Сериал: Big Data — как мечта. Незапланированная 5-я серия: Большая игра. Частное мнение
4 мин
Recovery Mode
В предыдущих сериях: Big Data — это не просто много данных. Big Data — процесс с положительной обратной связью. «Кнопка Обамы» как воплощение rtBD&A. Философия развития Big Data.
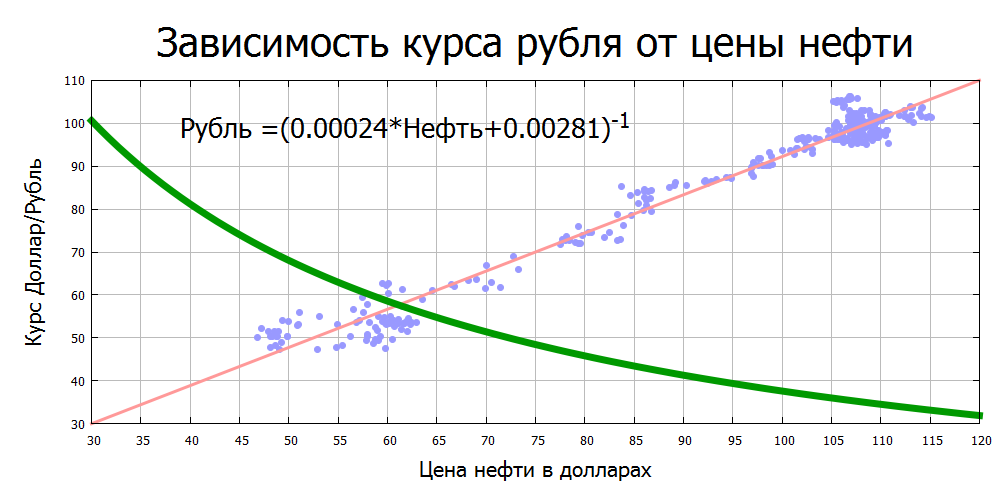
11 апреля Twitter объявил о прекращении контракта с DataSift. Казалось бы, ну и что? Фактически это означает начало Большой Игры, результаты которой можно сравнить с III Мировой. Звучит жутковато? Давайте расставим фигуры на доске и посмотрим.
