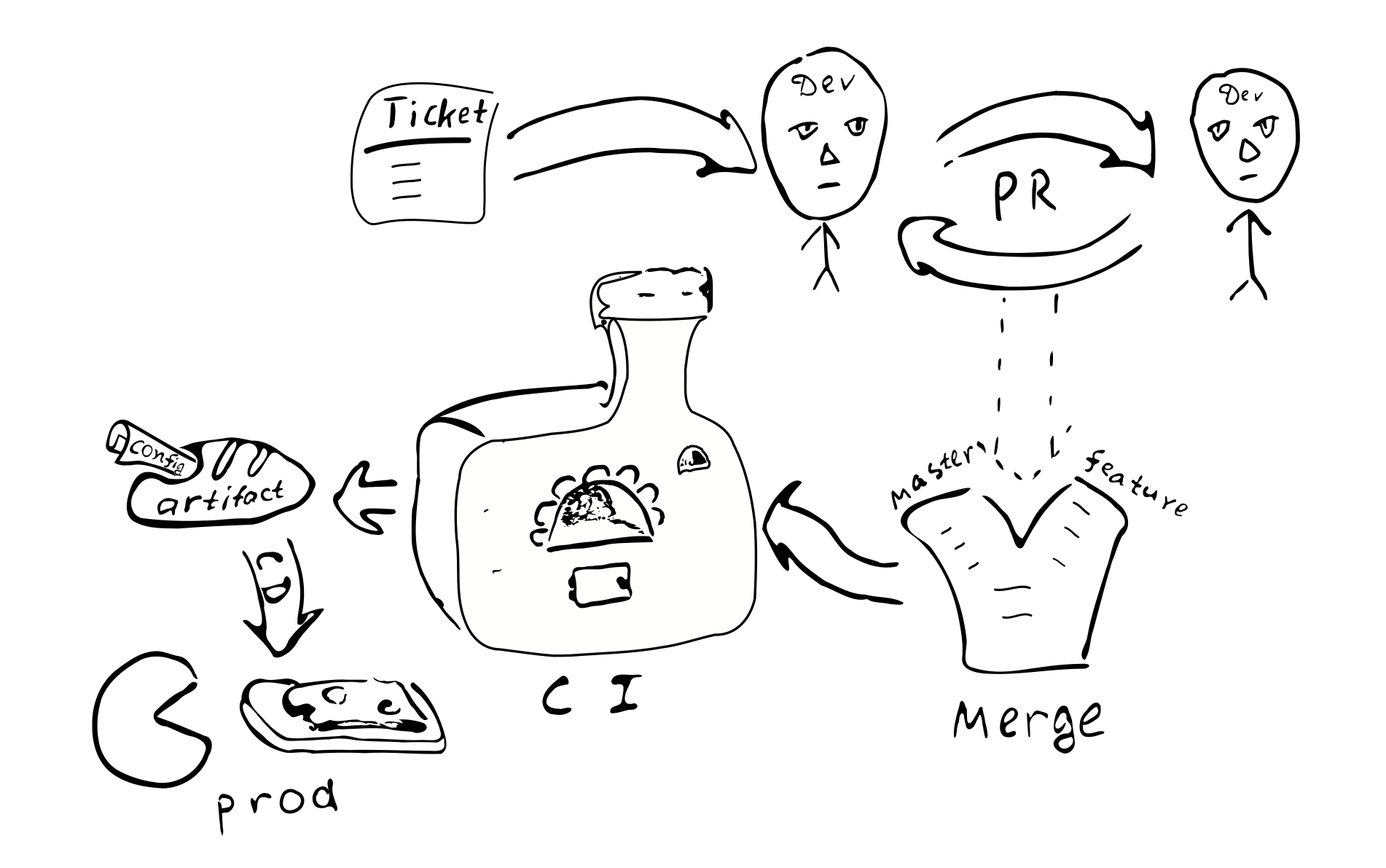
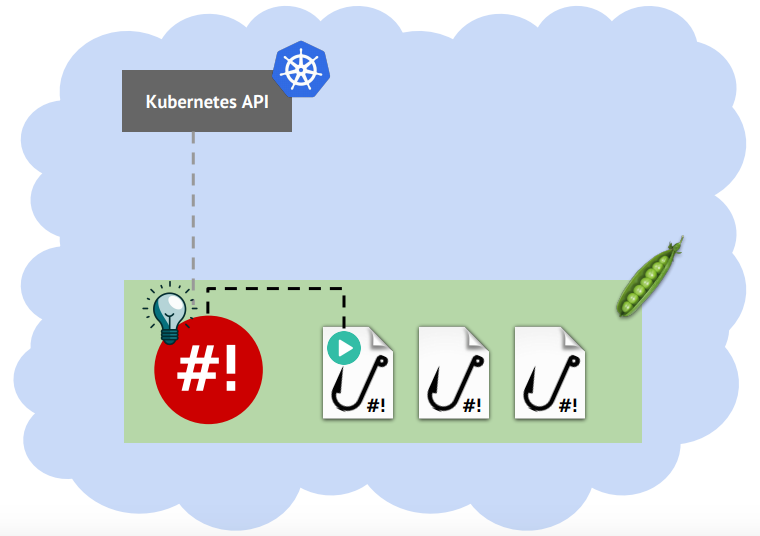
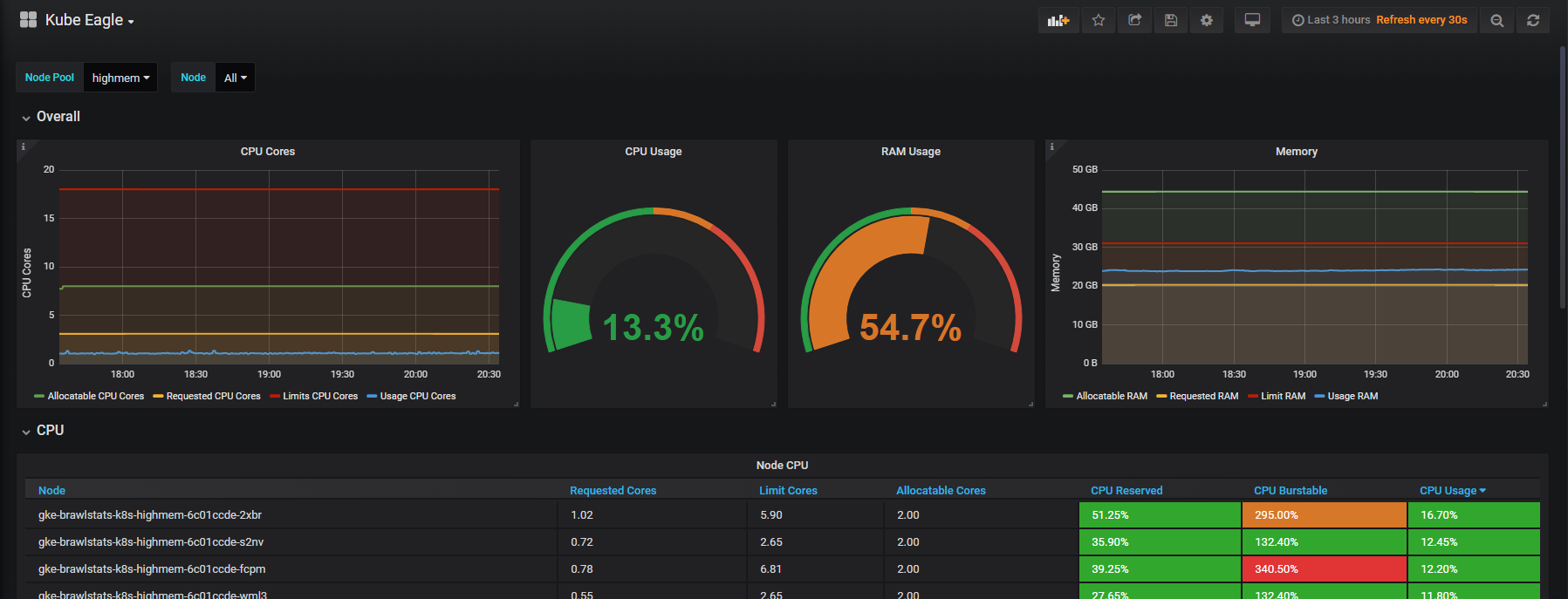
Нас все чаще спрашивают про разработку микросервисов в Kubernetes. Разработчики, особенно интерпретируемых языков, хотят быстро поправить код в любимой IDE и без ожидания сборки/деплоя увидеть результат — по простому нажатию на F5. И когда речь шла про монолитное приложение, достаточно было локально поднять базу данных и веб-сервер (в Docker, VirtualBox…), после чего — сразу же наслаждаться разработкой. С распиливанием монолитов на микросервисы и приходом Kubernetes, с появлением зависимостей друг от друга, всё стало немного сложнее. Чем больше этих микросервисов, тем больше проблем. Чтобы вновь насладиться разработкой, нужно поднять уже не один и не два Docker-контейнера, а иногда — даже не один десяток… В общем, на всё это может уходить достаточно много времени, поскольку требуется ещё и поддерживать в актуальном состоянии.