываться о деталях, вторые — нет.

Если вы дочитали аж до этого места, с большой долей вероятности вы — программист. Ещё раз, вы — человек, который профессионально занимается созданием компьютерных программ. Который, наверное, отвечает за свой труд и, возможно, считает себя неплохим специалистом. И вы считаете возможным взять чужую библиотеку и, ознакомившись с ней на уровне её интерфейса, использовать в своём продукте?
Но давайте подумаем, где и когда начинается «абстракция». Вот, например, есть у меня автомобиль, на котором я раз в неделю езжу в супермаркет. В этом случае он для меня вполне себе абстракция уровня «руль, три педали и пара рычажков», предоставляющая нужный мне функционал. Причём я могу пользоваться им долгие годы, не особо задумываясь что там под капотом — двигатель или волшебные гномы, зачем-то пьющие бензин и крутящие колёса. Но если я работаю автомехаником, конструктором автомобилей ну или попросту профессиональным водителем — я уже не могу позволить себе смотреть на машину столь «свысока», знать её внутреннее устройство — это моя работа. Покупатель молока в магазине может вообще ни разу в жизни не видеть живую корову, но вот фермер, который эту корову выращивает, просто обязан знать всё о её здоровье\содержании\питании\уходе\дойке. Ну и т.д. Есть чёткое разделение на «пользователей» продукта и его «создателей». Первые могут позволить себе не задумываться о деталях, вторые — нет.
Если вы дочитали аж до этого места, с большой долей вероятности вы — программист. Ещё раз, вы — человек, который профессионально занимается созданием компьютерных программ. Который, наверное, отвечает за свой труд и, возможно, считает себя неплохим специалистом. И вы считаете возможным взять чужую библиотеку и, ознакомившись с ней на уровне её интерфейса, использовать в своём продукте?
Симулируем чайник в Wind River Simics
4 мин
Перевод
Примечание переводчика: представляю вниманию почтенной публики статью Якоба Энгблома (Jakob Engblom), в которой он демонстрирует внесение «аналогового» устройства в общем-то дискретный симулятор. Сам я также использую и разрабатываю модели для Simics, но с несколько других позиций, из-за чего редко вижу конечные плоды всей деятельности. Поэтому мне было очень интересно узнать, чем занимаются мои коллеги из Wind River, а затем захотелось поделиться с вами. Тех, кому тема полноплатформенной симуляции или конкретно Simics показались интересными, рекомендую обратить внимание на свежайший выпуск Intel Technology Journal Simics Unleashed – Applications of Virtual Platforms. Я также могу рассказать о Simics более детально и на Хабре в последующих своих постах. Жду ваших комментариев!
Встраиваемая вычислительная система редко работает в изоляции. Тогда как персональные компьютеры и потребительская электроника обычно могут работать самостоятельно с относительно нечастным вмешательством человека, большинство встроенных компьютеров тесно взаимодействуют с окружающим их миром. Они «чувствуют» его, исполняют управляющие алгоритмы, считывают показания датчиков, используют всевозможные актуаторы для того, чтобы изменять внешнюю среду. Они — активные участники непрерывно эволюционирующей кибер-физической реальности. Симуляция таких систем не может быть ограничена моделью изолированного цифрового компьютера — приходится вносить в неё часть физического мира. На следующем видео на Youtube демонстрируется, как это можно осуществить с помощью Wind River Simics.
Вы встречались с анализом леса популяции запросов SQL промышленного приложения (например, для оптимизации)?
2 мин
Хочу задать этот вопрос Хабровчанам.
Современные информационные системы строятся на различных видах СУБД и все же реляционные СУБД остаются самыми распространенными и используемыми. Интересная статистика на эту тему ТУТ и ТУТ.
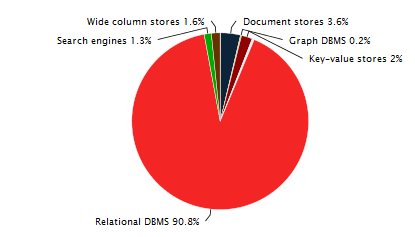
При разработке и модификации систем уровень формализации знаний аналитиков и разработчиков остается небольшим (автоматизации создания умных запросов или с учетом ряда четких правил) и чаще всего результирующие SQL запросы написаны «нормально», «как привык», «так пишут у нас на фирме», а вопросы оптимизации остаются на этап выполнения запросов в СУБД и последующие этапы оптимизации (в худшем случае ждут, когда все начинает тормозить).
