Как писать свой процессор или расширяем функционал в NiFi
6 мин
Recovery Mode
Все большую популярность набирает NiFi и с каждым новым релизом он получает все больше инструментов для работы с данными. Тем не менее, может появиться необходимость в собственном инструменте для решения какой-то специфичной задачи.

Apache Nifi имеет в базовой поставке более 300 процессоров.
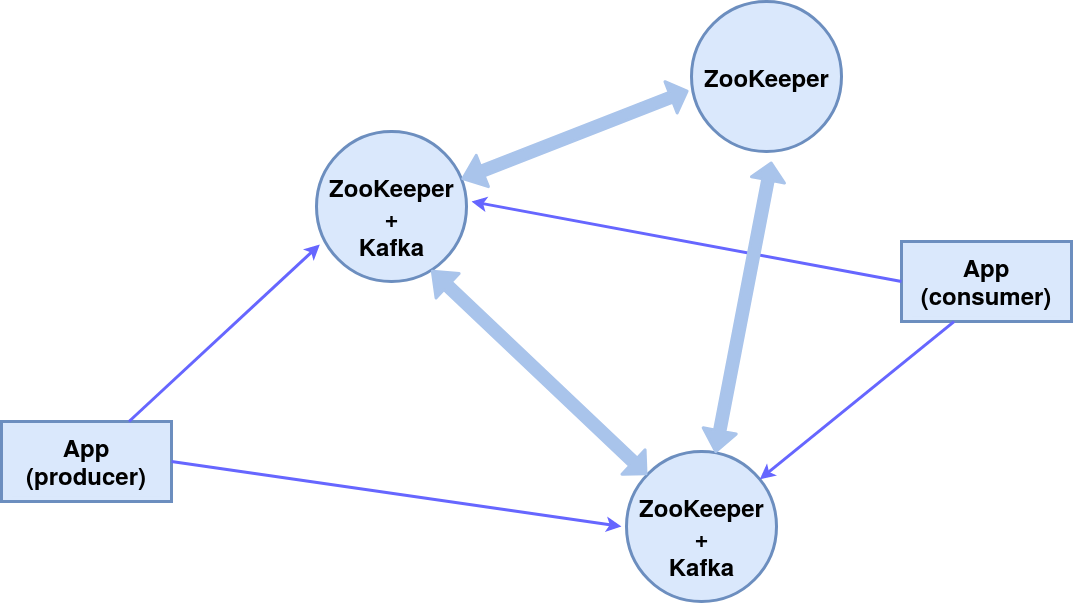
NiFi Processor это основной строительный блок для создания dataflow в экосистеме NiFi. Процессоры предоставляют интерфейс, через который NiFi обеспечивает доступ к flowfile, его атрибутам и содержимому. Собственный кастомный процессор позволит сэкономить силы, время и внимание пользователей, так как вместо множества простейших элементов-процессоров будет отображаться в интерфейсе и выполняться всего один (ну или сколько напишете). Так же, как и стандартные процессоры, кастомный процессор позволяет выполнять различные операции и обрабатывать содержимое flowfile. Сегодня мы поговорим о стандартных инструментах для расширения функционала.
Apache Nifi имеет в базовой поставке более 300 процессоров.
NiFi Processor это основной строительный блок для создания dataflow в экосистеме NiFi. Процессоры предоставляют интерфейс, через который NiFi обеспечивает доступ к flowfile, его атрибутам и содержимому. Собственный кастомный процессор позволит сэкономить силы, время и внимание пользователей, так как вместо множества простейших элементов-процессоров будет отображаться в интерфейсе и выполняться всего один (ну или сколько напишете). Так же, как и стандартные процессоры, кастомный процессор позволяет выполнять различные операции и обрабатывать содержимое flowfile. Сегодня мы поговорим о стандартных инструментах для расширения функционала.
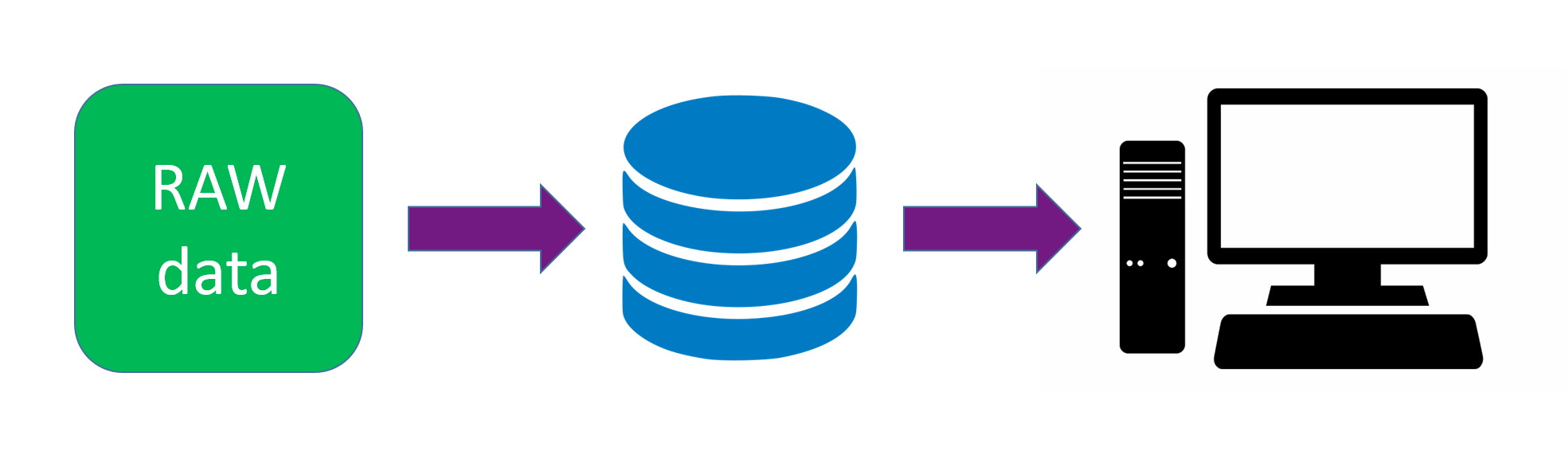

 При работе с большими объемами данных иногда может остро встать проблема нехватки места на дисках. Одним из способов решения данной проблемы является сжатие, благодаря которому, на том же оборудовании, можно себе позволить увеличить объемы хранения. В данной статье мы рассмотрим, как работает сжатие данных в Apache Ignite. В статье будут описаны только реализованные внутри продукта способы сжатия на диске. Другие способы сжатия данных (по сети, в памяти) как реализованные, так и нет останутся за рамками.
При работе с большими объемами данных иногда может остро встать проблема нехватки места на дисках. Одним из способов решения данной проблемы является сжатие, благодаря которому, на том же оборудовании, можно себе позволить увеличить объемы хранения. В данной статье мы рассмотрим, как работает сжатие данных в Apache Ignite. В статье будут описаны только реализованные внутри продукта способы сжатия на диске. Другие способы сжатия данных (по сети, в памяти) как реализованные, так и нет останутся за рамками.