Машинное обучение — 1. Корреляция и регрессия. Пример: конверсия посетителей сайта
3 мин
Туториал
Как и обещал, начинаю цикл статей по «машинному обучению». Эта будет посвящена таким понятиям из статистики, как корреляция случайных величин и линейная регрессия. Рассмотрим, как реальные данные, так и модельные (симуляцию Монте-Карло).
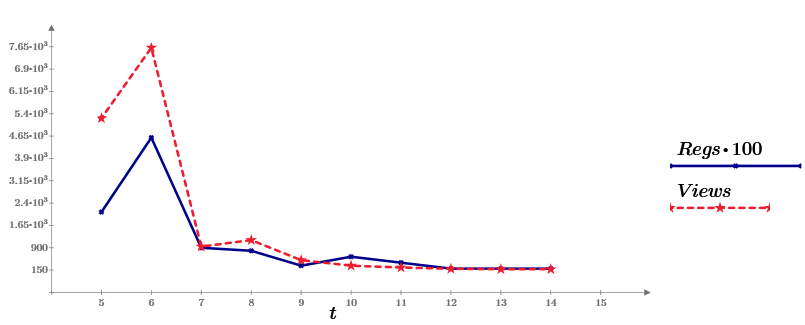
Чтобы было интереснее, рассказ построен на примерах, причем в качестве данных (и в этой, и в следующих, статьях) я буду стараться брать статистику прямо отсюда, с Хабра. А именно, неделю назад я написал свою первую статью на Хабре (про Mathcad Express, в котором и будем все считать). И вот теперь статистику по ее просмотрам за 10 дней и предлагаю в качестве исходных данных. На графике это ряд Views, синяя линия. Второй ряд данных (Regs, с коэффициентом 100) показывает число читателей, выполнивших после прочтения определенное действие (регистрацию и скачивание дистрибутива Mathcad Prime).
Часть 1. Реальные данные
Чтобы было интереснее, рассказ построен на примерах, причем в качестве данных (и в этой, и в следующих, статьях) я буду стараться брать статистику прямо отсюда, с Хабра. А именно, неделю назад я написал свою первую статью на Хабре (про Mathcad Express, в котором и будем все считать). И вот теперь статистику по ее просмотрам за 10 дней и предлагаю в качестве исходных данных. На графике это ряд Views, синяя линия. Второй ряд данных (Regs, с коэффициентом 100) показывает число читателей, выполнивших после прочтения определенное действие (регистрацию и скачивание дистрибутива Mathcad Prime).






 Иногда так бывает: задачу можно решить чуть ли не арифметически, а на ум прежде всего приходят всякие интегралы Лебега и функции Бесселя. Вот начинаешь обучать нейронную сеть, потом добавляешь еще парочку скрытых слоев, экспериментируешь с количеством нейронов, функциями активации, потом вспоминаешь о SVM и Random Forest и начинаешь все сначала. И все же, несмотря на прямо таки изобилие занимательных статистических методов обучения,
Иногда так бывает: задачу можно решить чуть ли не арифметически, а на ум прежде всего приходят всякие интегралы Лебега и функции Бесселя. Вот начинаешь обучать нейронную сеть, потом добавляешь еще парочку скрытых слоев, экспериментируешь с количеством нейронов, функциями активации, потом вспоминаешь о SVM и Random Forest и начинаешь все сначала. И все же, несмотря на прямо таки изобилие занимательных статистических методов обучения,  Два года назад на меня сильное впечатление произвела хабрастатья
Два года назад на меня сильное впечатление произвела хабрастатья  Довольно часто встречаются неполные наборы данных, в которых некоторые переменные не определены. В языке R содержимое таких переменных задается как «Not Available» — или сокращенно NA. Соответственно, возникает вопрос, как поступать с неопределенными значениям: стоит ли их игнорировать или откорректировать каким-либо образом?
Довольно часто встречаются неполные наборы данных, в которых некоторые переменные не определены. В языке R содержимое таких переменных задается как «Not Available» — или сокращенно NA. Соответственно, возникает вопрос, как поступать с неопределенными значениям: стоит ли их игнорировать или откорректировать каким-либо образом?