
Нет времени и желания изучать километровые файлы WiX, чтобы собрать MSI инсталлер для своего проекта, погружаясь при этом в бездны MSDN? Хотите собирать инсталлер, описывая его простыми и понятными терминами, в несколько строк? Есть клиническая склонность к кроссплатформенности и сборкам под Linux & Docker? Ну тогда вам под кат!
Встреча с DevOps Deflope на конференции DevOpsConf 2018
2 мин
Мы долго думали, как разнообразить нашу конференцию и внести в неё элемент спонтанности и тут к нам пришла идея: было бы здорово что-то сделать с ребятами, которые уже много лет снабжают нас новостями о DevOps. Это ребята из новостного канала и подкаста DevOps Deflope, которые на русском языке рассказывают о том, что происходит в российских компаниях по DevOps тематике.
Мы решили устроить гибридный выпуск DevOps Deflope в формате BoF (Birds of a Feather) прямо на конференции. Это будет встреча, на которой мы с прошлыми и нынешними ведущими DevOps Deflope обсудим новости индустрии и просто поговорим.
Я обсудил с Никитой Борзых, одним из идеологов и первых ведущих подкаста, эту идею и вот, что он мне рассказал.
Мы решили устроить гибридный выпуск DevOps Deflope в формате BoF (Birds of a Feather) прямо на конференции. Это будет встреча, на которой мы с прошлыми и нынешними ведущими DevOps Deflope обсудим новости индустрии и просто поговорим.
Я обсудил с Никитой Борзых, одним из идеологов и первых ведущих подкаста, эту идею и вот, что он мне рассказал.
29-31 октября: создаем production-ready кластер Kubernetes
2 мин

Southbridge проводит живой и онлайн-интенсив по Кубернетес.
Материал рассчитан на тех, кто знает Linux, Docker, Kubernetes, Ansible, Helm и Git.
Интенсив — в первую очередь практика. Каждый участник создаст свой кластер в облаке Selectel.
Теоретическая часть — это не пересказ мануалов, а опыт и рекомендации спикеров.
Темы занятий:
Сокращение расходов на AWS при использовании Kubernetes Ingress с классическим балансировщиком ELB
3 мин
Перевод

Несколько месяцев назад я написал статью о контроллере Kubernetes Nginx Ingress, которая занимает второе место по популярности в этом блоге. Основная ее тема — использование Kubernetes Ingress для локальных развертываний. Впрочем, большинство пользователей использует Kubernetes в облаке AWS и общедоступных облачных сервисах других поставщиков. Однако проблема заключается в том, что для каждого сервиса типа LoadBalancer AWS создает новый балансировщик ELB (Elastic Load Balancer). Это может оказаться слишком дорогим удовольствием. Если взять на вооружение Kubernetes Ingress, потребуется лишь один ELB.
«Kubernetes во все поля!» – интервью с программным комитетом конференции DevOops
15 мин
Раньше докер был крутым, молодежным, вещью в себе. А потом как-то докер перестал быть интересен: он просто есть, он у всех и во всем. На нем все микросервисы, Kubernetes, девопс — всё, что угодно. Вместе с тем, люди тащат контейнеры себе в рот откуда ни попадя. Они часто даже не знают, что там лежит внутри.
Что же теперь интересно DevOps-инженерам? Команда супергероев — программный комитет конференции DevOops — попалась в дьявольскую ловушку в Hangouts и целый час отвечала на вопросы. (Кто все эти люди — подробно написано по ссылке).
Под катом — интервью, раскрашенное цветными мелками. У каждого эксперта — свой цвет:

Что же теперь интересно DevOps-инженерам? Команда супергероев — программный комитет конференции DevOops — попалась в дьявольскую ловушку в Hangouts и целый час отвечала на вопросы. (Кто все эти люди — подробно написано по ссылке).
Под катом — интервью, раскрашенное цветными мелками. У каждого эксперта — свой цвет:
Приезжайте изучать классическое администрирование: регламенты, инструменты, скрипты Southbridge
4 мин
За 10 лет Southbridge создал стандарт работы, который позволяет одному администратору поддерживать 150 серверов, быстро проводить первичную настройку, легко передавать проект между администраторами и группами, сразу видеть, что сделали ночные дежурные, быстро входить в курс дела после отпуска, и, естественно, обеспечить клиенту надежность и безопасность инфраструктуры.
C 22 по 24 октября Southbridge проводит интенсив для системных администраторов, где покажет свои подходы, регламенты, инструменты, инструкции и скрипты.

