Предисловие переводчика: Когда мы собрались наконец-то подготовить свой материал по разворачиванию Ceph в Kubernetes, нашли уже готовую и, что немаловажно, свежую (от апреля 2017 года) инструкцию от компании Cron (из Боснии и Герцеговины) на английском языке. Убедившись в её простоте и практичности, решили поделиться с другими системными администраторами и DevOps-инженерами в формате «как есть», лишь добавив в листинги один небольшой недостающий фрагмент.
Программно-определяемые хранилища данных набирают популярность последние несколько лет, особенно с масштабным распространением частных облачных инфраструктур. Такие хранилища являются критической частью Docker-контейнеров, а самое популярное из них — Ceph. Если хранилище Ceph уже используется у вас, то благодаря его полной поддержке в Kubernetes легко настроить динамическое создание томов для хранения (volume provisioning) по запросу пользователей. Автоматизация их создания реализуется использованием Kubernetes StorageClasses. В этой инструкции показано, как в кластере Kubernetes реализуется хранилище Ceph.
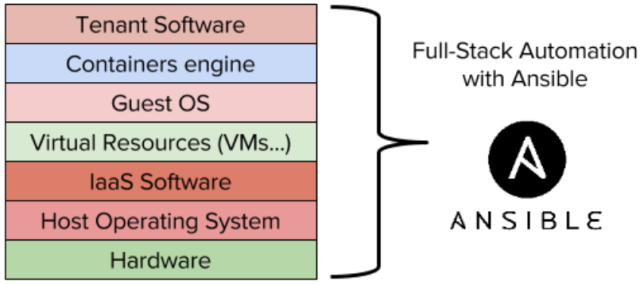
 Перевод статьи директора по инфраструктуре @Synthesio — крик души про усталось от алертов и боль от не cloud-ready мониторинга.
Перевод статьи директора по инфраструктуре @Synthesio — крик души про усталось от алертов и боль от не cloud-ready мониторинга.

 Привет, Хаброжители! Наконец-то у нас вышла книга Дженнифер Дэвис и Кэтрин Дэниелс — Философия DevOps.
Привет, Хаброжители! Наконец-то у нас вышла книга Дженнифер Дэвис и Кэтрин Дэниелс — Философия DevOps.