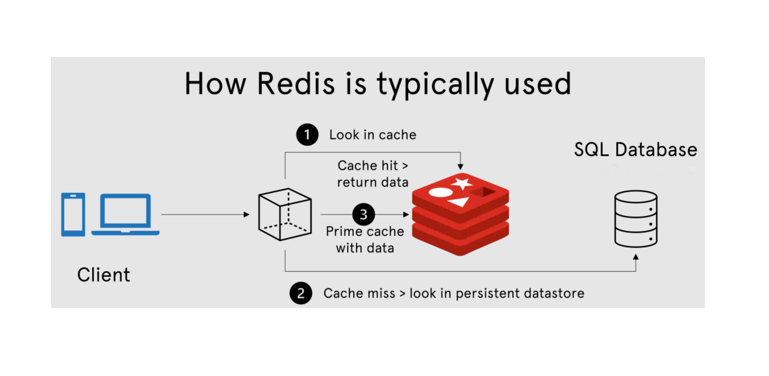
На кластерах клиентов, которые мы обслуживаем, есть как «одноголовые» инсталляции Redis (обычно для кэшей, которые не страшно потерять), так и более отказоустойчивые решения — Redis Sentinel или Redis Cluster. По нашему опыту, во всех трех вариантах можно безболезненно переключиться с Redis на KeyDB и получить прирост производительности. Точнее, избавиться от бутылочного горлышка Redis в одно ядро. Хотя в новых версиях Redis(r) появилась обработка I/O в отдельных тредах, иногда этого бывает недостаточно.
В то же время, если мы хотим использовать отказоустойчивые решениями вроде Sentinel и Cluster, нам понадобится поддержка этих технологий на уровне библиотеки, которую приложение использует для подключения в Redis. Причем лишь немногие библиотеки умеют читать из реплик Redis — в обоих вариантах (Sentinel и Cluster) чтение, как правило, происходит с мастеров. И запись, естественно, тоже происходит в мастеры.
В итоге у нас есть несколько реплик довольно дорогого in-memory-хранилища, а в рабочем процессе используется только часть из них. Остальные — на подхвате. Хотя в большинстве кейсов операции с in-memory NoSQL DB — это именно операции чтения.
Однако если посмотреть в сторону KeyDB, то можно увидеть, что там есть киллер-фича — и даже две: я говорю о режимах Active Replica и Multi-Master. Использование этих режимов позволяет получить распределенный отказоустойчивый KeyDB, совместимый с Redis, писать в любую ноду, читать из любой ноды. И все это с точки зрения приложения выглядит как один экземпляр Redis без всяких Sentinel — то есть в коде приложения ничего менять не придется.
Звучит как фантастика?