
Организация рабочих потоков: синхронизационный канал
7 мин
Представьте себе архитектуру типичного приложения:
Есть рабочий поток движка, выполняющий какую-то функциональность, допустим копирование файлов (архивирование, поиск простых чисел). В общем что-то длительное.
Данный поток должен периодически сообщать информацию о текущем копируемом файле, а также уметь обрабатывать ошибки, допустим ошибка нехватки места на диске.
Графический интерфейс такого приложения должен позволять запускать процесс копирования файлов, уметь приостановить копирование, а также, в случае ошибки, отобразить соответствующий диалог с вопросом к пользователю.
Казалось бы, как можно допустить ошибку в такой простой ситуации?
Есть рабочий поток движка, выполняющий какую-то функциональность, допустим копирование файлов (архивирование, поиск простых чисел). В общем что-то длительное.
Данный поток должен периодически сообщать информацию о текущем копируемом файле, а также уметь обрабатывать ошибки, допустим ошибка нехватки места на диске.
Графический интерфейс такого приложения должен позволять запускать процесс копирования файлов, уметь приостановить копирование, а также, в случае ошибки, отобразить соответствующий диалог с вопросом к пользователю.
Казалось бы, как можно допустить ошибку в такой простой ситуации?
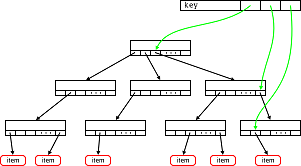 Этот топик повествует об использовании Radix Tree на практическом примере.
Этот топик повествует об использовании Radix Tree на практическом примере. 
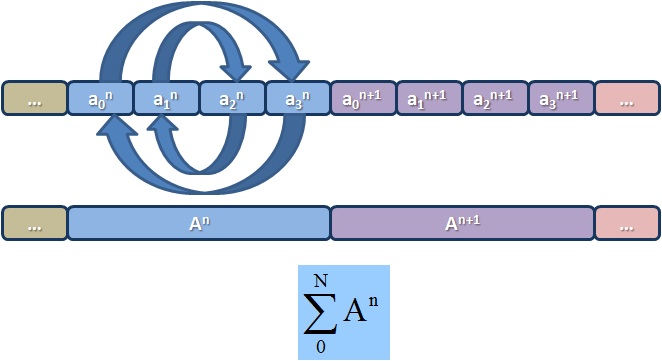
 До появления gccxml, был только один способ извлечь мета-информацию из Си/
До появления gccxml, был только один способ извлечь мета-информацию из Си/ В продолжение темы
В продолжение темы 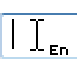 Тема отображения текущей раскладки беспокоила хабрасообщество
Тема отображения текущей раскладки беспокоила хабрасообщество