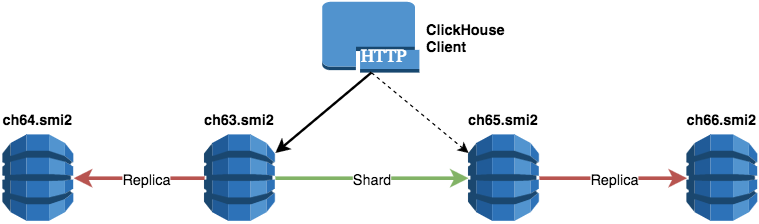
В данной статье я хочу продолжить тему сравнения баз данных, которые можно использовать для построения хранилища данных (DWH) и аналитики. Ранее я описал результаты тестов для Oracle In-Memory Option и In-Memory RDBMS Exasol. В данной же статье основное внимание будет уделено СУБД Vertica. Для всех описанных тестов использовались tpc-h benchmark на небольшом объёме исходных данных (2 Гб) и конфигурация БД на одном узле. Эти ограничения позволили мне многократно повторить бенчмарк в разных вариациях и с различными настройками. Для выбора аналитической СУБД под конкретный проект призываю читателей проводить испытания на своих кейсах (данные, запросы, оборудование и другие особенности).
В данной статье я хочу продолжить тему сравнения баз данных, которые можно использовать для построения хранилища данных (DWH) и аналитики. Ранее я описал результаты тестов для Oracle In-Memory Option и In-Memory RDBMS Exasol. В данной же статье основное внимание будет уделено СУБД Vertica. Для всех описанных тестов использовались tpc-h benchmark на небольшом объёме исходных данных (2 Гб) и конфигурация БД на одном узле. Эти ограничения позволили мне многократно повторить бенчмарк в разных вариациях и с различными настройками. Для выбора аналитической СУБД под конкретный проект призываю читателей проводить испытания на своих кейсах (данные, запросы, оборудование и другие особенности).Сравнение производительности аналитических СУБД HPE Vertica и Exasol с использованием TPC-H Benchmark
7 мин
В данной статье я хочу продолжить тему сравнения баз данных, которые можно использовать для построения хранилища данных (DWH) и аналитики. Ранее я описал результаты тестов для Oracle In-Memory Option и In-Memory RDBMS Exasol. В данной же статье основное внимание будет уделено СУБД Vertica. Для всех описанных тестов использовались tpc-h benchmark на небольшом объёме исходных данных (2 Гб) и конфигурация БД на одном узле. Эти ограничения позволили мне многократно повторить бенчмарк в разных вариациях и с различными настройками. Для выбора аналитической СУБД под конкретный проект призываю читателей проводить испытания на своих кейсах (данные, запросы, оборудование и другие особенности).
 Эта статья послужит практическим руководством по сборке, начальной настройке и тестированию работоспособности Hadoop начинающим администраторам. Мы разберем, как собрать Hadoop из исходников, сконфигурировать, запустить и проверить, что все работает, как надо. В статье вы не найдете теоретической части. Если вы раньше не сталкивались с Hadoop, не знаете из каких частей он состоит и как они взаимодействуют, вот пара полезных ссылок на официальную документацию:
Эта статья послужит практическим руководством по сборке, начальной настройке и тестированию работоспособности Hadoop начинающим администраторам. Мы разберем, как собрать Hadoop из исходников, сконфигурировать, запустить и проверить, что все работает, как надо. В статье вы не найдете теоретической части. Если вы раньше не сталкивались с Hadoop, не знаете из каких частей он состоит и как они взаимодействуют, вот пара полезных ссылок на официальную документацию:


 Свою предыдущую
Свою предыдущую