
Асинхронные задачи в С++11
5 мин
Доброго времени суток, хотел бы поделиться с сообществом своей небольшой библиотектой.
Я программирую на С/C++, и, к сожалению, в рабочих проектах не могу использовать стандарт C++11. Но вот пришли майские праздники, появилось свободное время и я решил поэкспериментировать и по-изучать этот запретный плод. Самое лучшее для изучения чего либо — это практика. Чтение статей о языке программирования научит максимум лучше читать, поэтому я решил написать маленькую библиотеку для асинхронного выполнения функций.
Сразу оговорюсь, что я знаю, что существует std::future, std::async и тп. Мне было интересно реализовать самому нечто подобное и окунуться в мир лямбда-функций, потоков и мьютексов с головой. Праздники — отличное время для велопрогулок.
Я программирую на С/C++, и, к сожалению, в рабочих проектах не могу использовать стандарт C++11. Но вот пришли майские праздники, появилось свободное время и я решил поэкспериментировать и по-изучать этот запретный плод. Самое лучшее для изучения чего либо — это практика. Чтение статей о языке программирования научит максимум лучше читать, поэтому я решил написать маленькую библиотеку для асинхронного выполнения функций.
Сразу оговорюсь, что я знаю, что существует std::future, std::async и тп. Мне было интересно реализовать самому нечто подобное и окунуться в мир лямбда-функций, потоков и мьютексов с головой. Праздники — отличное время для велопрогулок.






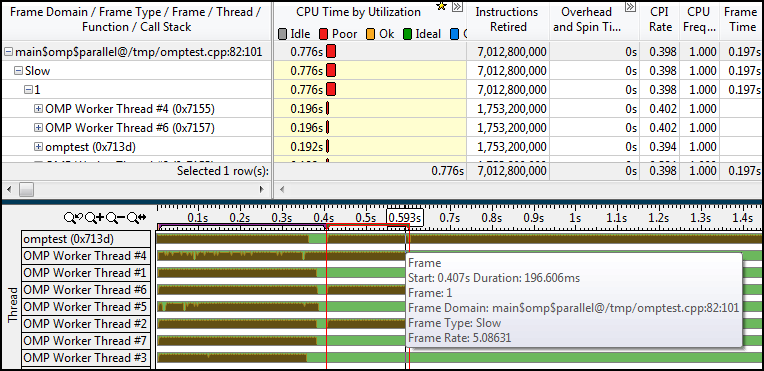
 C января этого года Билл Макклоски вместе с Дэвидом Андерсоном работали над тем, чтобы сделать «Файерфокс» мультипроцессовым, в этом им помогали Том Шустер (evilpie), Фелипе Гомез и Марк Хаммонд. И теперь настал момент, когда они
C января этого года Билл Макклоски вместе с Дэвидом Андерсоном работали над тем, чтобы сделать «Файерфокс» мультипроцессовым, в этом им помогали Том Шустер (evilpie), Фелипе Гомез и Марк Хаммонд. И теперь настал момент, когда они 
 От переводчика: Это вторая статья из
От переводчика: Это вторая статья из 
