
Революция, связанная с анализом больших данных, порождает не только замечательные достижения, но и определенные трудности, в том числе методологического характера. Рассмотрим некоторые из них детальнее.
Flume — управляем потоками данных. Часть 1
11 мин
Привет, Хабр! В этом цикле статей я планирую рассказать о том, как можно организовать сбор и передачу данных с помощью одного из инструментов Hadoop — Apache Flume.

Четыре слова, которые нельзя (исследование русской обсценной лексики на материалах соц.медиа)
5 мин
Один мой приятель, учитель латинского языка, в начале урока спрашивал своих студентов, выполнили ли они домашнее задание. Как правило, если не первый, то второй или третий ученик сознавался: простите, господин Учитель, я ничего не сделал. «Фак!» — говорил учитель. «Фак!» — повторял он, вводя в еще большее недоумение своих чад. «Сегодня мы будем проходить глагол третьего спряжения facio – делать», который в повелительном наклонении единственного числа так и произносится: fac! – делай!
Нет, мы не собираемся витийствовать о том, что не бывает хороших и плохих слов, а есть наша оценка оных. Также мы не будем говорить об истоках и функциях русской брани, не будем обсуждать моральную сторону вопроса, как и искать причинно-следственные связи ее употребления. Мы проведем небольшое исследование обсценной лексики на материалах русскоязычных соц. медиа, сделаем ряд замеров и расчетов на большой выборке из интернет-источников.
Нет, мы не собираемся витийствовать о том, что не бывает хороших и плохих слов, а есть наша оценка оных. Также мы не будем говорить об истоках и функциях русской брани, не будем обсуждать моральную сторону вопроса, как и искать причинно-следственные связи ее употребления. Мы проведем небольшое исследование обсценной лексики на материалах русскоязычных соц. медиа, сделаем ряд замеров и расчетов на большой выборке из интернет-источников.
Palantir и отмывание денег
6 мин
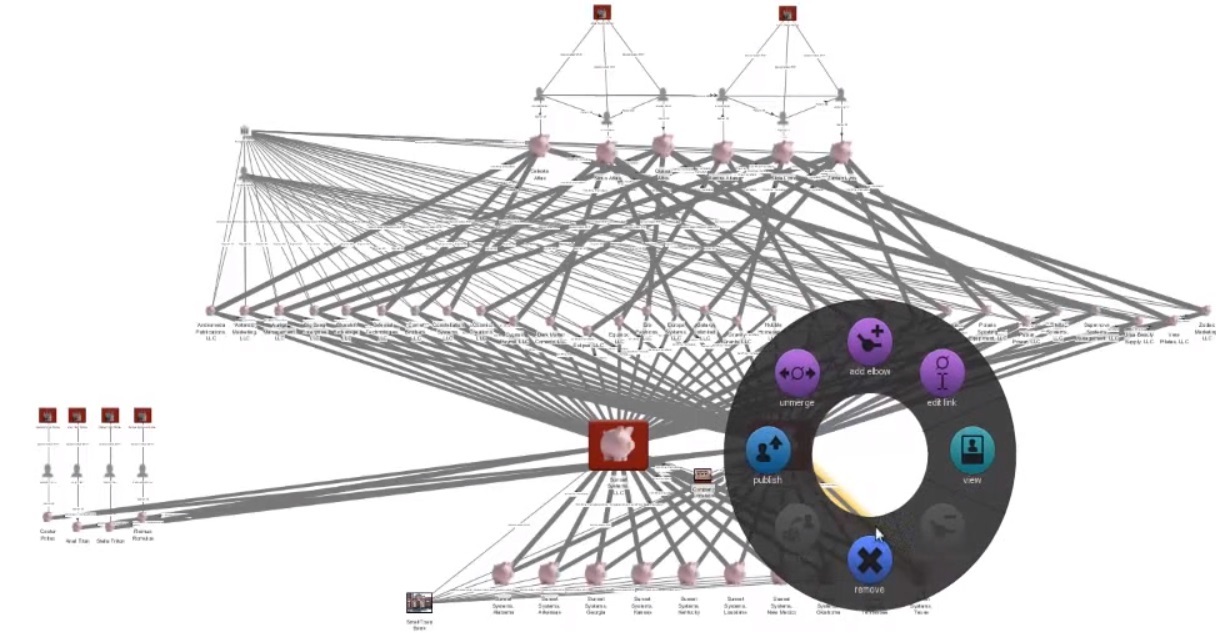
Palantir —
[Контент удален по требованию Википедии]
На официальном канале Palantir есть видео с демонстрацией работы аналитика, использующего систему Palantir в ходе расследования отмывания денег. По-моему, как-то так видели пользу информационных технологий «отцы-основатели» Вэнивар Буш («As We May Think»), Дуглас Энгельбарт («The Mother of All Demos») и Джозеф Ликлайдер («Интергалактическая компьютерная сеть» и «Симбиоз человека и компьютера»), о которых я писал немного ранее.
