Backend-разработчик: из стажера в джуны
5 мин
Кейс

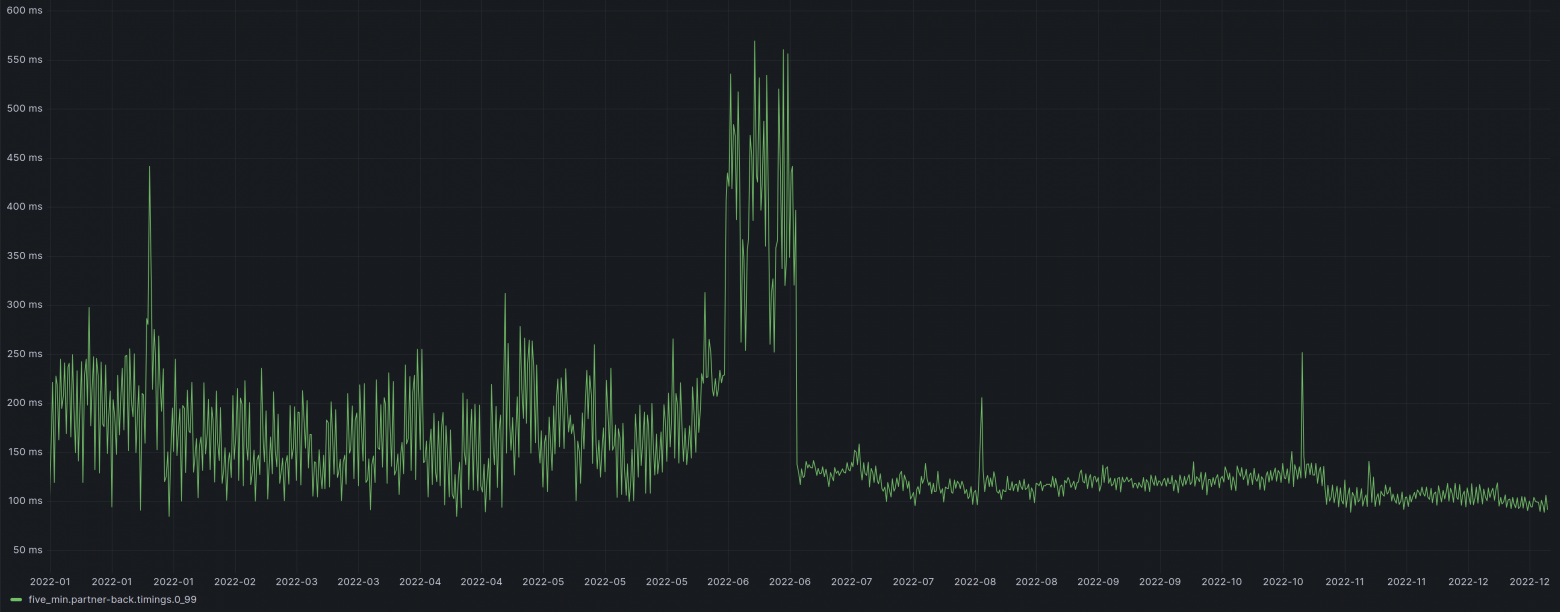
Всем привет! Меня зовут Егор, я стажёр backend-разработчик в зарплатном проекте Росбанка (он же Payroll). В этой статье я расскажу про путь становления от «зеленого» стажера до боевой единицы в команде: через что мне пришлось пройти, с какими трудностями я столкнулся и как прокачал свои скилы.