Логирование и трассировка запросов — лучшие практики. Доклад Яндекса
7 мин
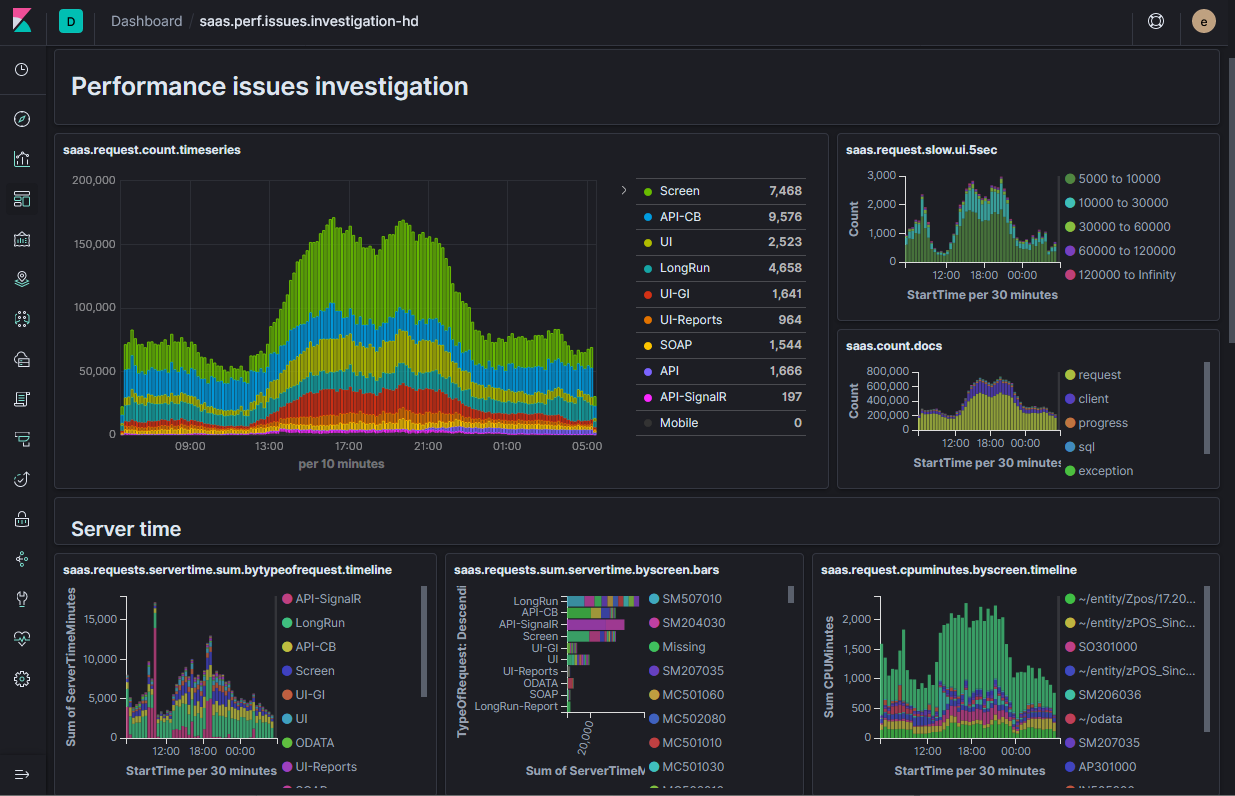
В Яндекс.Маркете большая микросервисная архитектура. Браузерный запрос главной страницы Маркета рождает десятки вложенных запросов в разные сервисы (бэкенды), которые разрабатываются разными людьми. В такой системе бывает сложно понять, по какой именно причине запрос упал или долго обрабатывался.
Анатолий Островский megatolya объясняет, как его команда решила эту проблему, и делится практиками, специфичными для Маркета, но в целом актуальными для любого большого сервиса. Его доклад основан на собственном опыте развёртывания нового маркетплейса в довольно сжатые сроки. Толя несколько лет руководил командой разработки интерфейсов в Маркете, а сейчас перешёл в направление беспилотных автомобилей.
Анатолий Островский megatolya объясняет, как его команда решила эту проблему, и делится практиками, специфичными для Маркета, но в целом актуальными для любого большого сервиса. Его доклад основан на собственном опыте развёртывания нового маркетплейса в довольно сжатые сроки. Толя несколько лет руководил командой разработки интерфейсов в Маркете, а сейчас перешёл в направление беспилотных автомобилей.