Объем ручного кода остается большим даже несмотря на
Современные информационные системы строятся на различных видах СУБД и все же реляционные СУБД остаются самыми распространенными и используемыми. Интересная статистика на эту тему ТУТ и ТУТ.
При разработке и модификации систем уровень формализации знаний аналитиков и разработчиков остается небольшим (автоматизации создания умных запросов или с учетом ряда четких правил) и чаще всего результирующие SQL запросы написаны «нормально», «как привык», «так пишут у нас на фирме», а вопросы оптимизации остаются на этап выполнения запросов в СУБД и последующие этапы оптимизации (в худшем случае ждут, когда все начинает тормозить).
Объем ручного кода остается большим даже несмотря на
Ближайшие события
Аутсорсинг: как защитить свои разработки от копирования
6 мин

Читатели наших статей о разработке и производстве электроники часто задавали вопросы, связанные с кражей идей, разработок, ноу-хау и защитой информации в целом при передаче отдельных задач или всего проекта на аутсорсинг. Мы решили посвятить этой теме отдельный пост.
Главный вопрос руководства компаний при работе с внешними подрядчиками звучит так: как можно защитить свой проект от копирования? Рассмотрим оптимальные варианты ответа.
Выбор CASE инструмента для разработки процессов в BPMN
9 мин
Каждый, кто начинает разрабатывать бизнес процессы в BPMN нотации, сталкивается с проблемой выбора оптимального инструмента. Даже когда этот инструмент спускается сверху (мы в нашей организации работаем только на …) или коллега советует программу (меня полностью устраивает …), очень хочется, чтобы огласили весь список, который поможет понять, что Вы сделали верный выбор, ну или, что существуют более эффективные инструменты, чем те, на которых Вы вынуждены работать.
Для разработки схем процессов в соответствии с нотацией BPMN наработано уже довольно много программ. Этот обзор – результат небольшого исследования рынка для поиска того программного продукта, которое можно будет использовать для работы. Обзор не претендует на полный анализ рынка и может быть использован для получения первичной информации. Следует иметь ввиду, что все рассматриваемые программы рассмотрены в первую очередь с точки зрения «рисования» процесса, без учета реального позиционирования этих программ на рынке. Основные возможности, которые востребованы в рамках рассматриваемого контекста и по которым оценивались программы, это:
- полнота и соответствие нотации BPMN 2.0;
- удобство разработки схем процессов в нотации BPMN 2.0 и скорость дизайна;
- возможность проверки схем и выгрузки результатов в общепринятых форматах.
Также немного затронут вопрос возможности автоматизации разработанных процессов (без учета сложности и удобства внедрения, а также полноты достижения бизнес целей).
Геймификация в деле
9 мин

О чем все это
В последнее время о геймификации говорят много. Рассказывают о сути технологии и истории возникновения, описывают механики, приводят в пример Foursquare, собирают статистику и проводят опросы. Теории в сети достаточно, а вот качественных примеров применения геймификации в бизнесе мало. Данная статья ставит перед собой цель показать на примере LiveTex, каким образом можно органично вписать инструментарий геймификации в бизнес-процессы компании.
Системный аналитик: что можно ожидать от профессии?
3 мин

Данный пост я создаю для тех, кто хочет своей профессией выбрать системный анализ и хочет понимать, что его ждёт.
Не так давно я перебрался из Питера в Москву. Работая в небольшой компании, выполнял очень разнообразные задачи, но при поиске работы системным аналитиком в столице понял, что требования к одной и той же профессии, по сути, очень разные. Чем больше компания и проект, тем меньший скоп задач придётся выполнять, и как следствие, тем более узкая будет специализация. Широкий профиль возможен только на небольших проектах, где хватает ресурсов одного системного аналитика.
Вот что входит в его обязанности (обобщённо) в избыточном варианте:
Почему самолёты не летают сами?
