Совсем скоро в онлайне стартует SmartData 2021. По названию конференции уже понятно, что она посвящена работе с данными, но не все так просто. Это достаточно обширная тема, в которой можно заниматься совершенно разными вещами. SmartData затрагивает конкретную часть домена «Работа с данными» — дата-инжиниринг. Тут можно услышать про СУБД, архитектуру DWH, MLOps и многое другое, с чем сталкиваются дата-инженеры.
Среди наших спикеров есть и люди из академической среды (Энди Павло), те, кто имеет дело с огромным количеством данным (Теджас Чопра из Netflix), топовый контрибьютор популярнейшего оркестратора Airflow (Эш Берлин-Тейлор) и многие другие профессиональные дата-инженеры и архитекторы.
Темы докладов будут самые разнообразные: как заниматься йогой со Spark, какие бывают инженеры данных, как масштабировать аналитику, совладать с ClickHouse без ущерба для здоровья, оптимизировать повседневные задачи с помощью ML и так далее.
Но не докладами едиными: будет ещё и два воркшопа, где зрители не внимают теоретическим знаниям со слайдов, а перенимают у спикера практические навыки работы с чем-то. А в финале конференции будет круглый стол об альтернативах Hadoop.
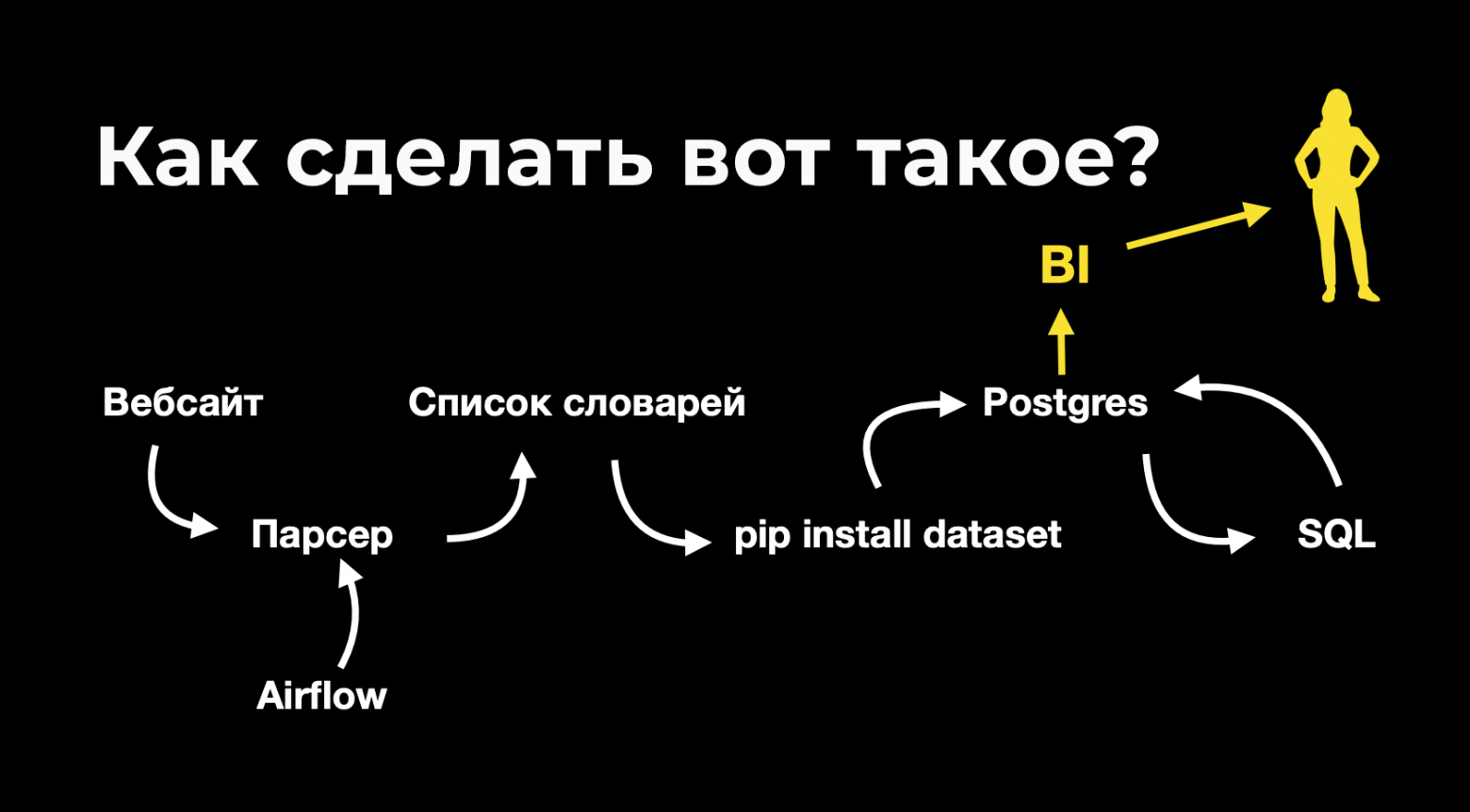
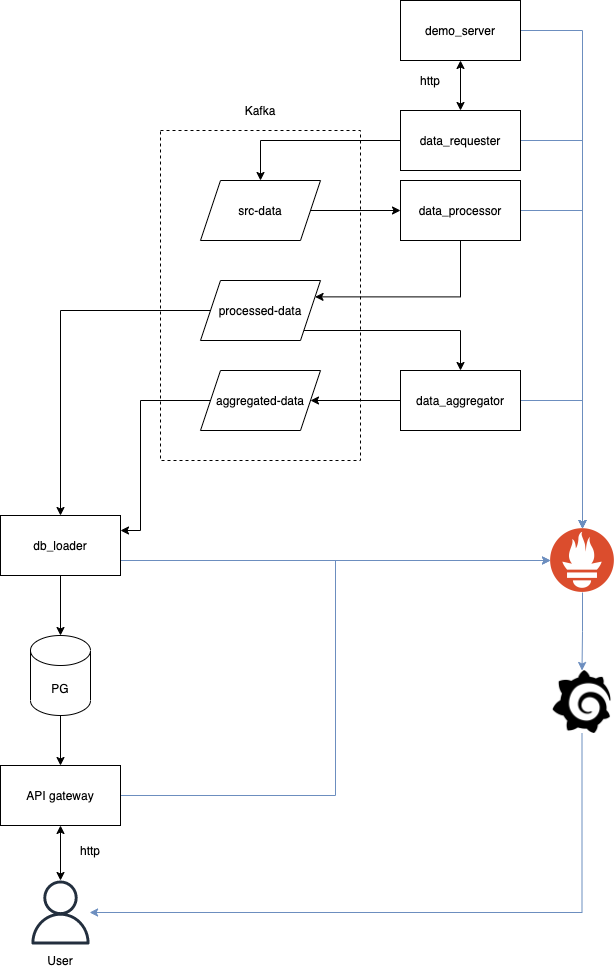
Под катом — детальный обзор программы, для вашего удобства поделённый на тематические блоки (инструменты, процессы, архитектура и т.д.).