Привет всем. Я хотел бы рассказать о принципах, лежащих в основе распознавания объектов с использованием OpenCV. Благо какое-то время мне довелось поработать в лаборатории компьютерного зрения ВМК МГУ, и я немного вник в премудрости этой ветви computer science. Задача, которую я буду рассматривать здесь, предлагалась на Microsoft Computer Vision School Moscow 2011 на семинарах Виктора Ерухимова, одного из разработчиков программного комплекса OpenCV. Почти в таком же виде рассматриваемый код можно найти в демках OpenCV 2.4.
На картинке изображенна турецкая снайперская винтовка с очень подходящим названием — JNG. В статье, как вы уже догадались — речь пойдёт о графическом формате JNG, а отнюдь не об оружии. На хабре уже мелькали темы, касающиеся этого формата, однако их было не много, а некоторые, к сожалению, впоследствии были удалены авторами. Не смотря на то, что JNG не особо популярный формат и базируется на формате MNG, который, судя по всему, можно считать мёртворождённым, у JNG есть одно очень хорошее свойство – это высокая степень сжатия графики с потерями плюс начиие альфа канала.
По сути JNG представляет из себя подвид формата MNG (однако со своим маркером в заголовке, позволяющим отличать оба этих формата). Цветовые данные сохраняются в JPEG формате, а вот альфа может хранится в одном из двух вариантов – либо тоже сжатая при помощи JPEG, как картинка в оттенках серого, либо используя такое же как в PNG — сжатие без потерь.
Где может пригодится JNG? Для меня он больше всего подошёл для хранения текстурных атласов в мобильных играх. Небольшой пример – исходный набор графики от игры весил 57 мегабайт, после замены всех png на jng – набор графики стал весить 15 мегабайт. Неплохой выигрыш для мобильной игры. Поиск других областей, где можно применить jng оставлю на усмотрение читателя, я же опишу чем смотреть, чем создавать а также как грузить (с примерами кода на C/C++) картинки в формате JNG, а также немного теории об его устройстве.
В Fujitsu предлагают простой способ добавить интерактивности в обычную телевизионную трансляцию с тем, чтобы пользователи смартфонов без каких-либо дополнительных технических устройств (вроде всевозможных приставок) могли легко получить дополнительную информацию на экране своего гаджета.
Идея передачи информации является довольно простой и в некоторой степени подобна известному QR-сканированию — то есть, на смартфоне требуется запустить специальное приложение и направить устройство на телевизор. Специальным образом подготовленная передача будет содержать видеокадры, в которые экран телевизора становится чуть более ярким (или чуть более тёмным): другими словами, последовательность сменяющих друг друга видеокадров с разной степенью яркости и будет кодировать двоичную информацию в видеосигнале — каждая секунда будет содержать 16 бит.
Многие современные алгоритмы компьютерного зрения строятся на основе детектирования и сопоставления особых точек визуальных образов. По этой теме было написано немало статей на хабре(например SURF, SIFT). Но в большинстве работ не уделяется должного вниманию такому важному этапу, как фильтрация ложных соответствий между изображениями. Чаще всего для этих целей применяют RANSAC-метод и на этом останавливаются. Но это не единственный подход для решения данной задачи.
Данная статья посвящена одному из альтернативных способов фильтрации ложных соответствий.
Перед вами оригинальный снимок, без обработки в фоторедакторе или применения каких-то художественных эффектов. Исключительно точное документальное фото. Только это не картина одного момента, как в обычной фотографии. В кадре вместились события, которые происходили в течение около 30 секунд на промежутке пространства шириной 1 пиксел. Снимок сделан методом щелевой фотографии.
В нью-йоркском Метрополитен-музее 11 октября открылась выставка “Faking It: Manipulated Photography Before Photoshop”, посвящённая историческому искусству подделки фотографий, ретуширования и фотомонтажа. Некоторые работы можно посмотреть на сайте музея.
Крупнейшая в мире коллекция «отфотошопленных фотографий» доказывает, что люди начали активно заниматься такими манипуляциями задолго до изобретения компьютеров и цифровой фотографии. Более того, многие методы 150-летней давности используются сейчас практически в неизменном виде.
