
Обзор наиболее интересных материалов по анализу данных и машинному обучению №36 (16 — 22 февраля 2015)
3 мин

Представляю вашему вниманию очередной выпуск обзора наиболее интересных материалов, посвященных теме анализа данных и машинного обучения.
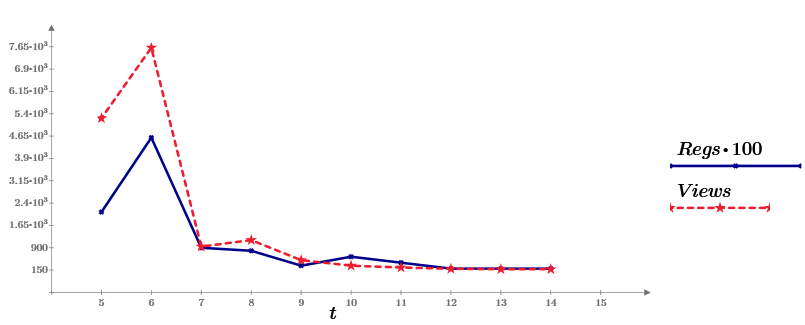






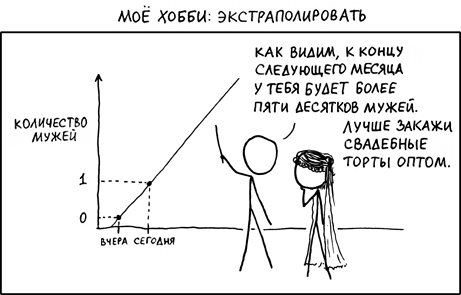
 Иногда так бывает: задачу можно решить чуть ли не арифметически, а на ум прежде всего приходят всякие интегралы Лебега и функции Бесселя. Вот начинаешь обучать нейронную сеть, потом добавляешь еще парочку скрытых слоев, экспериментируешь с количеством нейронов, функциями активации, потом вспоминаешь о SVM и Random Forest и начинаешь все сначала. И все же, несмотря на прямо таки изобилие занимательных статистических методов обучения, линейная регрессия остается одним из популярных инструментов. И для этого есть свои предпосылки, не последнее месте среди которых занимает интуитивность в интерпретации модели.
Иногда так бывает: задачу можно решить чуть ли не арифметически, а на ум прежде всего приходят всякие интегралы Лебега и функции Бесселя. Вот начинаешь обучать нейронную сеть, потом добавляешь еще парочку скрытых слоев, экспериментируешь с количеством нейронов, функциями активации, потом вспоминаешь о SVM и Random Forest и начинаешь все сначала. И все же, несмотря на прямо таки изобилие занимательных статистических методов обучения, линейная регрессия остается одним из популярных инструментов. И для этого есть свои предпосылки, не последнее месте среди которых занимает интуитивность в интерпретации модели. Два года назад на меня сильное впечатление произвела хабрастатья «Стивен Вольфрам проанализировал свою жизнь». К тому времени я уже года два записывал в Google-календаре, что и когда я делал, но к тому моменту я не задумывался, о том, что можно сделать с этой информацией. После прочтения той статьи, я понял: эту информацию можно анализировать! Сейчас я могу посчитать сколько раз мы с друзьями собирались играть в баскетбол за эти годы, сколько часов я провёл в больнице и т. п.
Два года назад на меня сильное впечатление произвела хабрастатья «Стивен Вольфрам проанализировал свою жизнь». К тому времени я уже года два записывал в Google-календаре, что и когда я делал, но к тому моменту я не задумывался, о том, что можно сделать с этой информацией. После прочтения той статьи, я понял: эту информацию можно анализировать! Сейчас я могу посчитать сколько раз мы с друзьями собирались играть в баскетбол за эти годы, сколько часов я провёл в больнице и т. п. Довольно часто встречаются неполные наборы данных, в которых некоторые переменные не определены. В языке R содержимое таких переменных задается как «Not Available» — или сокращенно NA. Соответственно, возникает вопрос, как поступать с неопределенными значениям: стоит ли их игнорировать или откорректировать каким-либо образом?
Довольно часто встречаются неполные наборы данных, в которых некоторые переменные не определены. В языке R содержимое таких переменных задается как «Not Available» — или сокращенно NA. Соответственно, возникает вопрос, как поступать с неопределенными значениям: стоит ли их игнорировать или откорректировать каким-либо образом? 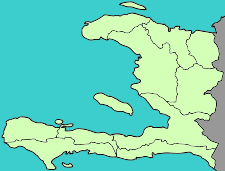 Уважаемое Хабрасообщество, сегодня через как всегда молниеносную Википедию (спасибо анониму!) я обнаружил, что Google Translate и Bing Translator начали осуществлять статистический машинный перевод с (и «на» тоже) гаитянского креольского языка (что такое креольский язык?). Гаитянский — один из официальных языков Республики Гаити, на котором говорят 14 миллионов человек; образовался на основе французского образца 18 века, упростился и понабрал в себя всё что только можно.
Уважаемое Хабрасообщество, сегодня через как всегда молниеносную Википедию (спасибо анониму!) я обнаружил, что Google Translate и Bing Translator начали осуществлять статистический машинный перевод с (и «на» тоже) гаитянского креольского языка (что такое креольский язык?). Гаитянский — один из официальных языков Республики Гаити, на котором говорят 14 миллионов человек; образовался на основе французского образца 18 века, упростился и понабрал в себя всё что только можно.