
В предыдущих статьях, посвященных вероятностному описанию конверсии сайта, мы рассматривали число событий (просмотров и кликов), как выборку случайной величины, без зависимости от времени. Теперь пришло время сделать следующий шаг и ввести ее в рассмотрение.
Нейропластичность в искусственных нейронных сетях
17 мин
 Привет, Хабр, давно не виделись. В этом посте мне хотелось бы рассказать о таком относительно новом понятии в машинном обучении, как transfer learning. Так как я не нашел какого-либо устоявшегося перевода этого термина, то и в названии поста фигурирует хоть и другой, но близкий по смыслу термин, который как бы является биологической предпосылкой к формализации теории передачи знаний от одной модели к другой. Итак, план такой: для начала рассмотрим биологические предпосылки; после коснемся отличия transfer learning от очень похожей идеи предобучения глубокой нейронной сети; а в конце обсудим реальную задачу семантического хеширования изображений. Для этого мы не будем скромничать и возьмем глубокую (19 слоев) сверточную нейросеть победителей конкурса imagenet 2014 года в разделе «локализация и классификация» (Visual Geometry Group, University of Oxford), сделаем ей небольшую трепанацию, извлечем часть слоев и используем их в своих целях. Поехали.
Привет, Хабр, давно не виделись. В этом посте мне хотелось бы рассказать о таком относительно новом понятии в машинном обучении, как transfer learning. Так как я не нашел какого-либо устоявшегося перевода этого термина, то и в названии поста фигурирует хоть и другой, но близкий по смыслу термин, который как бы является биологической предпосылкой к формализации теории передачи знаний от одной модели к другой. Итак, план такой: для начала рассмотрим биологические предпосылки; после коснемся отличия transfer learning от очень похожей идеи предобучения глубокой нейронной сети; а в конце обсудим реальную задачу семантического хеширования изображений. Для этого мы не будем скромничать и возьмем глубокую (19 слоев) сверточную нейросеть победителей конкурса imagenet 2014 года в разделе «локализация и классификация» (Visual Geometry Group, University of Oxford), сделаем ей небольшую трепанацию, извлечем часть слоев и используем их в своих целях. Поехали.Deep Learning, NLP, and Representations
13 мин
Предлагаю читателям «Хабрахабра» перевод поста «Deep Learning, NLP, and Representations» крутого Кристофера Олаха. Иллюстрации оттуда же.
В последние годы методы, использующие глубокое обучение нейросетей (deep neural networks), заняли ведущее положение в распознавании образов. Благодаря им планка для качества методов компьютерного зрения значительно поднялась. В ту же сторону движется и распознавание речи.
Результаты результатами, но почему они так круто решают задачи?

В посте освещено несколько впечатляющих результатов применения глубоких нейронных сетей в обработке естественного языка (Natural Language Processing; NLP). Таким образом я надеюсь доходчиво изложить один из ответов на вопрос, почему глубокие нейросети работают.
В последние годы методы, использующие глубокое обучение нейросетей (deep neural networks), заняли ведущее положение в распознавании образов. Благодаря им планка для качества методов компьютерного зрения значительно поднялась. В ту же сторону движется и распознавание речи.
Результаты результатами, но почему они так круто решают задачи?
В посте освещено несколько впечатляющих результатов применения глубоких нейронных сетей в обработке естественного языка (Natural Language Processing; NLP). Таким образом я надеюсь доходчиво изложить один из ответов на вопрос, почему глубокие нейросети работают.
Обзор наиболее интересных материалов по анализу данных и машинному обучению №39 (9 — 15 марта 2015)
3 мин

Представляю вашему вниманию очередной выпуск обзора наиболее интересных материалов, посвященных теме анализа данных и машинного обучения.
