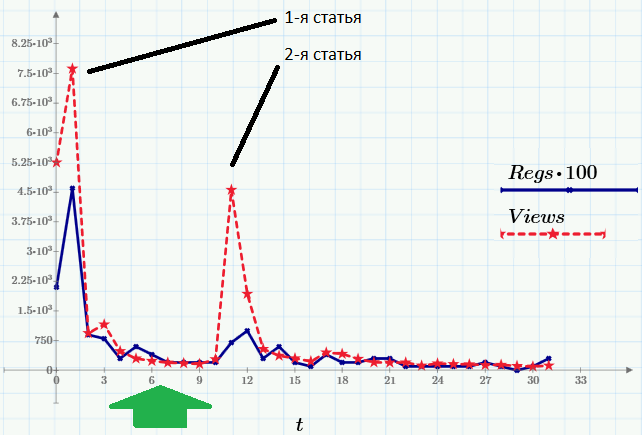
Как мы придумывали систему анализа текстов
5 мин
Доброго времени суток всем. Это наш первый пост в блог стартапа «Meanotek», и наверное он будет больше ознакомительного характера. Чтобы не было совсем скучно читать, мы попробуем рассказать историю, о том как одна практическая задача привела нас к созданию полноценной системы «понимания» текста компьютером, и что из этого получилось.
Мысль научить компьютер общаться на человеческом языке у меня появилась еще в школе, когда у меня дома был один из первых советских аналогов IBM PC, с языком программирования GW BASIC. Понятно, что далеко эта задумка в то время не ушла, потом ее заслонили другие более важные дела, но совершенно неожиданно она всплыла вновь спустя много лет, уже в связи с конкретной потребностью.
Собственно идея пришла в голову во время работы над другим проектом — сайтом поиска отзывов reviewdot.ru. Идея reviewdot.ru была в следующем — пользователь вводит запрос, например «зеркальный фотоаппарат для начинающих» — и получает список ссылок на отзывы в интернете, которые касаются именно этого вопроса. Или к примеру, чтобы по запросу «что ломается в стиральной машине Indesit?” появлялись ссылки на отзыв пользователей марки Indesit, у которых что-то сломалось. Вопрос ценности данного ресурса для людей пока оставим за скобками, и поговорим немного о технической стороне реализации.
Мысль научить компьютер общаться на человеческом языке у меня появилась еще в школе, когда у меня дома был один из первых советских аналогов IBM PC, с языком программирования GW BASIC. Понятно, что далеко эта задумка в то время не ушла, потом ее заслонили другие более важные дела, но совершенно неожиданно она всплыла вновь спустя много лет, уже в связи с конкретной потребностью.
Собственно идея пришла в голову во время работы над другим проектом — сайтом поиска отзывов reviewdot.ru. Идея reviewdot.ru была в следующем — пользователь вводит запрос, например «зеркальный фотоаппарат для начинающих» — и получает список ссылок на отзывы в интернете, которые касаются именно этого вопроса. Или к примеру, чтобы по запросу «что ломается в стиральной машине Indesit?” появлялись ссылки на отзыв пользователей марки Indesit, у которых что-то сломалось. Вопрос ценности данного ресурса для людей пока оставим за скобками, и поговорим немного о технической стороне реализации.





 Привет, Хабр, давно не виделись. В этом посте мне хотелось бы рассказать о таком относительно новом понятии в машинном обучении, как
Привет, Хабр, давно не виделись. В этом посте мне хотелось бы рассказать о таком относительно новом понятии в машинном обучении, как