В июне 2012 года группа исследователей из Google запустила нейросеть на кластере 1000 компьютеров (16 тыс. процессорных ядер; 1 млрд связей между нейронами). Эксперимент стал одним из самых масштабных в области искусственного интеллекта, причём систему изначально создавали для решения практических задач.
Самообучаемая нейросеть — достаточно универсальный инструмент, который можно использовать на разных массивах данных. В компании Google её применили для улучшения точности распознавания речи: «Мы получили уменьшение на 20-25% количества ошибок при распознавании, — говорит Винсент Ванхоук (Vincent Vanhoucke), руководитель отдела распознавания речи в Google. — Это значит, что многие люди получат безошибочный результат». Нейросеть оптимизировала алгоритмы для английского языка, но Ванхоук говорит, что аналогичные улучшения могут быть достигнуты и для других языков и диалектов.
Это не просто обзор существующих OCR (мы будем говорить всего о трёх) и не руководство по установке (хотя установка будет описана). Эта статья была создана с целью разобраться, что и как реально может распознать русский и английский языки в Linux.
Пока Curiosity весь в делах и NASA не до того, чтобы оповещать нас о результатах исследований, а вопрос о цвете Марса в ходе нашего текущего проекта как нельзя актуален, мы с коллегами вернулись к старой избитой теме: какого цвета Марс.
В NASA ранее тоже задавались таким вопросом. Красивый пейзаж с залитыми Солнцем склонами марсианских стволовых гор, причудливыми базальтовыми дюнами, с экзотическими для Земли, но обычными для Марса фигурами выветривания, сделан в 2003 году членами команды разработчиков камеры THEMIS из Корнельского университета вместе с художником Доном Дэвисом, экспертом в области полноцветных визуализаций планетарных и космических объектов.
Дэвис начал с калибровки и сопоставления файлов многоспектральных снимков, сделанных THEMIS VIS в разных диапазонах. Используя в качестве ориентира полноцветные изображения с космического телескопа Хаббл и свой личный опыт в обсерватории Mt. Wilson и других, он вручную отрегулировал баланс цвета, чтобы он наиболее точно соответствовал такому Марсу, который бы мы увидели «своими глазами». Он также вручную немного сгладил и обработал изображение, чтобы минимизировать эффекты остаточного рассеянного света при фотографировании. (оригинал источника информации).
Но у нас же нет такой сложной системы для коррекции приходящих с Марса фото. А многочисленные попытки скорректировать фото с Марса автоматом через «автоматическую цветовую коррекцию» фотошопом нам кажется немного наивными. Очень сомнительно, что фотошоп настроен на приведение марсианских фотографий в земной вид.
В 2011 году 75-летний юбилей термина «спам» знаменовался вводом капчи 200 миллионов раз ЕЖЕДНЕВНО!
Все эти вводы — следствие борьбы администраторов сайтов со спам-ботами.
Автоматизация процесса распознавания капчи для множества людей, активно ведущих бизнес в Интернете, является насущной проблемой. Можно относиться к таким бизнесменам и специалистам как к «нехорошим и надоедливым спамерам». Однако остановить процесс спам-постинга, по крайней мере, в обозримом будущем возможным не представляется.
Ссылочный маркетинг здесь полноценно и уникально сочетает в себе решение задач продвижения, повышения репутации продвигаемого сайта в глазах поисковых систем. Происходит это по той простой причине, что каждая ссылка на сайт (в т.ч. и из спам-поста) повышает его позиции в выдачах Google, Яндекса и т.д. Следовательно, такой способ «убийства двух зайцев одним выстрелом» выгоден изначально. И значительная часть Интернет-бизнесменов должны не бороться со спам-постингом, а пытаться использовать его в своих целях.
Итак, актуальность решения задачи «обход капчи» сомнений не вызывает.
Один из читателей техноблога Gizmodo Метт Ван Гастел (Matt Van Gastel) прислал в редакцию сайта ответ на своё письмо, которое он отправлял в Apple по поводу характерных фиолетовых артефактов, появляющихся на фотографиях, полученных камерой его iPhone 5. Речь идёт о многочисленных жалобах пользователей, которые иллюстрируются следующим:
В данной статье хотелось бы рассказать о сравнительно новом операторе, применяемом в задаче классификации текстур. Данная задача очень близка к задаче поиска, распознавания и классификации образов.