По сути РедСлёрм — это набор материалов для подготовки нового сотрудника Southbridge.
Осваивать подход к администрированию, основанный на унификации и стандартизации, полезно даже начинающему администратору.
Все, что можно, отрабатываем на практике.
Создание пакетов для Kubernetes с Helm: структура чарта и шаблонизация
14 мин

Про Helm и работу с ним «в общем» мы рассказали в прошлой статье. Теперь подойдём к практике с другой стороны — с точки зрения создателя чартов (т.е. пакетов для Helm). И хотя эта статья пришла из мира эксплуатации, она получилась больше похожей на материалы о языках программирования — такова уж участь авторов чартов. Итак, чарт — это набор файлов…
Резервное копирование и восстановление ресурсов Kubernetes утилитой Heptio Ark
4 мин
Перевод
Вам наверняка приходилось восстанавливать кластер Kubernetes после сбоя. Была ли у вас толковая стратегия резервного копирования, не требующая пахать несколько дней? Да, можно делать резервные копии в etcd-кластер, но что если отвалилась только часть кластера или вы используете постоянные тома, вроде AWS EBS?
В таких случаях проще всего использовать утилиту Heptio Ark.
Анатомия инцидента, или как работать над уменьшением downtime
8 мин
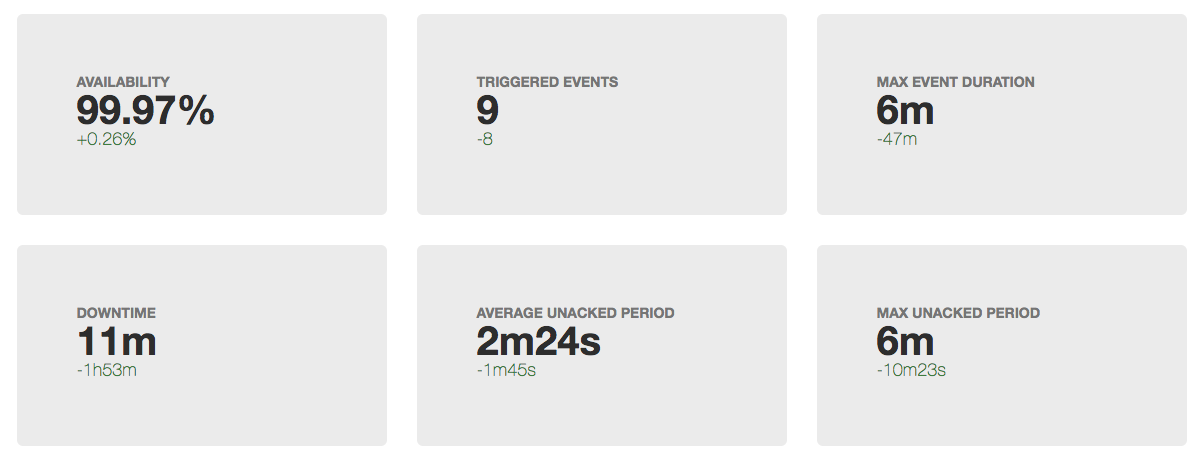
Рано или поздно в любом проекте настает время работать над стабильность/доступностью вашего сервиса. Для каких-то сервисов на начальном этапе важнее скорость разработки фич, в этот момент и команда не сформирована полностью, и технологии выбираются не особо тщательно. Для других сервисов (чаще технологические b2b) для завоевания доверия клиентов необходимость обеспечения высокого uptime возникает с первым публичным релизом. Но допустим, что момент X все-таки настал и вас начало волновать, сколько времени в отчетный период "лежит" ваш сервис. Под катом я предлагаю посмотреть, из чего складывается время простоя, и как эффективнее всего работать над его уменьшением.
Нужно поднимать Kubernetes кластер, но я всего лишь программист кода. Выход есть
8 мин
Туториал
Доброго времени суток. Очередная заметка из моего опыта. В этот раз поверхностно о базовой инфраструктуре, которую использую, если надо что-то выгрузить, а рядом нет devOps ребят. Но текущий уровень абстракции, в технологиях, позволяет уже около года жить с этой инфраструктурой, поднятой за ночь, используя интернет и готовые вещи.
Ключевые слова — AWS + Terraform + kops . Если это полезно мне — возможно будет полезно кому-нибудь еще. Добро пожаловать в комментарии.
Как подружить PHPstorm, xDebug и удаленные ветки, собранные через Docker? Слишком просто…
