Оберон умер, да здравствует Оберон! Часть 1. Некоторые любят поактивней
5 мин
Языкам программирования семейства Оберон не суждено было прорваться в мейнстрим, хотя они и оставили заметный след в IT-индустрии. Однако, и операционные системы, написанные на этих языках (являясь одновременно и программными каркасами различных решений и средами разработки), и сами языки программирования используются в учебной, исследовательской и промышленной сферах и по сей день, понуждая к творчеству и экспериментам, развиваясь и впитывая новые веянья индустрии и влияя на неё.
Этой обзорной статьёй я открываю серию статей, посвящённых языку Активный Оберон и операционной системе A2, написанной на этом языке.
Первая публикация по Активному Оберону появилась в 1997 году, но понятно, что язык и его реализация появились несколько раньше. За эти годы произошло много изменений в языке, переработана среда времени выполнения, написана операционная система A2…
Этой обзорной статьёй я открываю серию статей, посвящённых языку Активный Оберон и операционной системе A2, написанной на этом языке.
Итак, встречайте — Активный Оберон
Первая публикация по Активному Оберону появилась в 1997 году, но понятно, что язык и его реализация появились несколько раньше. За эти годы произошло много изменений в языке, переработана среда времени выполнения, написана операционная система A2…

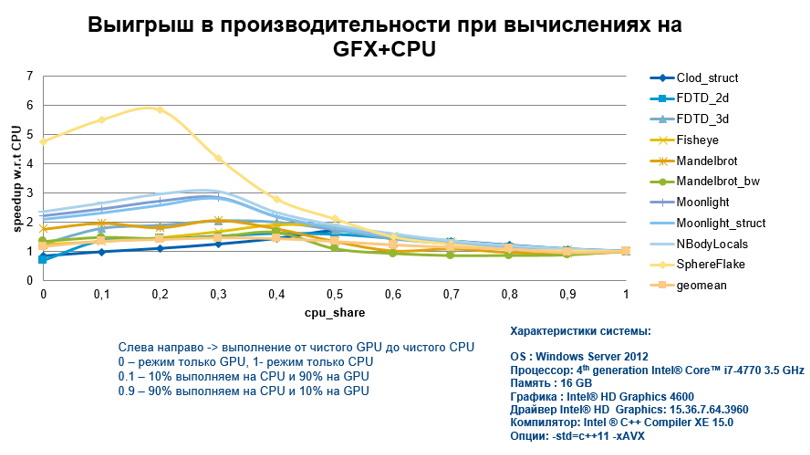
 Это последняя, на сегодняшний день, статья из цикла про внутреннее устройство конкурентных ассоциативных контейнеров. В предыдущих статьях рассматривались hash map, был построен алгоритм lock-free ordered list и контейнеры на его основе. За бортом остался один важный тип структур данных — деревья. Пришло время немного рассказать и о них.
Это последняя, на сегодняшний день, статья из цикла про внутреннее устройство конкурентных ассоциативных контейнеров. В предыдущих статьях рассматривались hash map, был построен алгоритм lock-free ordered list и контейнеры на его основе. За бортом остался один важный тип структур данных — деревья. Пришло время немного рассказать и о них.