(За помощь с переводом спасибо Ворсину Алексею)
Визуализация инструментов обработки данных с Github
3 мин
В своей работе вы используете MySQL, Postgres или Mongo, а может даже Apache Spark? Хотите знать с чего начинались эти проекты и куда они движутся сейчас? В этой статье я представлю соответствующую визуализацию

Школа Данных «Билайн»: весна, знания, новый курс
1 мин

Привет, Хабр.
Итак, третий курс Школы Данных «Билайн» подходит к завершению и мы набираем четвёртый.
У нас 18 занятий, 36 часов, все основные темы машинного обучения и анализа данных, куча практики, куча домашек, два Kaggle соревнования, презентации и воркшопы от партнеров, возможность устройства в Билайн в команду BigData для лучших студентов, сокурсники из различных областей бизнеса, где применяется машинное обучение и много чего ещё.
Ученые создали нейросеть, распознающую «пьяные» сообщения в Twitter
4 мин
В свете текущих выходных, важно не забывать, что алкоголь и общение, вместе составляют не всегда хорошую комбинацию, даже у звезд. Тем не менее, многие из нас повторяют этот опыт снова и снова. И этот опыт дал американским ученым (Nabil Hossain с приятелями из University of Rochester) интересную идею. В итоге, американские ученые разработали нейронную сеть, способную распознавать в Twitter посты написанные в состоянии алкогольного опьянения. Кроме того, полученная математическая модель может определять, где авторы «пьяных» постов находились в момент их написания.
Об этом сообщает MIT Technology Review.

Об этом сообщает MIT Technology Review.
Fbi Detected: Как я обнаружил агентов ФБР
3 мин
В новом выпуске «Черной археологии датамайнинга» мы немного поиграемся в шпионов. Увидим, что может узнать обычный Data Specialist на основе открытых в сети данных.
Всё началось со статьи на хабре, о том, что некий анонимный хакер делился слитыми в сеть данными агентов ФБР. Я получил эти данные, и стал смотреть, что с ними можно сделать? В данных есть только фамилия, имя, и служебные мейлы и телефон – немного информации.

Получив эти данные, я увидел, что они заканчиваются буквой J. То есть, датасет не полон. Интресено, каков его полный размер? Чтобы узнать его, надо построить статистику частоты встречаемости фамилий.
Для этого я начал искать наборы американских фамилий, и тут меня ждало открытие – в Америке можно найти открытые данные по, скажем, избирателям штата – как я понял, совершенно легально. Например, я за полчаса без проблем получаю данные всех избирателей штата Юта.
Всё началось со статьи на хабре, о том, что некий анонимный хакер делился слитыми в сеть данными агентов ФБР. Я получил эти данные, и стал смотреть, что с ними можно сделать? В данных есть только фамилия, имя, и служебные мейлы и телефон – немного информации.
Получив эти данные, я увидел, что они заканчиваются буквой J. То есть, датасет не полон. Интресено, каков его полный размер? Чтобы узнать его, надо построить статистику частоты встречаемости фамилий.
Для этого я начал искать наборы американских фамилий, и тут меня ждало открытие – в Америке можно найти открытые данные по, скажем, избирателям штата – как я понял, совершенно легально. Например, я за полчаса без проблем получаю данные всех избирателей штата Юта.
Логическая витрина для доступа к большим данным
6 мин
Технологии Big Data создавались в качестве ответа на вопрос «как обработать много данных». А что делать, если объем информации не является единственной проблемой? В промышленности и прочих серьезных применениях часто приходится иметь дело с большими данными сложной и переменной структуры, разрозненными массивами информации. Встречаются задачи, способ решения которых наперед не известен, и аналитику необходимы средства исследования исходных данных или результатов вычислений на их основе без привлечения программиста. Нужны инструменты, сочетающие функциональную мощь систем BI (а лучше – превосходящие ее) со способностью к обработке огромных объемов информации.
Одним из способов получить такой инструмент является создание логической витрины данных. В этой статье мы расскажем о концепции этого решения, а также продемонстрируем программный прототип.
Одним из способов получить такой инструмент является создание логической витрины данных. В этой статье мы расскажем о концепции этого решения, а также продемонстрируем программный прототип.
Как нельзя делать рекомендации контента
9 мин
Recovery Mode
Во время общения с медиа мы в Relap.io часто сталкиваемся с массой заблуждений, в которые все верят, потому что так сложилось исторически. На сайте есть блоки типа «Читать также» или «Самое горячее» и т.п. Словом, всё то, что составляет обвязку статьи и стремится дополнить UX дорогого читателя. Мы расскажем, какие заблуждения есть у СМИ, которые делают контентные рекомендации, и развеем их цифрами.
