LogDoc: логи здорового человека
Средний
6 мин
Привет, Хабр
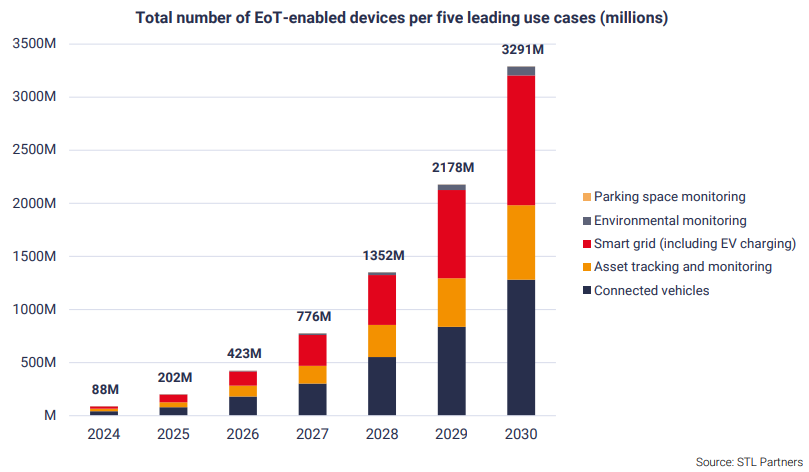
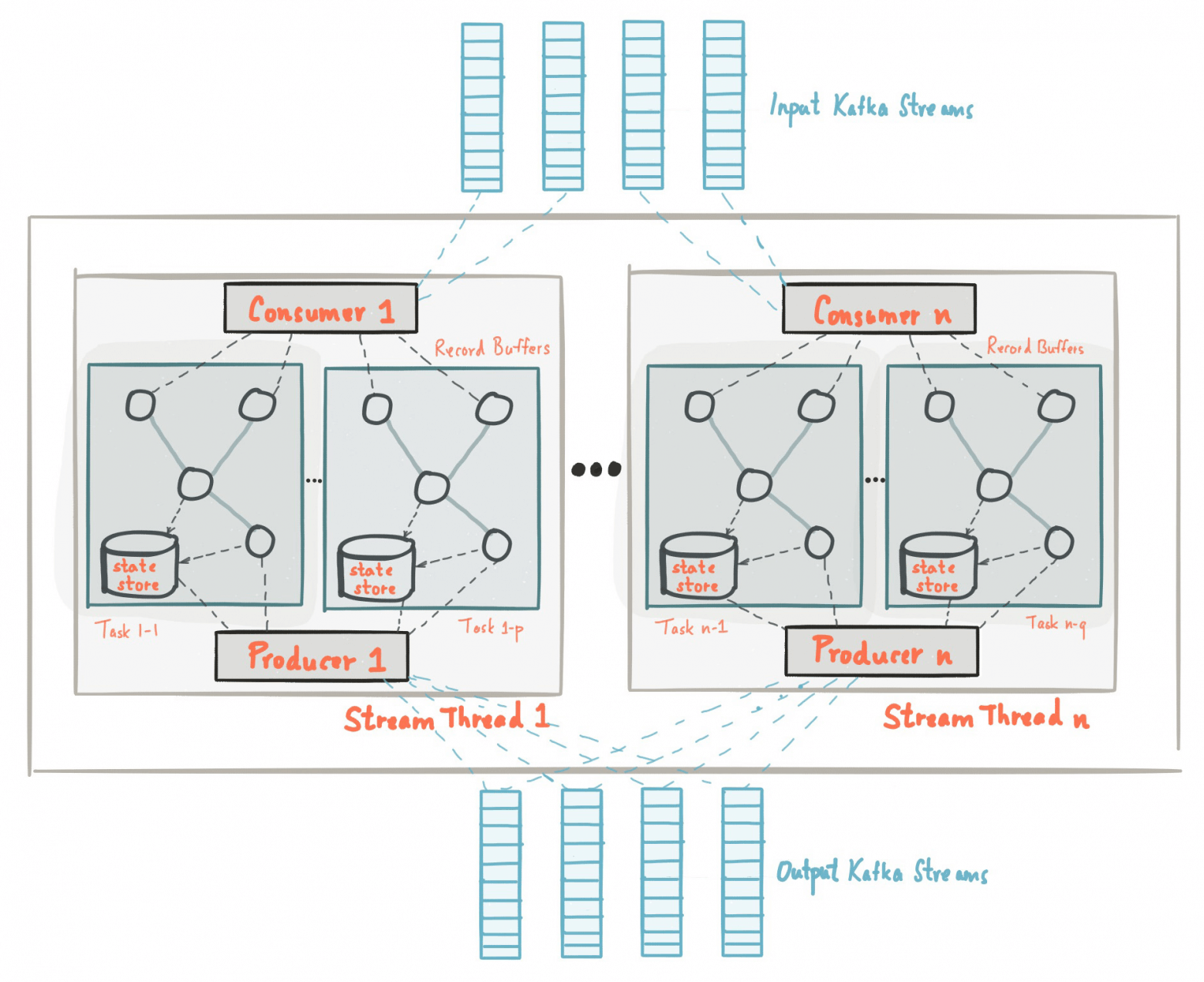
Однажды команда LogDoc, которая тогда ещё была просто дружеской компанией суровых разработчиков, после бурного обсуждения очередного напряжённого рабочего дня вынесла однозначный вердикт — в мире нет и не предвидится нормального, человеческого продукта для работы в распределённой среде с логами, трейсами, сигналами и прочим подобным. Нас это опечалило (по очевидным причинам) и воодушевило — мы увидели возможность создать полезный продукт. Подумали, собрались с духом и выложились полностью в попытке реализовать задуманное. Именно результат наших усилий мы представляем вам в этой вводной статье.