Машинное обучение — 2. Нелинейная регрессия и численная оптимизация
4 мин
Туториал
Прошел месяц с появления моей первой статьи на Хабре и 20 дней с момента появления второй статьи про линейную регрессию. Статистика по просмотрам и целевым действиям аудитории копится, и именно она послужила отправной точкой для данной статьи. В ней мы коротко рассмотрим пример нелинейной регрессии (а именно, экспоненциальной) и с ее помощью построим модель конверсии, выделив среди пользователей две группы.
Когда известно, что случайная величина y зависит от чего-то (например, от времени или от другой случайной величины x) линейно, т.е. по закону y(x)= Ax+b, то применяется линейная регрессия (так в прошлой статье мы строили зависимость числа регистраций от числа просмотров). Для линейной регрессии коэффициенты A и b вычисляются по известным формулам. В случае регрессии другого вида, например, экспоненциальной, для того чтобы определить неизвестные параметры, необходимо решить соответствующую оптимизационную задачу: а именно, в рамках метода наименьших квадратов (МНК) задачу нахождения минимума суммы квадратов (y(xi) — yi)2.
Итак, вот данные, которые будем использовать в качестве примера. Пики посещаемости (ряд Views, красный пунктир) приходятся на моменты выхода статей. Второй ряд данных (Regs, с множителем 100) показывает число читателей, выполнивших после прочтения определенное действие (регистрацию и скачивание Mathcad Express – с его помощью, к слову, вы сможете повторить все расчеты этой и предыдущих статей). Все картинки — это скриншоты Mathcad Express, а файл с расчетами вы можете взять здесь.
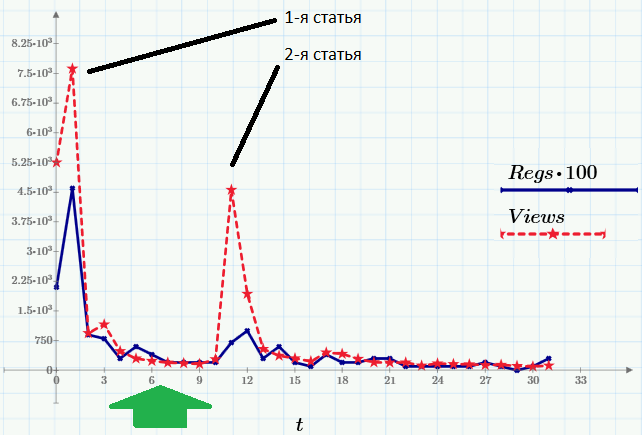
Когда известно, что случайная величина y зависит от чего-то (например, от времени или от другой случайной величины x) линейно, т.е. по закону y(x)= Ax+b, то применяется линейная регрессия (так в прошлой статье мы строили зависимость числа регистраций от числа просмотров). Для линейной регрессии коэффициенты A и b вычисляются по известным формулам. В случае регрессии другого вида, например, экспоненциальной, для того чтобы определить неизвестные параметры, необходимо решить соответствующую оптимизационную задачу: а именно, в рамках метода наименьших квадратов (МНК) задачу нахождения минимума суммы квадратов (y(xi) — yi)2.
Итак, вот данные, которые будем использовать в качестве примера. Пики посещаемости (ряд Views, красный пунктир) приходятся на моменты выхода статей. Второй ряд данных (Regs, с множителем 100) показывает число читателей, выполнивших после прочтения определенное действие (регистрацию и скачивание Mathcad Express – с его помощью, к слову, вы сможете повторить все расчеты этой и предыдущих статей). Все картинки — это скриншоты Mathcad Express, а файл с расчетами вы можете взять здесь.
Обзор наиболее интересных материалов по анализу данных и машинному обучению №38 (2 — 8 марта 2015)
3 мин
Представляю вашему вниманию очередной выпуск обзора наиболее интересных материалов, посвященных теме анализа данных и машинного обучения.
Седьмая ежегодная Летняя школа Microsoft Research по машинному обучению и интеллекту — сотрудничество с ACM Europe
1 мин
Привет!