Как Big Data используют для анализа фондового рынка
4 мин
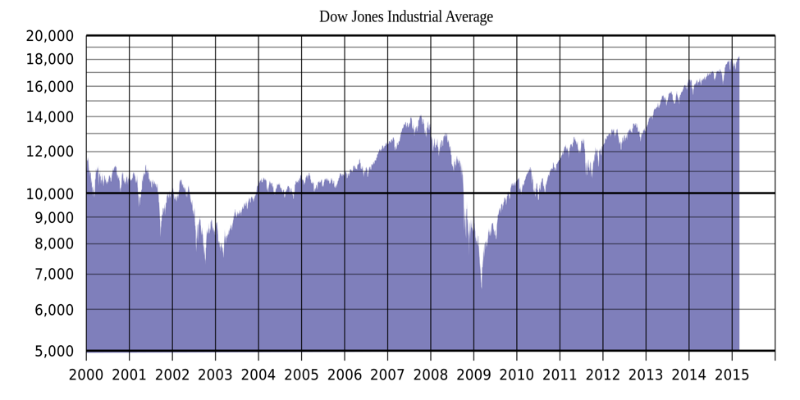
В нашем блоге мы неоднократно писали о софте для торговли на бирже различных инструментах, использующихся для анализа ситуации на фондовом рынке и создания прогнозов возможных обвалов и изменений цен (в этом материале собраны все рассмотренные алгоритмы и инструменты). Одним из самых популярных средств анализа являются различные технологии работы с Большими Данными — например, Hadoop, NoSQL.
Сегодня мы рассмотрим два эксперимента, в ходе которых исследователи применяли Big Data для создания прогнозов движений на фондовом рынке.
Как использовать Parquet и не поскользнуться
7 мин
О хранении данных в Parquet-файлах не так много информации на Хабре, поэтому надеемся, рассказ об опыте Wrike по его внедрению в связке со Spark вам пригодится.