6 мин
Туториал
Доброго времени суток, Хабр!
Еще год назад мой процесс отладки кода в PHP заключался в двух строчках:
Периодически, конечно, приходилось использовать более «сложные» конструкции:
Нет, что вы! Я знал — в наше время не подобает культурному программисту заниматься этим
Но, честно говоря, я всегда боялся того, что не понимаю. В том числе ипринтеров xDebug, в особенности, как все это дело настроить. В один прекрасный день у меня получилось это сделать на своей машине и в локальном проекте — радости не было предела. Спустя много месяцев я столкнулся с новой проблемой, как заниматься отладкой в PHPstorm через xDebug, если проект собирается удаленно докером через CI.
Если Вы так же, как и я, испытываете трудности с настройкой разных штук, добро пожаловать под кат, я расскажу о своем опыте настройки окружения отладки с такими страшными словами, как Docker, xDebug, CI.
Еще год назад мой процесс отладки кода в PHP заключался в двух строчках:
var_dump($variable);
die();Периодически, конечно, приходилось использовать более «сложные» конструкции:
console.log(data);
echo json_encode($variable, JSON_UNESCAPED_UNICODE);
exit();Нет, что вы! Я знал — в наше время не подобает культурному программисту заниматься этим
древним ремеслом
шутка про другое древнейшее ремесло
Но, честно говоря, я всегда боялся того, что не понимаю. В том числе и
Если Вы так же, как и я, испытываете трудности с настройкой разных штук, добро пожаловать под кат, я расскажу о своем опыте настройки окружения отладки с такими страшными словами, как Docker, xDebug, CI.
Новая статистика CNCF о контейнерах, cloud native и Kubernetes
5 мин
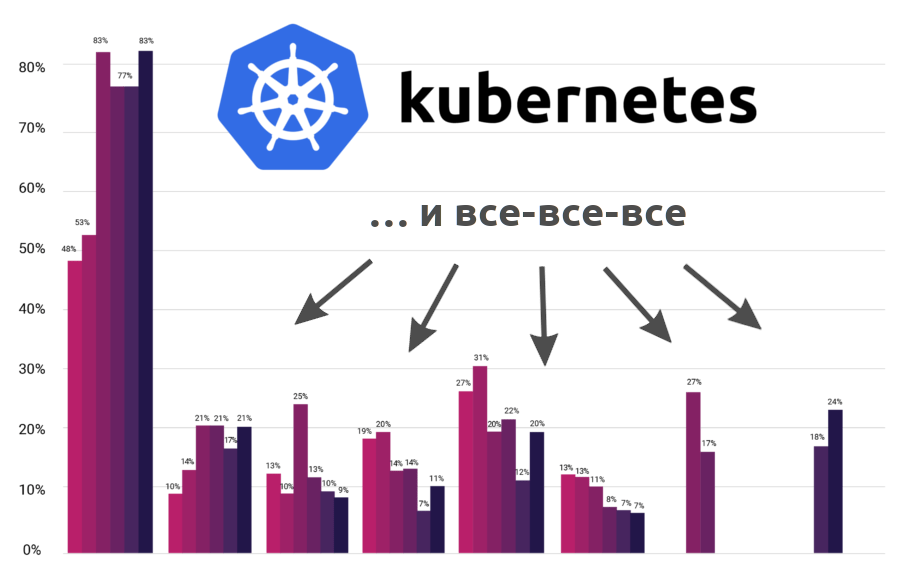
Некоммерческая организация CNCF (Cloud Native Computing Foundation), стоящая за Kubernetes и другими инфраструктурными Open Source-проектами для современных облачных приложений, представила результаты своего очередного опроса, который проводится дважды в год. На вопросы, посвящённые адаптации cloud native-технологий, ответили 2400 человек, более половины из которых используют Kubernetes в production.
А чтобы статистика от CNCF была шире и интереснее, я дополнил её результаты данными от других организаций…
Октябрьский Слерм: интенсив по Кубернетес
2 мин
Для тех, кто хочет освоить Кубернетес или углубить свои знания, в конце октября проходит Слёрм. На Слёрме каждый теоретический блок отрабатывается на практике: участники разворачивают кластер Kubernetes в облаке, настраивают и траблшутят его, обеспечивают его надежность и безопасность.