Как мы писали ранее, 29 июля в Санкт-Петербурге в седьмой раз откроется ежегодная Летняя школа Microsoft Research по машинному обучению.
Обычно следующий за открывающим постом пост пишут, когда известны докладчики, но тут я не смог удержаться.

Школа получила поддержку ACM Europe! На ней выступит докладчик от ACM, и все участники получат статус профессионального члена ассоциации (ACM Professional Membership) и доступ к цифровой библиотеке (ACM Digital Library) на один год. В один из вечеров ассоциация организует вечеринку (beer party) для участников школы. Для нас это большая радость — подобное происходит впервые, и докладчик от АСМ, который знают все как старейшую ИТ-организацию — ценность для слушателей.
Напоминаем, что регистрироваться надо все еще здесь.
Как мы писали ранее, 29 июля в Санкт-Петербурге в седьмой раз откроется ежегодная Летняя школа Microsoft Research по машинному обучению.
Обычно следующий за открывающим постом пост пишут, когда известны докладчики, но тут я не смог удержаться.
Школа получила поддержку ACM Europe! На ней выступит докладчик от ACM, и все участники получат статус профессионального члена ассоциации (ACM Professional Membership) и доступ к цифровой библиотеке (ACM Digital Library) на один год. В один из вечеров ассоциация организует вечеринку (beer party) для участников школы. Для нас это большая радость — подобное происходит впервые, и докладчик от АСМ, который знают все как старейшую ИТ-организацию — ценность для слушателей.
Напоминаем, что регистрироваться надо все еще здесь.
Поиск текстов, не соответствующих тематике и нахождение похожих статей
5 мин
У меня есть сайт со статьями схожей тематики. На сайте было две проблемы: спамерские сообщения и дубликаты статей, причём дубликаты часто являлись не точными копиями.
Данный пост повествует о том, как я решил эти проблемы.
Дано:
Задача: избавиться от спама и дубликатов, а так же не допустить их дальнейшего появления.

Данный пост повествует о том, как я решил эти проблемы.
Дано:
- общее количество статей 140 000;
- количество спама: примерно 16%;
- количество не чётких дубликатов: примерно 63%;
Задача: избавиться от спама и дубликатов, а так же не допустить их дальнейшего появления.
Бонд. Джеймс Бонд. Роботизированная подделка почерка для маркетологов и социальных инженеров
2 мин

Маркетологи быстро выяснили, что в «системе принятия решений о доверии» есть уязвимость — люди охотнее доверяют рукописному тексту, чем печатному. Очень быстро появились рукописные шрифты и подписи в объявлениях/письмах, но они легко распознавались. Теперь же есть возможность автоматизированного написания «от руки» настоящей ручкой (даже перьевой), с учетом всех отступов, расстояний неровностей, несоблюдением пропорций, нажима и углом наклона (осталось следы от шоколадки и кофе автоматически эмулировать).
Там где баги с доверием, там и социальные инженеры тут как тут. Ныряние в мусорные корзины теперь будет приносить больше плодов. Можно будет набрать достаточный объем рукописного текста для подделки.
У сервиса Bond, который предоставляет услуги по отправке реальных писем, есть все шансы пройти «рукописный тест Тьюринга» (т.е. человек не сможет отличить, писал ли этот текст человек или робот).
Я часто говорил, что достаточно знаю ИТ, чтобы не доверять ИТ, теперь же рухнуло и доверие к «реальным документам». Достаточно несколько школьных сочинений скормить нейронным сетям, чтобы они смогли писать за меня (и даже лучше чем я). Кстати, сервис Bond предоставляет услуги по улучшению/тьюнингу вашего почерка.
Итак, что же нам нужно, чтобы на нас оставили завещание?