В частности, в этой статье вы узнаете:
— зачем нужен “паркет”;
— как он устроен;
— когда стоит его использовать;
— в каких случаях он не очень удобен.
1 000 000 жилых домов России
2 мин
Есть прекрасный сайт www.reformagkh.ru. На нём можно найти, управляющую компанию, закреплённую за домом, сколько денег, на что тратится и всё такое. Но кроме этого можно узнать разные интересные вещи о нашей стране в целом, например, для каждого дома на сайте указана дата его постройки, поэтому можно посмотреть, как строилась Москва с 1900 года:
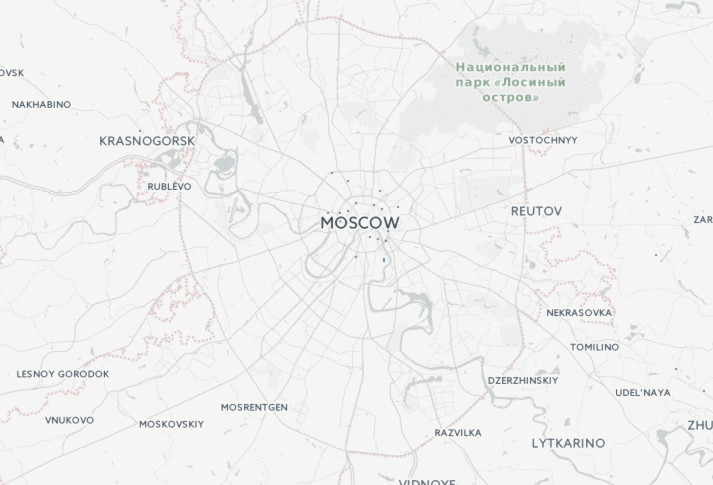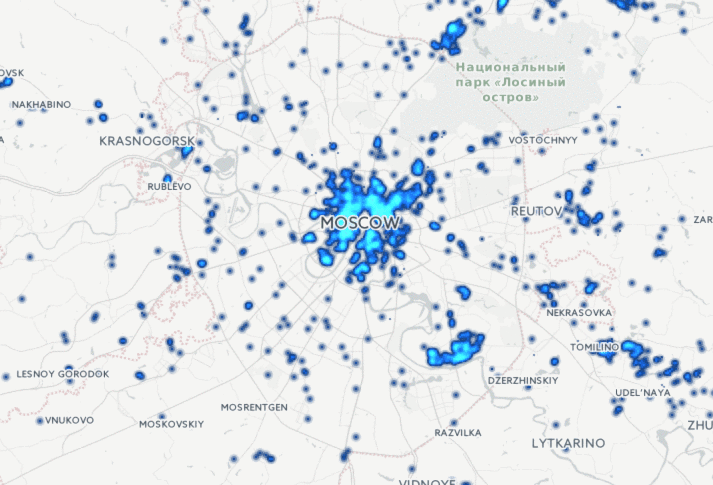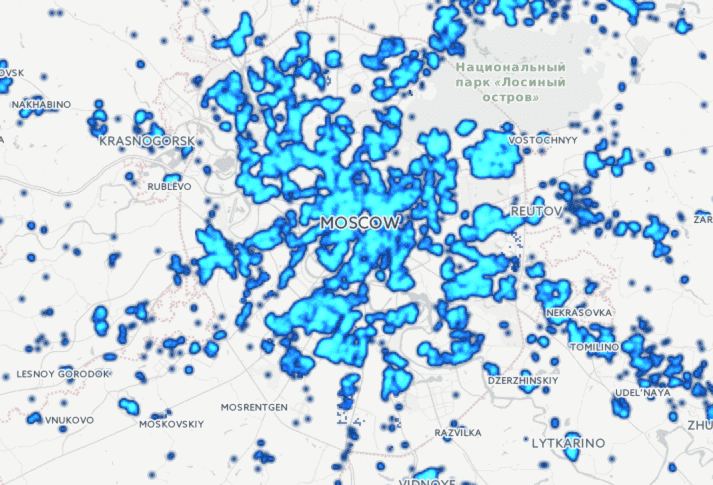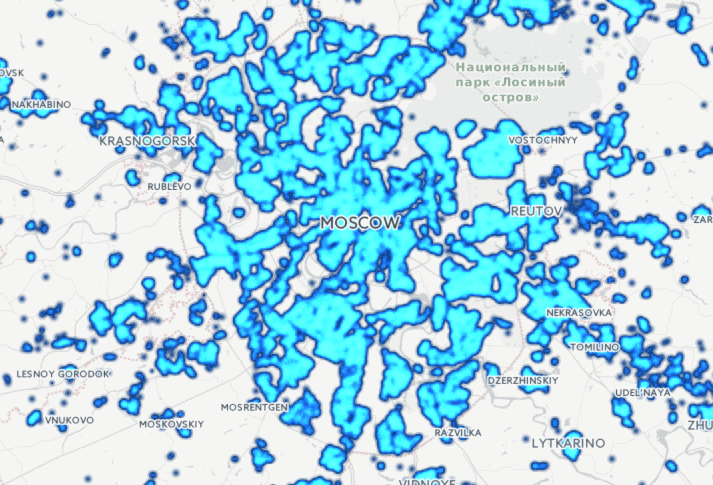
Ещё более эпичная картинка получается, если посмотреть на Россию целиком:
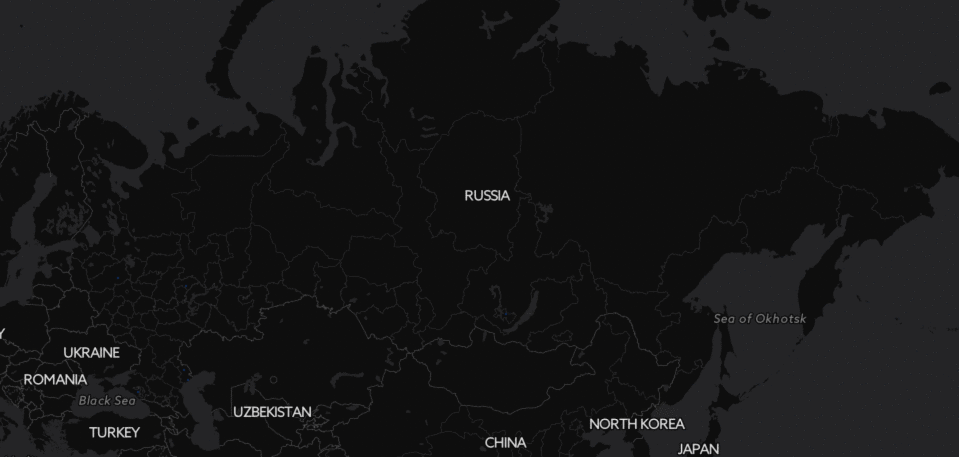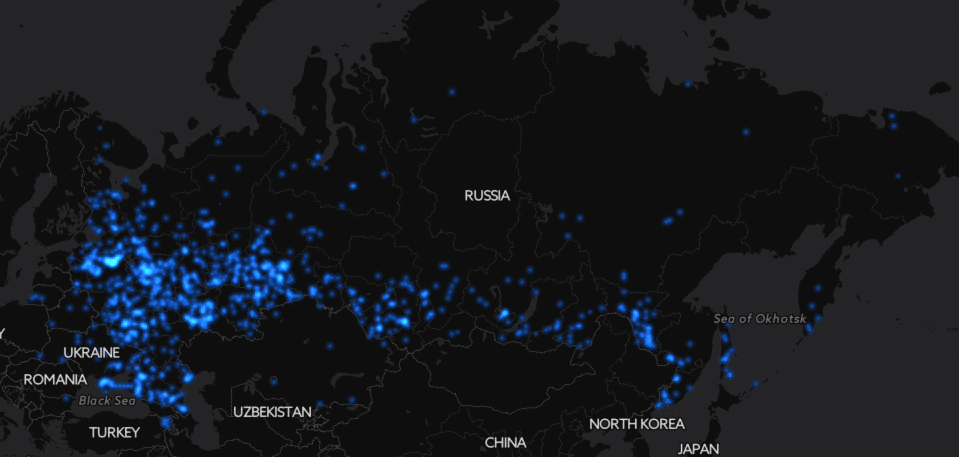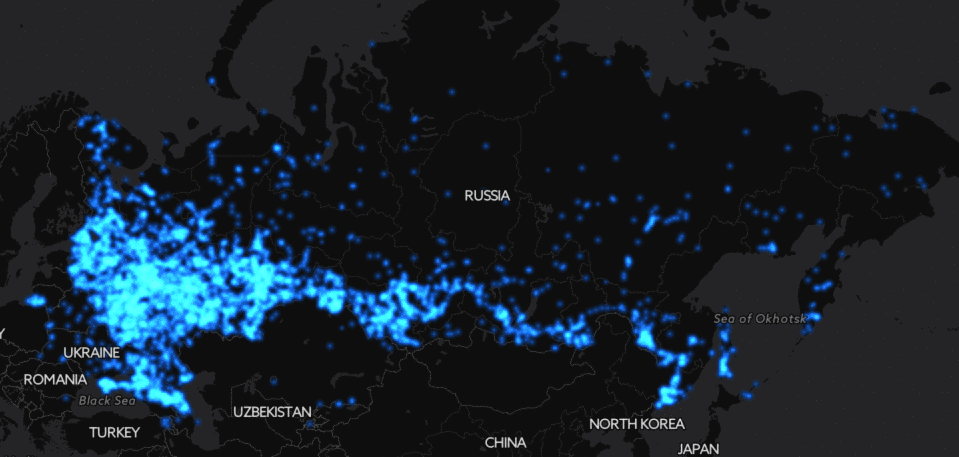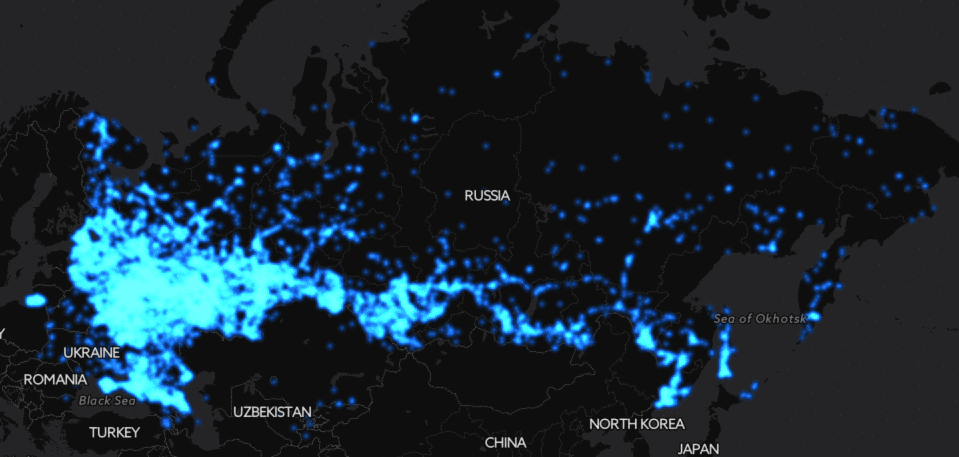
Ещё более эпичная картинка получается, если посмотреть на Россию целиком:
Ближайшие события
Строим надёжный процессинг данных — лямбда архитектура внутри Google BigQuery
5 мин
В этой статье хочу поделиться способом, который позволил нам прекратить хаос с процессингом данных. Раньше я считал этот хаос и последующий ре-процессинг неизбежным, а теперь мы забыли что это такое. Привожу пример реализации на BiqQuery, но трюк довольно универсальный.

У нас вполне стандартный процесс работы с данными. Исходные данные в максимально сыром виде регулярно подгружаются в единое хранилище, в нашем случае в BigQuery. Из одних источников (наш собственный продакшн) данные приходят каждый час, из других (обычно сторонние источники) данные идут ежедневно.
