Привет, Хабр! Меня зовут Сергей Евсеев, сегодня я расскажу, как в Apache NiFi настраивается ETL-пайплайн на задаче с JSON’ами. В этом мне помогут инструменты Jolt и Avro. Пост пригодится новичкам и тем, кто выбирает инструмент для решения схожей задачи.
Что делает наша команда
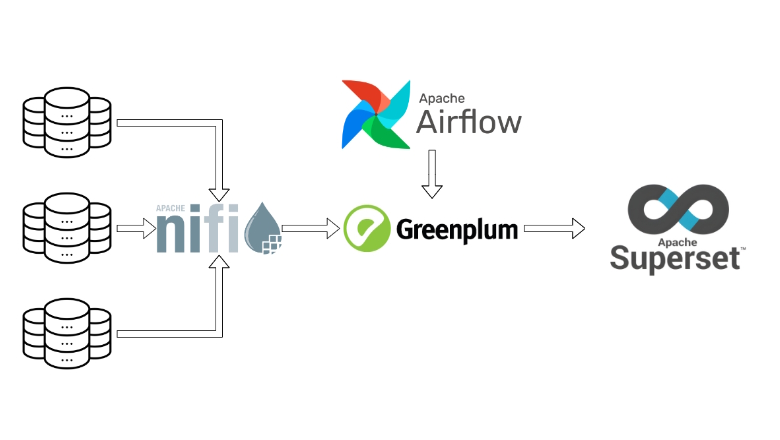
Команда работает с данными по рекрутингу — с любой аналитикой, которая необходима персоналу подбора сотрудников. У нас есть различные внешние или внутренние источники, из которых с помощью NiFi или Apache Spark мы забираем данные и складируем к себе в хранилище (по умолчанию Hive, но есть еще PostgreSQL и ClickHouse). Этими же инструментами мы можем брать данные из хранилищ, создавать витрины и складывать обратно, предоставлять данные внутренним клиентам или делать дашборды и давать визуализацию.
Описание задачи
У нас есть внешний сервис, на котором рекрутеры работают с подбором. Сервис может отдавать данные через свою API, а мы эти данные можем загружать и складировать в хранилище. После загрузки у нас появляется возможность отдавать данные другим командам или работать с ними самим. Итак, пришла задача — нужно загрузить через API наши данные. Дали документацию для загрузки, поехали. Идем в NiFi, создаем пайплайн для запросов к API, их трансформации и складывания в Hive. Пайплайн начинает падать, приходится посидеть, почитать документацию. Чего-то не хватает, JSON-ы идут не те, возникают сложности, которые нужно разобрать и решить.
Ответы приходят в формате JSON. Документации достаточно для начала загрузки, но для полного понимания структуры и содержимого ответа — маловато.
Мы решили просто загружать все подряд — на месте разберемся, что нам нужно и как мы это будем грузить, потом пойдем к источникам с конкретными вопросами. Так как каждый метод API отдает свой класс данных в виде JSON, в котором содержится массив объектов этого класса, нужно построить много таких пайплайнов с обработкой разного типа JSON’ов. Еще одна сложность — объекты внутри одного и того же класса могут отличаться по набору полей и их содержимому. Это зависит от того, как, например, сотрудники подбора заполнят информацию о вакансии на этом сервисе. Этот API работает без версий, поэтому в случае добавления новых полей информацию о них мы получим только либо из данных, либо в процессе коммуникации.