Шаг первый. Создаем
Шаг второй. Создаем самообучающуюся программу и скармливаем ей несколько листов рукописного текста
Шаг третий. Profit
Под катом краткий обзор оборудования, примеры писем, знакомство с проектами Maillift (письма «от руки»), Bond (письма от руки и распознание и эмуляция почерка), Herald (как студенты свой принтер спаяли)

Обзор наиболее интересных материалов по анализу данных и машинному обучению №37 (23 февраля — 1 марта 2015)
3 мин
Представляю вашему вниманию очередной выпуск обзора наиболее интересных материалов, посвященных теме анализа данных и машинного обучения.
Необычные модели Playboy, или про обнаружение выбросов в данных c помощью Scikit-learn
7 мин
Мотивированный статьей пользователя BubaVV про предсказание веса модели Playboy по ее формам и росту, автор решил углубиться if you know what I mean в эту будоражащую кровь тему исследования и в тех же данных найти выбросы, то есть особо сисястые модели, выделяющиеся на фоне других своими формами, ростом или весом. А на фоне этой разминки чувства юмора заодно немного рассказать начинающим исследователям данных про обнаружение выбросов (outlier detection) и аномалий (anomaly detection) в данных с помощью реализации одноклассовой машины опорных векторов (One-class Support Vector Machine) в библиотеке Scikit-learn, написанной на языке Python.
Обзор наиболее интересных материалов по анализу данных и машинному обучению №36 (16 — 22 февраля 2015)
3 мин
Представляю вашему вниманию очередной выпуск обзора наиболее интересных материалов, посвященных теме анализа данных и машинного обучения.
Машинное обучение — 1. Корреляция и регрессия. Пример: конверсия посетителей сайта
3 мин
Туториал
Как и обещал, начинаю цикл статей по «машинному обучению». Эта будет посвящена таким понятиям из статистики, как корреляция случайных величин и линейная регрессия. Рассмотрим, как реальные данные, так и модельные (симуляцию Монте-Карло).
Чтобы было интереснее, рассказ построен на примерах, причем в качестве данных (и в этой, и в следующих, статьях) я буду стараться брать статистику прямо отсюда, с Хабра. А именно, неделю назад я написал свою первую статью на Хабре (про Mathcad Express, в котором и будем все считать). И вот теперь статистику по ее просмотрам за 10 дней и предлагаю в качестве исходных данных. На графике это ряд Views, синяя линия. Второй ряд данных (Regs, с коэффициентом 100) показывает число читателей, выполнивших после прочтения определенное действие (регистрацию и скачивание дистрибутива Mathcad Prime).
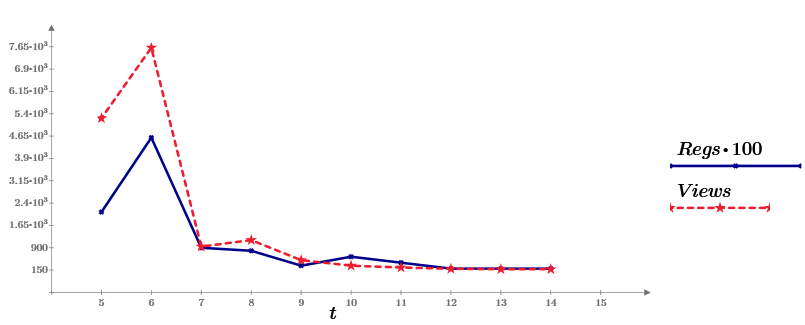
Часть 1. Реальные данные
Чтобы было интереснее, рассказ построен на примерах, причем в качестве данных (и в этой, и в следующих, статьях) я буду стараться брать статистику прямо отсюда, с Хабра. А именно, неделю назад я написал свою первую статью на Хабре (про Mathcad Express, в котором и будем все считать). И вот теперь статистику по ее просмотрам за 10 дней и предлагаю в качестве исходных данных. На графике это ряд Views, синяя линия. Второй ряд данных (Regs, с коэффициентом 100) показывает число читателей, выполнивших после прочтения определенное действие (регистрацию и скачивание дистрибутива Mathcad Prime).