В последствии данные обрабатываются до состояния пригодного к употреблению разнообразными пользователями. Это могут быть внутренние дашборды; отчёты партнёрам; результаты, которые идут в продакшн и влияют на поведение продукта. Эти операции могут быть довольно сложными и включать несколько источников данных. Но по большей части мы с этим справляется внутри BigQuery с помощью SQL+UDF. Результаты сохраняются в отдельные таблицы там же.
У нас вполне стандартный процесс работы с данными. Исходные данные в максимально сыром виде регулярно подгружаются в единое хранилище, в нашем случае в BigQuery. Из одних источников (наш собственный продакшн) данные приходят каждый час, из других (обычно сторонние источники) данные идут ежедневно.
В последствии данные обрабатываются до состояния пригодного к употреблению разнообразными пользователями. Это могут быть внутренние дашборды; отчёты партнёрам; результаты, которые идут в продакшн и влияют на поведение продукта. Эти операции могут быть довольно сложными и включать несколько источников данных. Но по большей части мы с этим справляется внутри BigQuery с помощью SQL+UDF. Результаты сохраняются в отдельные таблицы там же.
BDRA – современная архитектура для аналитики больших данных
9 мин
Под большими данными обычно понимают серию подходов, инструментов и методов обработки структурированных и неструктурированных данных, которые отличают огромные объёмы и значительное многообразие. Цель такой обработки — получение воспринимаемых человеком результатов.