4 мин
Тема поста навеяна новостью об очередной российской авиакатастрофе, на этот раз в Казани.
Нет, я не буду спекулировать на тему, кто виноват — ни в этом конкретном случае, ни в целом в индустрии авиаперевозок. Чего мне действительно хочется — это понять, почему сейчас, в 2013-м году, причиной крушения самолётов ещё может являться человеческий фактор, а также найти ответ на вопрос: зачем современным самолётам пилоты-люди?
Сразу уточню, что пилотом не являюсь и к авиации отношения не имею, поэтому всё что написано ниже имеет ярко выраженный диванный характер. Тем не менее, на мой взгляд, пост поднимает определённые принципиальные вопросы из области автоматизации управления авиационной техникой — и мы все выиграем, если на эти вопросы прозвучат какие-то ответы.
Нет, я не буду спекулировать на тему, кто виноват — ни в этом конкретном случае, ни в целом в индустрии авиаперевозок. Чего мне действительно хочется — это понять, почему сейчас, в 2013-м году, причиной крушения самолётов ещё может являться человеческий фактор, а также найти ответ на вопрос: зачем современным самолётам пилоты-люди?
Сразу уточню, что пилотом не являюсь и к авиации отношения не имею, поэтому всё что написано ниже имеет ярко выраженный диванный характер. Тем не менее, на мой взгляд, пост поднимает определённые принципиальные вопросы из области автоматизации управления авиационной техникой — и мы все выиграем, если на эти вопросы прозвучат какие-то ответы.
О стандартах мыслей свежих несколько
4 мин
 Речь пойдет, о технических стандартах, т.е. протоколах, спецификациях, паттернах, конвенциях, интерфейсах, форматах данных, нотациях и других отраслевых и особенно внутренних нормах, которые мы используем или изобретаем при разработке программных систем. Очевидных вещей я не буду повторять, каждый знает, что стандарты — это хорошо и правильно, что они способствуют унификации и, следовательно, совместимости систем и их модулей. Надеюсь, мои обобщения опыта, в форме «заметок для себя», будут полезными и нетривиальными.
Речь пойдет, о технических стандартах, т.е. протоколах, спецификациях, паттернах, конвенциях, интерфейсах, форматах данных, нотациях и других отраслевых и особенно внутренних нормах, которые мы используем или изобретаем при разработке программных систем. Очевидных вещей я не буду повторять, каждый знает, что стандарты — это хорошо и правильно, что они способствуют унификации и, следовательно, совместимости систем и их модулей. Надеюсь, мои обобщения опыта, в форме «заметок для себя», будут полезными и нетривиальными.Как быстро и точно оценить проект без ТЗ
6 мин
При таком сочетании – быстро, точно, без ТЗ – кажется, что задача не имеет решения. Однако в работе фрилансера такие задачи возникают постоянно, поэтому в борьбе за выживание заказы приходится учиться их решать. Для начала поясню, что означают вынесенные в заголовок слова.
Быстро – значит, раньше, чем заказчик примет решение о выборе исполнителя (другого исполнителя, раз вы еще не готовы ответить ему на самый главный вопрос).
Точно – значит, достаточно близко к реальной стоимости проекта, которую можно было бы озвучить после согласования ТЗ (а еще лучше после выполнения проекта, когда уже известно точное количество потраченного на разработку времени).
Ну и, наконец, что значит Без ТЗ? Понятно, что проектов совсем без ТЗ (в стиле «пойди туда, не знаю куда, принеси то, не знаю что») практически не бывает. Другое дело, в каком виде заказчик предоставляет вам это самое ТЗ.
Быстро – значит, раньше, чем заказчик примет решение о выборе исполнителя (другого исполнителя, раз вы еще не готовы ответить ему на самый главный вопрос).
Точно – значит, достаточно близко к реальной стоимости проекта, которую можно было бы озвучить после согласования ТЗ (а еще лучше после выполнения проекта, когда уже известно точное количество потраченного на разработку времени).
Ну и, наконец, что значит Без ТЗ? Понятно, что проектов совсем без ТЗ (в стиле «пойди туда, не знаю куда, принеси то, не знаю что») практически не бывает. Другое дело, в каком виде заказчик предоставляет вам это самое ТЗ.