Слёрм-2 (25–27 октября) — для тех, кто только осваивает Кубернетес: создаем кластер и запускаем на нем приложение.
МегаСлёрм (29–31 октября) — для тех, кто уже работает с Кубернетес или был на Слёрм-1: создаем production-ready кластер.
Темы Слерм-2 и МегаСлерм включают все темы экзамена на Certified Kubernetes Administrator.
Ближайшие события
Управление микросервисами с помощью Kubernetes и Istio
12 мин
Небольшой рассказ о преимуществах и недостатках микросервисов, концепции Service Mesh и инструментах Google, позволяющих запускать микросервисные приложения не засоряя голову бесконечными настройками политик, доступов и сертификатов и быстро находить ошибки, прячущиеся не в коде, а в микросервисной логике.

В основе статьи — доклад Крейга Бокса на нашей прошлогодней конференции DevOops 2017. Видео и перевод доклада — под катом.
В основе статьи — доклад Крейга Бокса на нашей прошлогодней конференции DevOops 2017. Видео и перевод доклада — под катом.
27 сентября, Москва – Митап QIWI SERVER PARTY 3.0
1 мин
Привет, Хабр!
27 сентября, в четверг, мы снова решили собрать митап QIWI SERVER PARTY.

Если вам интересны DevOps и работа с Kubernetes, то добро пожаловать под кат, там мы собрали темы докладов, с которым будут выступать наши ребята, и видео с предыдущего митапа.
27 сентября, в четверг, мы снова решили собрать митап QIWI SERVER PARTY.
Если вам интересны DevOps и работа с Kubernetes, то добро пожаловать под кат, там мы собрали темы докладов, с которым будут выступать наши ребята, и видео с предыдущего митапа.
Присматриваемся к инструментам для мониторинга распределенных приложений
4 мин
Когда приложение было монолитным и вдруг, раз, стало распределённым, в формулу вычисления доступности добавляется ещё одна неизвестная — сетевая. Из-за проблем с вызовами между компонентами, приложения часто валятся и начинают дрыгать ножками. А выяснение причин нестабильной работы распределённого приложения — та ещё задачка. Дополнительную неразбериху в структуру приложения вносит условный kubernetes, который по своему внутреннему усмотрению может произвольно распределять условные поды по условным нодам. Пишу «условный», потому что на месте kubernetes может быть и Swarm и Openshift и прочие и прочие.
Я к тому, что без нормальной визуализации разобраться где температурит, может быть очень непросто. Под катом моё представление о потенциальных возможностях инструментов, которые умеют рисовать карту приложения и подсвечивать места для прикладывания подорожника, а также список этих самых инструментов со скриншотами.
Клуб анонимных любителей DevOps
6 мин
Каждый вторник по вечерам собирается клуб анонимных любителей DevOps. Наши задачи намного амбициознее, чем просто поделиться своей проблемой и, возможно, получить совсет. Мы обсуждаем все тренды отрасли, чтобы на конференции и секции по DevOps самим было бы приятно прийти.
С июля мы работаем над DevOpsConf Russia, профессиональной конференцией по интеграции процессов разработки, тестирования и эксплуатации, которая выросла из RootConf и пройдет 1 и 2 октября в Москве, в Инфопространстве.
Сегодня я расскажу вам, как мы это делаем, какие доклады стараемся отбирать, о чем просим докладчиков.