Поток данных может поступать из разных источников, эти данные гетерогенны и передаются в различных форматах: текст, документы, изображения, видео и многое другое. Для извлечения из таких данных полезной информации определяющее значение имеет программно-аппаратная платформа.
Поток данных может поступать из разных источников, эти данные гетерогенны и передаются в различных форматах: текст, документы, изображения, видео и многое другое. Для извлечения из таких данных полезной информации определяющее значение имеет программно-аппаратная платформа.
Анализ результатов выборов в Госдуму. Готовимся к голосованию 2016 года
3 мин
Выборы в Государственную думу только осенью, но мы уже начинаем готовиться. Если повторится история 2011 года, будет очень интересно. Наверное, многие помнят, как сразу после тех выборов появилась куча статистических исследований, намекающих на фальсификации и как все узнали, как выглядит распределение Гаусса. Я хотел бы рассказать, где искать данные про выборы и как с ними работать. Кроме хорошо известных графиков я покажу некоторые другие прикольные картинки, которых раньше в паблике не видел. Так, например, выглядит распределение голосов за Единую Россию по стране, хорошо видны регионы с максимальной поддержкой партии власти — Северный Кавказ и Татарстан:
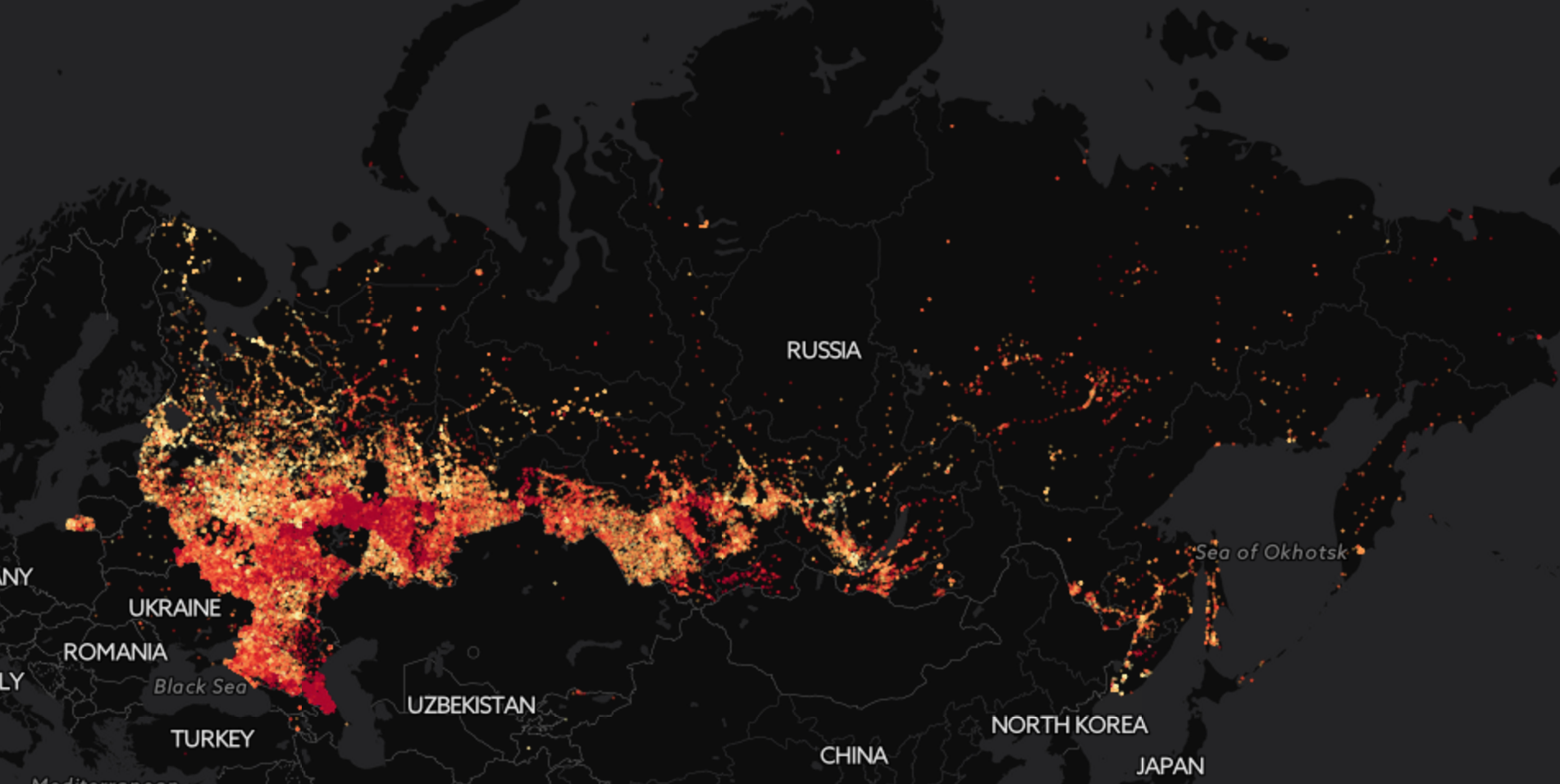
Есть такой замечательный сайт izbirkom.ru. Его здесь даже недавно упоминали в контексте, что, типа, на него потратили слишком много денег. Но лично мне не жалко, сайт прекрасный:
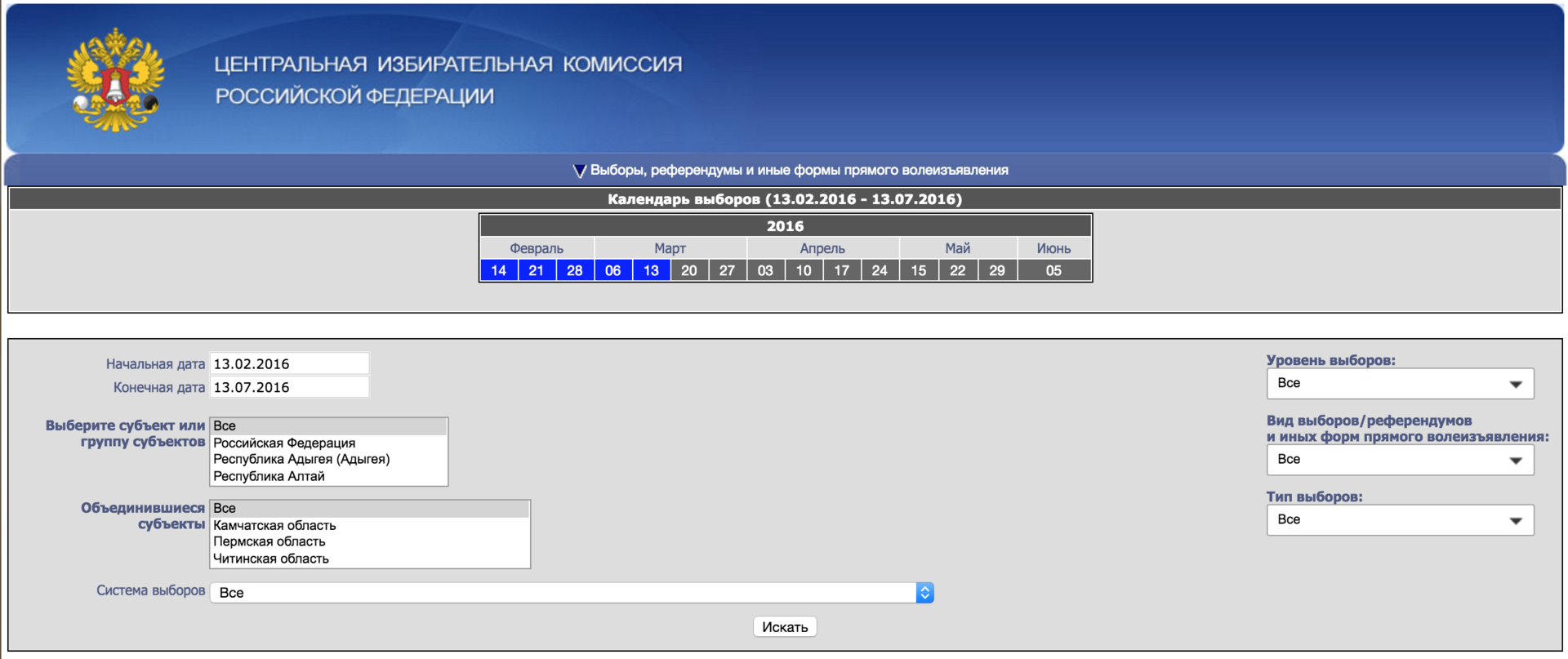
Есть такой замечательный сайт izbirkom.ru. Его здесь даже недавно упоминали в контексте, что, типа, на него потратили слишком много денег. Но лично мне не жалко, сайт прекрасный:
А нужно ли знать программисту алгоритмы?