Оператор LBP может быть использован для поиска объекта на изображении (например лица), а также проверки этого объекта на принадлежность некоторому классу (верификация, распознавание эмоций, пола по лицу). Заинтересовавшихся милости прошу под кат.
Представляю вашему вниманию заключительную статью из трилогии «Восстановление расфокусированных и смазанных изображений». Первые две вызвали заметный интерес — область, действительно, интересная. В этой части я рассмотрю семейство методов, которые дают лучшее качество, по сравнении со стандартным Винеровским фильтром — это методы, основанные на Total Variaton prior.
Также по традиции я выложил новую версию SmartDeblur (вместе с исходниками в open-source) в которой реализовал этот метод. Итоговое качество получилось на уровне коммерческих аналогов типа Topaz InFocus. Вот пример обработки реального изображения с очень большим размытием:
Алгоритм Particle Filter замечателен своей простотой и интуитивной понятностью. Предлагаю собственный вариант его использования в задаче стереоскопического зрения для сопоставления «одной и той же точки» на двух изображениях — с левой и правой камеры. Для реализации (исключительно в целях развлечения) использован Python с библиотеками numpy (матричные вычисления) и pygame (графика и обработка событий мышки). Сам алгоритм Particle Filter без изменений взят из курса Programming a Robotic Car на Udacity. Меня извиняет лишь то, что я честно прослушал весь курс и сделал все домашние работы, включая и реализацию этого алгоритма.
В задаче стереоскопического зрения нужно сопоставлять малые области (например, 8х8 пикселей) на левом и правом кадре. При идеальном расположении камер строго горизонтально, зная разность координаты по оси Х одинаковой области между левым и правым кадром, можно вычислить расстояние до объекта, который изображен в этой области. Понимаю, что звучит запутанно, но на самом деле это легко выводится простейшими геометрическими построениями по правилу подобных треугольников. Например, на видео с недостроенной колокольней, мы видим уходящий вдаль забор с одинаковыми ромбами. Ближний к нам ромб наиболее сильно смещен на правом кадре относительно левого, следующий — чуть меньше и т.д.
Стандартная схема решения такой задачи довольно тяжелая в вычислительном плане. Нужно откалибровать погрешности взаимного расположения камер так, чтобы гарантировать, что горизонтальная линия с координатой Y на левом кадре точно соответствует горизонтали с той же координатой на правом кадре. Затем сопоставить каждой точке (или области ) вдоль горизонтальной линии на левом кадре наилучшую точку на правом кадре (это решается, например, методом динамического программирования, имеющем квадратическую сложность). Тогда у нас будут вычислены смещения по Ох для каждой точки вдоль рассматриваемой горизонтали. И повторить процедуру для каждой горизонтальной линии. Немного сложновато, и уж совсем не похоже на то, как это работает в мозге (мы ведь знаем это, правда?)
Посмотрите, как алгорим Particle Filter решает эту же задачу. На мой взгляд, это очень похоже на биологическую модель, по крайней мере имитируются микро-движения глаза для фокусировки внимания на отдельных фрагментах изображения, и учитывается «предыстория» таких микро-движений.
Добрый вечер, дорогие хабровчане, добрый вечер, славный город Белгород.
Расскажу я вам сегодня сказку об одном дураке. А дурак он (я, то беж) потому, что не следовал одной простой истине:
Знаменитая программистская лень заключается в том, что вместо лишних телодвижений (своих ли, машинных ли) лучше подумать и найти решение поизящнее и попроще.
А речь в ней пойдет о том, как дурак пытался научить находить положение камеры в пространстве.
Во время спасательных и поисковых операций спастелям жизненно важно всегда чётко представлять, в какой части здания они находятся, каковы кратчайшие пути эвакуации, какие помещения уже обследованы и где в эту секунду работают их коллеги. Особенно остро эта задача стоит при пожаре и задымлении. В MIT создали индивидуальную систему автоматического построения карты помещения, которая позволяет спасателю всегда знать, где он находится.
Конечно же, формат JPEG не поддерживает прозрачность, но сама идея использовать JPEG вместо PNG для прозрачных текстур будоражит умы довольно давно. Камрад PaulZi не так давно предложил использовать для HTML формат SVG, в котором хранится само изображение и маска. Jim Studt предлагает использовать EXIF поля в JPEG и хранить там маски, а отображать на веб-странице с помощью Canvas.