С июля мы работаем над DevOpsConf Russia, профессиональной конференцией по интеграции процессов разработки, тестирования и эксплуатации, которая выросла из RootConf и пройдет 1 и 2 октября в Москве, в Инфопространстве.
Сегодня я расскажу вам, как мы это делаем, какие доклады стараемся отбирать, о чем просим докладчиков.
Понимаем RBAC в Kubernetes
7 мин
Перевод
Прим. перев.: Статья написана Javier Salmeron — инженером из хорошо известной в Kubernetes-сообществе компании Bitnami — и была опубликована в блоге CNCF в начале августа. Автор рассказывает о самых основах механизма RBAC (управление доступом на основе ролей), появившегося в Kubernetes полтора года назад. Материал будет особенно полезным для тех, кто знакомится с устройством ключевых компонентов K8s (ссылки на другие подобные статьи см. в конце).
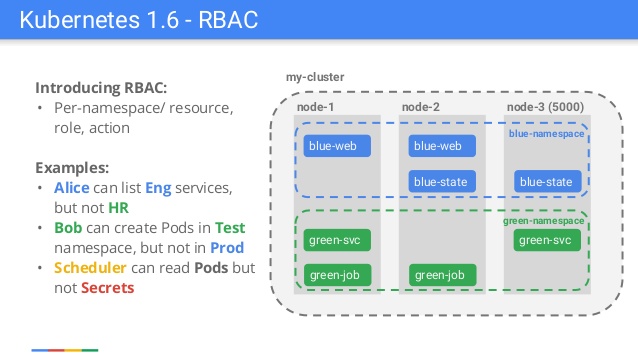
Слайд из презентации, сделанной сотрудником Google по случаю релиза Kubernetes 1.6
Многие опытные пользователи Kubernetes могут вспомнить релиз Kubernetes 1.6, когда авторизация на основе Role-Based Access Control (RBAC) получила статус бета-версии. Так появился альтернативный механизм аутентификации, который дополнил уже существующий, но трудный в управлении и понимании, — Attribute-Based Access Control (ABAC). Все с восторгом приветствовали новую фичу, однако в то же время бесчисленное число пользователей были разочарованы. StackOverflow и GitHub изобиловали сообщениями об ограничениях RBAC, потому что большая часть документации и примеров не учитывали RBAC (но сейчас уже всё в порядке). Эталонным примером стал Helm: простой запуск
Слайд из презентации, сделанной сотрудником Google по случаю релиза Kubernetes 1.6
Многие опытные пользователи Kubernetes могут вспомнить релиз Kubernetes 1.6, когда авторизация на основе Role-Based Access Control (RBAC) получила статус бета-версии. Так появился альтернативный механизм аутентификации, который дополнил уже существующий, но трудный в управлении и понимании, — Attribute-Based Access Control (ABAC). Все с восторгом приветствовали новую фичу, однако в то же время бесчисленное число пользователей были разочарованы. StackOverflow и GitHub изобиловали сообщениями об ограничениях RBAC, потому что большая часть документации и примеров не учитывали RBAC (но сейчас уже всё в порядке). Эталонным примером стал Helm: простой запуск
helm init + helm install больше не работал. Внезапно нам потребовалось добавлять «странные» элементы вроде ServiceAccounts или RoleBindings ещё до того, как разворачивать чарт с WordPress или Redis (подробнее об этом см. в инструкции).Kubernetes (k8s) + Helm + GitLab CI/CD. Деплоим правильно
2 мин
Туториал
В данной статье я хочу рассказать как деплоить приложения в разные среды. В этом примере, мы будем деплоить в: «Test» и «Production». Разумеется, вы можете добавить любые среды.
Для деплоя приложений я использую HELM. Он позволяет гибко управлять конфигурациями. В чем вы сможете убедится ниже. Предполагается, что у вас уже есть настроенный runner с helm-ом и вы знаете и умеете работать с HELM-ом.
Пример файла: .gitlab-ci.yml
Здесь стоит обратить внимание на то, что в зависимости от среды мы передаем переменную: «test» или «production».
Имя проекта мы тоже формируем с учетом имени переменной, для того, чтобы helm понимал, что это разные проекты (helm ls).
Далее, мы передаем эту переменную (среду) в HELM как: «global.env».
Для выше указанного примера helm должен находиться в одноименной папке в вашем репозиторие.
Для деплоя приложений я использую HELM. Он позволяет гибко управлять конфигурациями. В чем вы сможете убедится ниже. Предполагается, что у вас уже есть настроенный runner с helm-ом и вы знаете и умеете работать с HELM-ом.
Пример файла: .gitlab-ci.yml
.base_deploy: &base_deploy
stage: deploy
script:
- PROJECT_NAME="${CI_PROJECT_NAME}-${CI_ENVIRONMENT_SLUG}"
- helm --namespace ${CI_ENVIRONMENT_SLUG} upgrade -i ${PROJECT_NAME} helm --set "global.env=${CI_ENVIRONMENT_SLUG}";
stages:
- deploy
Deploy to Test:
<<: *base_deploy
environment:
name: test
Deploy to Production:
<<: *base_deploy
environment:
name: production
when: manual
Здесь стоит обратить внимание на то, что в зависимости от среды мы передаем переменную: «test» или «production».
Имя проекта мы тоже формируем с учетом имени переменной, для того, чтобы helm понимал, что это разные проекты (helm ls).
Далее, мы передаем эту переменную (среду) в HELM как: «global.env».
Для выше указанного примера helm должен находиться в одноименной папке в вашем репозиторие.
TiKV — распределённая база данных key-value для cloud native
5 мин

28 августа организация CNCF (Cloud Native Computing Foundation), стоящая за Kubernetes, Prometheus и другими Open Source-проектами для современных облачных приложений, объявила о принятии нового продукта в свою «песочницу» — TiKV.
Эта распределённая, транзакционная база данных типа ключ-значение зародилась как дополнение к TiDB — распределённой СУБД, которая предлагает возможности OLTP и OLAP и обеспечивает совместимость с протоколом MySQL… Но давайте обо всём по порядку.