3 мин
Не встречали еще разработчика, который вместо стандартной в скриптовом языке функции деления строки по регулярке — пишет C-подобный код с конечным автоматом, который вводит неокрепшие умы в трепет?
И так ужасно ли то, что ты не знаешь в тонкостях работу красно-черных деревьев или путаешь линейный дискриминантный анализ с вторым законом Ньютона?
И так ужасно ли то, что ты не знаешь в тонкостях работу красно-черных деревьев или путаешь линейный дискриминантный анализ с вторым законом Ньютона?
Эксперимент: Использование Google Trends для прогнозирования обвалов фондового рынка
4 мин

В нашем блоге на Хабре мы уже рассказывали о различных исследованиях, направленных на создание алгоритмов прогнозирования цен акций, к примеру, с помощью машинного обучения. Еще в 2013 году исследователи из бизнес-школы Уорика (Warwick Business School) опубликовали результаты эксперимента, в ходе которого в качестве инструмента для прогнозирования трендов фондового рынка использовался поисковик Google.
В эпоху интернета огромное количество генерируемой людьми информации доступно онлайн. И из этого шума вполне можно вычленить и нечто полезное. Исследователи убеждены, что в анализе тенденций фондового рынка можно использовать информацию о поисковых запросах.
Знакомьтесь, линейные модели
10 мин
Машинное обучение шагает по планете. Искусственный интеллект, поскрипывая нейронными сетями, постепенно опережает людей в тех задачах, до которых успел дотянуться своими нейронами. Однако не стоит забывать и про простую модель линейной регрессии. Во-первых, потому что на ней построены многие сложные методы машинного обучения, включая нейронные сети. А, во-вторых, потому что зачастую прикладные бизнес-задачи легко, быстро и качественно решаются именно линейными моделями.
И для начала небольшой тест. Можно ли с помощью линейной модели описать:
— зависимость веса человека от его роста?
— длительность ожидания в очереди в магазине в разное время суток?
— посещаемость сайта в фазе экспоненциального роста?
— динамику во времени количества человек, ожидающих поезда на станции метро?
— вероятность, что клиент не оформит заказ на сайте в зависимости от его производительности?
Как вы догадываетесь, на все вопросы ответ будет «Да, можно». Так что линейные модели не так просты, как может показаться на первый взгляд. Поэтому давайте познакомимся с их богатым разнообразием.
И для начала небольшой тест. Можно ли с помощью линейной модели описать:
— зависимость веса человека от его роста?
— длительность ожидания в очереди в магазине в разное время суток?
— посещаемость сайта в фазе экспоненциального роста?
— динамику во времени количества человек, ожидающих поезда на станции метро?
— вероятность, что клиент не оформит заказ на сайте в зависимости от его производительности?
Как вы догадываетесь, на все вопросы ответ будет «Да, можно». Так что линейные модели не так просты, как может показаться на первый взгляд. Поэтому давайте познакомимся с их богатым разнообразием.
IBM и X Prize Foundation объявили конкурс по искусственному интеллекту с призовым фондом в $5 млн
2 мин

Корпорация IBM вместе с организацией X Prize Foundation объявили конкурс Watson AI XPRIZE Cognitive Computing Competition. О старте конкурса объявили Дэвид Кенни (David Kenny), руководитель проекта IBM Watson, и Питер Диамандис (Peter Diamandis), председатель Фонда XPRIZE. Изначальная цель конкурса — использование искусственного интеллекта для выполнения прикладных задач, включая решение актуальных для человека проблем. К участию планируется привлечь команды разработчиков со всего мира.
Итоговая цель — объединение творческих умов в единое целое, создание команды, которая сможет генерировать креативные идеи, предлагать пути решения самых разных задач и проблем в медицине, промышленности, научной сфере, бизнесе. У Фонда XPRIZE в плане проведения конкурсов огромный опыт, поэтому IBM и решила объединить усилия с этой организацией.