Оба метода относительно сложны для использования, да и рассчитаны на веб, потому я остановился на самом простом варианте: хранить отдельно lossy JPEG для RGB и lossless маску в PNG, а совмещать их на этапе получения UIImage в программе. Сразу хочу сказать, что пишу на MonoTouch, потому код привожу на C#, хотя в ObjC это делается почти точно так же, с учетом синтаксиса.
После более четырёх лет разработки Агентство по перспективным оборонным научно-исследовательским разработкам США (DARPA) представило уникальную систему компьютерного зрения. Уникальность её в том, что для уточнения распознавания компьютерная система использует ЭЭГ-сигнал с человеческого мозга.
Вчерашний комикс Xkcd Click and Drag — это настоящий квест, на прохождение которого может уйти целый день. Комикс целиком занимает 165.888 x 79.872 px, то есть 13 гигапикселов. Если распечатать его с разрешением 300 dpi, то получится плакат 14 х 6,75 метра.
Турникеты, запоминающие лица, уже испытаны в ФСО, аэропорту Норильска и в нашем офисе. Они узнают вас в солнцезащитных очках, шапке-ушанке и отличат вас от вашего брата-близнеца. Но начнём с самого начала.
В каждой системе есть промежуточный агент, с которым идёт сверка: это может быть карта с ключом, радиобрелок и так далее. Эта штука создаёт массу проблем, потому что может потеряться, по ней может пройти другой и так далее. Плюс, когда в бизнес-центре много арендаторов — это вообще настоящий ад с форматами карт-ключей.
Логично, что сверять надо без промежуточного агента, если есть такая техническая возможность. К сожалению, сверка по отпечаткам (они-то всегда с собой) не даёт нужной точности: тут или ложные срабатывания, или банальный порез, грязь и всё такое.

 На картинке изображенна турецкая снайперская винтовка с очень подходящим названием — JNG. В статье, как вы уже догадались — речь пойдёт о графическом формате JNG, а отнюдь не об оружии. На хабре уже мелькали темы, касающиеся этого формата, однако их было не много, а некоторые, к сожалению, впоследствии были удалены авторами. Не смотря на то, что JNG не особо популярный формат и базируется на формате MNG, который, судя по всему, можно считать мёртворождённым, у JNG есть одно очень хорошее свойство – это высокая степень сжатия графики с потерями плюс начиие альфа канала.
На картинке изображенна турецкая снайперская винтовка с очень подходящим названием — JNG. В статье, как вы уже догадались — речь пойдёт о графическом формате JNG, а отнюдь не об оружии. На хабре уже мелькали темы, касающиеся этого формата, однако их было не много, а некоторые, к сожалению, впоследствии были удалены авторами. Не смотря на то, что JNG не особо популярный формат и базируется на формате MNG, который, судя по всему, можно считать мёртворождённым, у JNG есть одно очень хорошее свойство – это высокая степень сжатия графики с потерями плюс начиие альфа канала.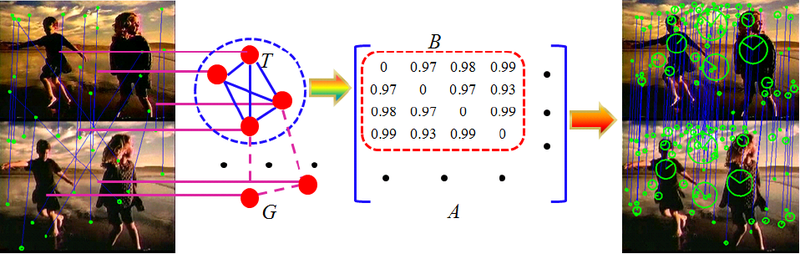






 Конечно же, формат JPEG не поддерживает прозрачность, но сама идея использовать JPEG вместо PNG для прозрачных текстур будоражит умы довольно давно. Камрад
Конечно же, формат JPEG не поддерживает прозрачность, но сама идея использовать JPEG вместо PNG для прозрачных текстур будоражит умы довольно давно. Камрад 