11 апреля Twitter объявил о прекращении контракта с DataSift. Казалось бы, ну и что? Фактически это означает начало Большой Игры, результаты которой можно сравнить с III Мировой. Звучит жутковато? Давайте расставим фигуры на доске и посмотрим.
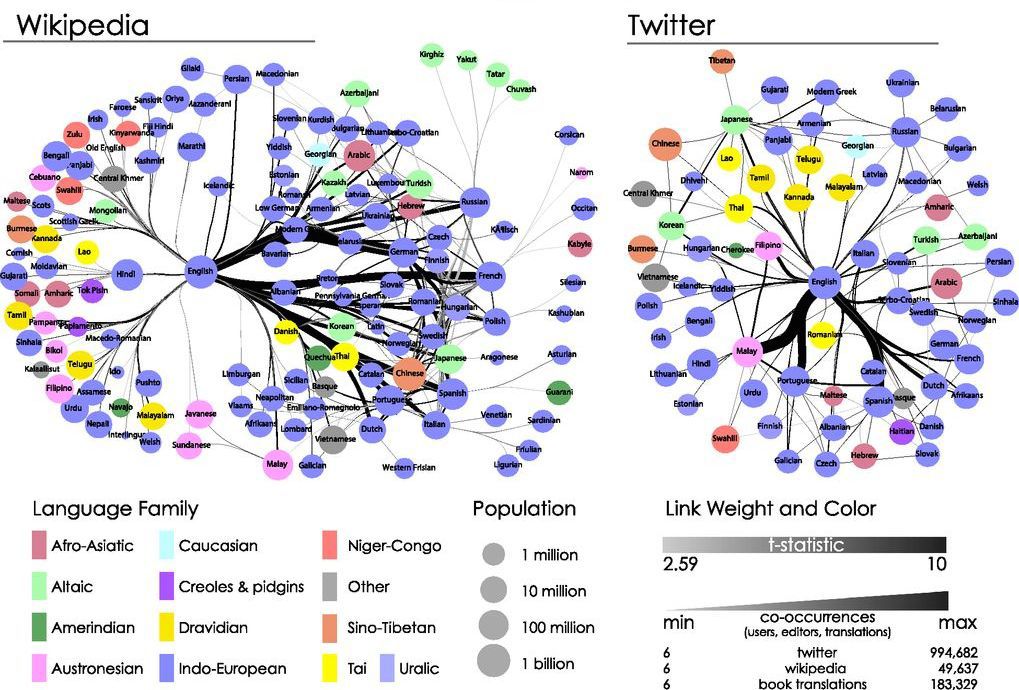
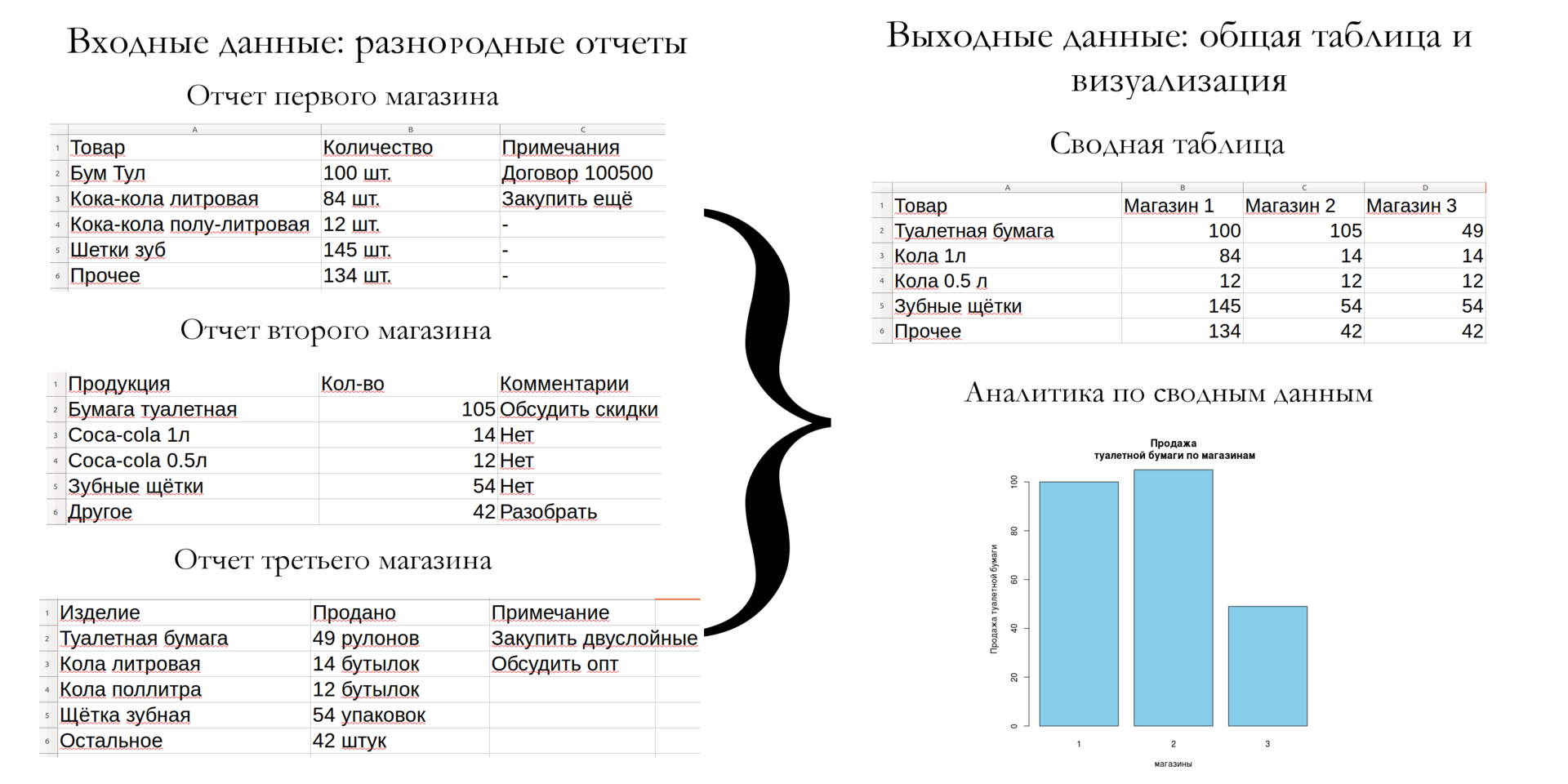


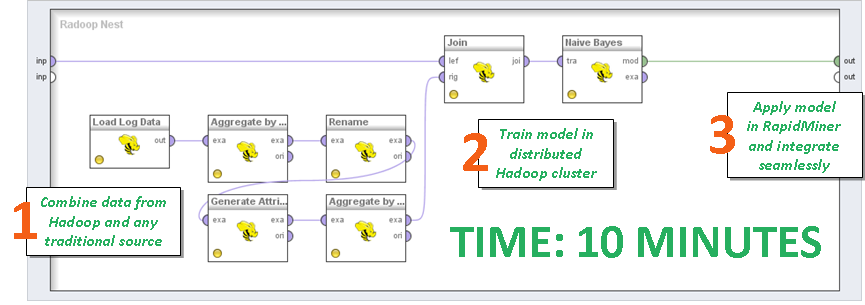

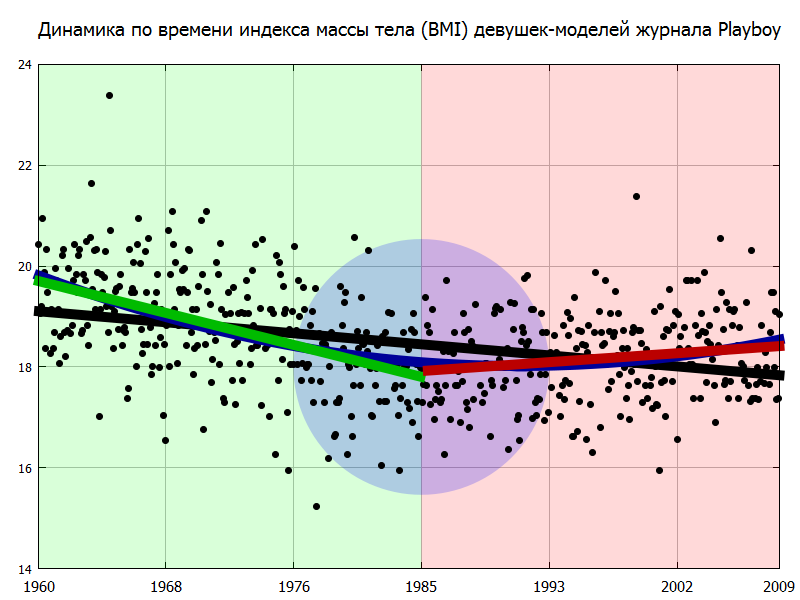
 Привет, Хабр, давно не виделись. В этом посте мне хотелось бы рассказать о таком относительно новом понятии в машинном обучении, как
Привет, Хабр, давно не виделись. В этом посте мне хотелось бы рассказать о таком относительно новом понятии в машинном обучении, как