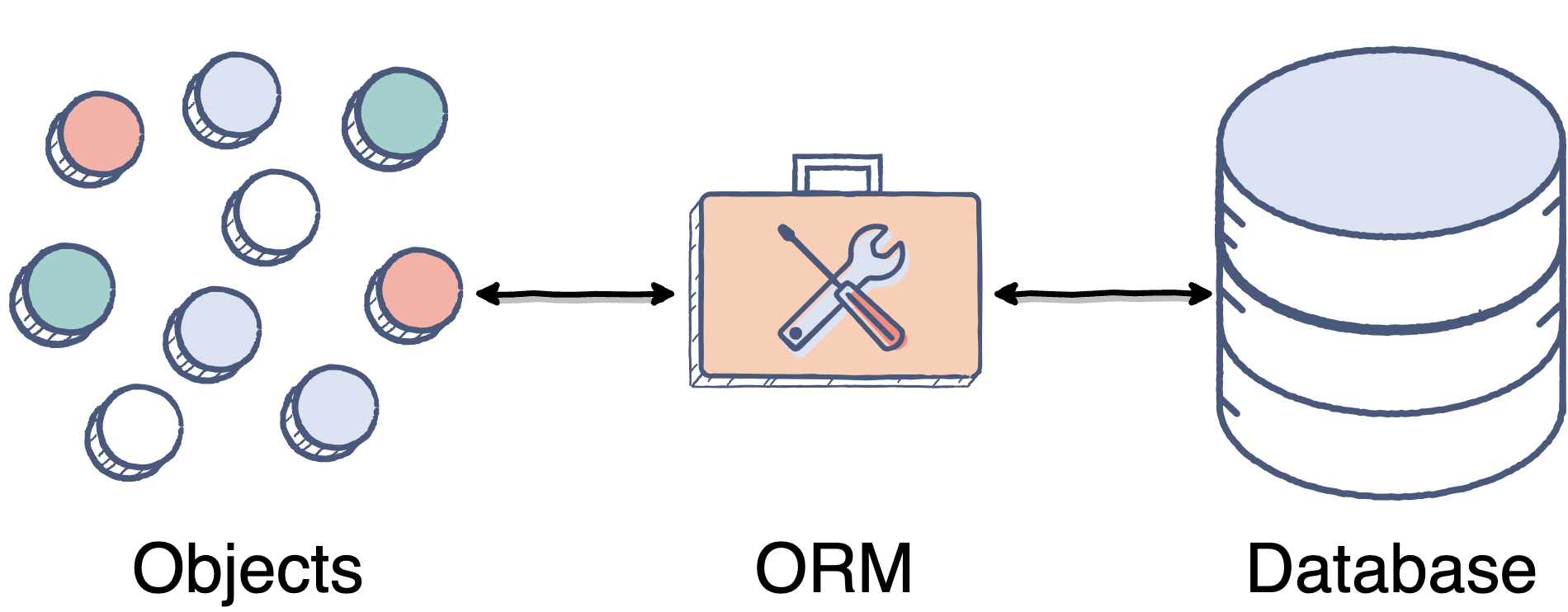
Распределенное управление конкурентностью
Простой
4 мин
Перевод

Управление конкурентным доступом является очень важной концепцией в Системе Управления Базами Данных. Оно гарантирует, что одновременное выполнение запросов несколькими процессами или пользователями оставит данные в согласованном состоянии. Особое место занимает доступ к Базе Данных в распределенной системе с множеством конкурирующих за ресурс узлов.