Ближайшие события
Обзор некоторых MOOC Coursera по компьютерным наукам
3 мин
Скорее всего, если вы зашли на Хабр и читаете эту статью, то хоть раз в жизни да слышали про MOOC-курсы.
Но если все же не слышали, то MOOC (по-русски принято произносить «мук») означает «Massive Open Online Course» — массовый открытый онлайн-курс. Это настоящий феномен в образовании XXI века. Газета «New York Times» назвала даже 2012 год «годом MOOC» в связи с появлением на рынке дистанционного образования 3-х «китов» — Coursera, Udacity и EdX. MOOC-ам посвящено множество статей, кто-то видит в них будущее образования, кто-то, наоборот, угрозу. Пытаются также предсказать «традиционную» и «дистанционную» составляющии обучения будущего.






Однако в этой статье я не буду обсуждать перспективы развития дистанционного образования, а расскажу про свой опыт знакомства с курсами на платформе Coursera. Эти курсы будут полезны студентам, изучающим прикладную математику и информатику, в особенности анализ данных. Многое из того, что мне дали эти курсы, как я потом понял — это знания, которыми должен обладать любой уважающий себя исследователь данных (так я предпочитаю переводить профессию Data Scientist).
Но если все же не слышали, то MOOC (по-русски принято произносить «мук») означает «Massive Open Online Course» — массовый открытый онлайн-курс. Это настоящий феномен в образовании XXI века. Газета «New York Times» назвала даже 2012 год «годом MOOC» в связи с появлением на рынке дистанционного образования 3-х «китов» — Coursera, Udacity и EdX. MOOC-ам посвящено множество статей, кто-то видит в них будущее образования, кто-то, наоборот, угрозу. Пытаются также предсказать «традиционную» и «дистанционную» составляющии обучения будущего.
Однако в этой статье я не буду обсуждать перспективы развития дистанционного образования, а расскажу про свой опыт знакомства с курсами на платформе Coursera. Эти курсы будут полезны студентам, изучающим прикладную математику и информатику, в особенности анализ данных. Многое из того, что мне дали эти курсы, как я потом понял — это знания, которыми должен обладать любой уважающий себя исследователь данных (так я предпочитаю переводить профессию Data Scientist).
Нефтяные ряды в R
6 мин
«Графики цен великолепны, чтобы предсказывать прошлое»
Питер Линч
С временными рядами мне как-то не доводилось иметь дело на практике. Я, конечно, читал о них и имел некоторое представление в рамках учебного курса о том, как в общих чертах проводится анализ, но хорошо известно, что то, о чем рассказывают в учебниках по статистике и машинному обучению, не всегда отражает реальное положение дел.
Питер Линч
С временными рядами мне как-то не доводилось иметь дело на практике. Я, конечно, читал о них и имел некоторое представление в рамках учебного курса о том, как в общих чертах проводится анализ, но хорошо известно, что то, о чем рассказывают в учебниках по статистике и машинному обучению, не всегда отражает реальное положение дел.
Марковские случайные поля
4 мин
Туториал
Статья посвящена описанию метода CRF (Conditional Random Fields), являющимся разновидностью метода Марковских случайных полей (Markov random field). Данный метод нашел широкое применение в различных областях ИИ, в частности, его успешно используют в задачах распознавания речи и образов, обработки текстовой информации, а также и в других предметных областях: биоинформатики, компьютерной графики и пр.
Несколько слов о «линейной» регрессии
5 мин
 Иногда так бывает: задачу можно решить чуть ли не арифметически, а на ум прежде всего приходят всякие интегралы Лебега и функции Бесселя. Вот начинаешь обучать нейронную сеть, потом добавляешь еще парочку скрытых слоев, экспериментируешь с количеством нейронов, функциями активации, потом вспоминаешь о SVM и Random Forest и начинаешь все сначала. И все же, несмотря на прямо таки изобилие занимательных статистических методов обучения, линейная регрессия остается одним из популярных инструментов. И для этого есть свои предпосылки, не последнее месте среди которых занимает интуитивность в интерпретации модели.
