
Если вы не понимаете, что такое DevOps, то вот краткая шпаргалка. DevOps — это набор практик, которые уменьшают страхи инженеров и сокращают количество сбоев в производстве ПО. Как правило, они же сокращают время выхода на рынок — период от идеи до доставки конечного продукта до клиентов, что позволяет быстро проводить бизнес-эксперименты.
Как начать DevOps трансформацию? Если кратко: выбираем сервис, с которого начнем процесс, выявляем тех, кто имеет отношение к сервису, строим Value Stream Map, создаем временную команду, которая будет заниматься трансформацией первое время и ставим ей задачу. Повторяем цикл нужное число раз.

Подробный план DevOps трансформации с примерами и инструкциями под катом — в расшифровке доклада Андрея Александрова — инженера в компании Express42, которая консультирует по проращиванию DevOps, ускоряя этот процесс, потому что уже построила карту граблей. Если вам кажется, что трансформация вам не нужна, или у вас такая специфика, что DevOps-практики не подходят, — используйте доклад как инструкцию по поиску и устранению ограничений.
Как начать DevOps трансформацию? Если кратко: выбираем сервис, с которого начнем процесс, выявляем тех, кто имеет отношение к сервису, строим Value Stream Map, создаем временную команду, которая будет заниматься трансформацией первое время и ставим ей задачу. Повторяем цикл нужное число раз.
Подробный план DevOps трансформации с примерами и инструкциями под катом — в расшифровке доклада Андрея Александрова — инженера в компании Express42, которая консультирует по проращиванию DevOps, ускоряя этот процесс, потому что уже построила карту граблей. Если вам кажется, что трансформация вам не нужна, или у вас такая специфика, что DevOps-практики не подходят, — используйте доклад как инструкцию по поиску и устранению ограничений.
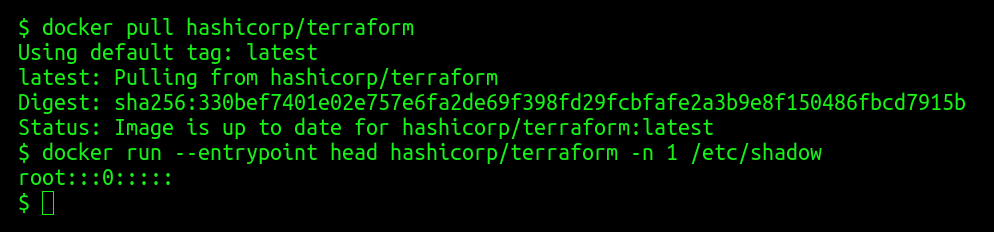














{kind=link}