Иногда так бывает: задачу можно решить чуть ли не арифметически, а на ум прежде всего приходят всякие интегралы Лебега и функции Бесселя. Вот начинаешь обучать нейронную сеть, потом добавляешь еще парочку скрытых слоев, экспериментируешь с количеством нейронов, функциями активации, потом вспоминаешь о SVM и Random Forest и начинаешь все сначала. И все же, несмотря на прямо таки изобилие занимательных статистических методов обучения, линейная регрессия остается одним из популярных инструментов. И для этого есть свои предпосылки, не последнее месте среди которых занимает интуитивность в интерпретации модели.Заочное обучение в ШАД Яндекса: 570 замечательных часов моей жизни
6 мин
 Два года назад на меня сильное впечатление произвела хабрастатья «Стивен Вольфрам проанализировал свою жизнь». К тому времени я уже года два записывал в Google-календаре, что и когда я делал, но к тому моменту я не задумывался, о том, что можно сделать с этой информацией. После прочтения той статьи, я понял: эту информацию можно анализировать! Сейчас я могу посчитать сколько раз мы с друзьями собирались играть в баскетбол за эти годы, сколько часов я провёл в больнице и т. п.
Два года назад на меня сильное впечатление произвела хабрастатья «Стивен Вольфрам проанализировал свою жизнь». К тому времени я уже года два записывал в Google-календаре, что и когда я делал, но к тому моменту я не задумывался, о том, что можно сделать с этой информацией. После прочтения той статьи, я понял: эту информацию можно анализировать! Сейчас я могу посчитать сколько раз мы с друзьями собирались играть в баскетбол за эти годы, сколько часов я провёл в больнице и т. п.На этой неделе я сделал последнюю домашнюю работу в ШАД и решил посчитать сколько времени у меня ушло на обучение, сколько я в среднем тратил в неделю, сколько строчек кода я написал и т. д. Построил несколько графиков и гистограмм, показал их друзьям и понял, что, возможно, такая информация будет интересна кому-либо ещё. Так что если вы хотите узнать сколько страниц отчётов было написано, насколько верна оценка нагрузки в ШАД в 15–20 часов в неделю, а также моё субъективное мнение о курсах в ШАД, то добро пожаловать под хабракат.
Let's fix NAs
5 мин
 Довольно часто встречаются неполные наборы данных, в которых некоторые переменные не определены. В языке R содержимое таких переменных задается как «Not Available» — или сокращенно NA. Соответственно, возникает вопрос, как поступать с неопределенными значениям: стоит ли их игнорировать или откорректировать каким-либо образом?
Довольно часто встречаются неполные наборы данных, в которых некоторые переменные не определены. В языке R содержимое таких переменных задается как «Not Available» — или сокращенно NA. Соответственно, возникает вопрос, как поступать с неопределенными значениям: стоит ли их игнорировать или откорректировать каким-либо образом? Шоппинг с распознаванием образов
1 мин
Новый интернет-магазин Modista собирает образцы товаров от сотен ритейлеров и забивает в единую базу данных (163 000 товаров по четырём категориям: обувь, часы, сумочки и очки). Далее на этой базе запускают движок распознавания образов с элементами самообучения.
Поиск покупки осуществляется исключительно через визуальный интерфейс. Щёлкаете по наиболее понравившемуся товару — и таблица перестраивается под новый шаблон. По горизонтали — подобие по форме, по вертикали — подобие по цвету.
Можно предположить, что похожие интерфейсы в будущем станут стандартным элементом любого интернет-магазина.

Поиск покупки осуществляется исключительно через визуальный интерфейс. Щёлкаете по наиболее понравившемуся товару — и таблица перестраивается под новый шаблон. По горизонтали — подобие по форме, по вертикали — подобие по цвету.
Можно предположить, что похожие интерфейсы в будущем станут стандартным элементом любого интернет-магазина.