Инструкция по бэкапу одной базы в Postgres – миф или реальность
Простой
10 мин
Туториал

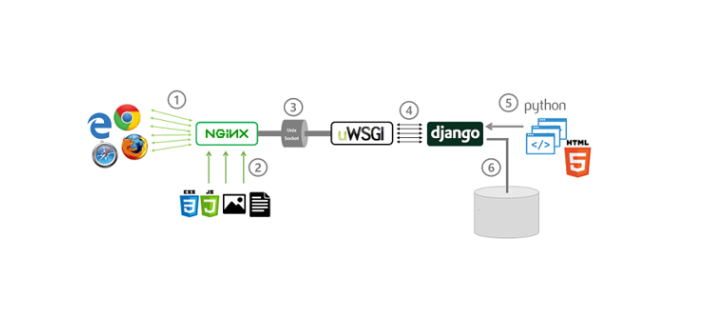
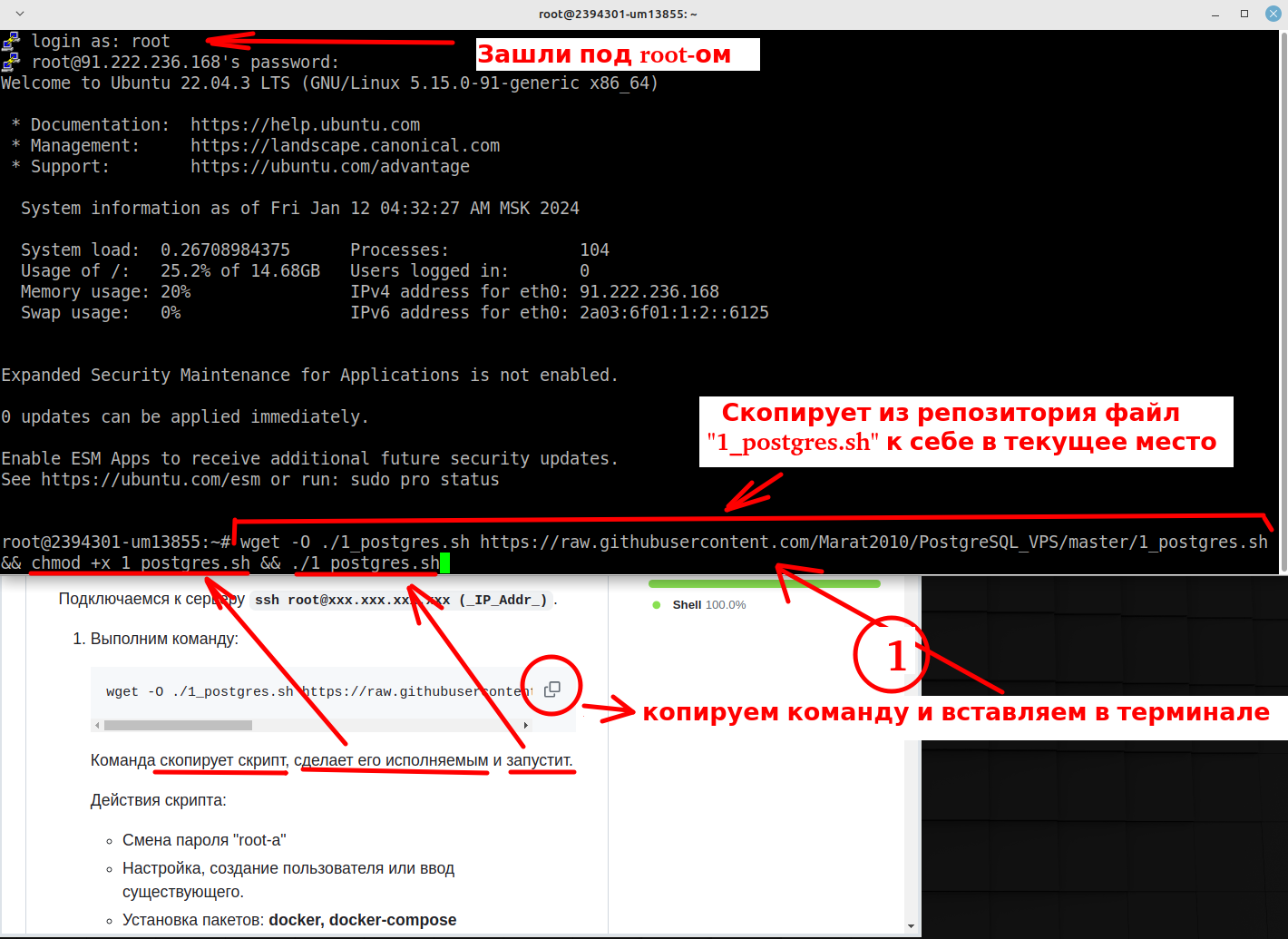
Бэкап в Postgres состоит из набора граблей, которые нужно обойти для успешного восстановления. Они заложены в самых неожиданных местах от предмета резервного копирования (база или кластер), до структуры каталогов. Один неверный шаг и восстановление будет невозможным. Почему нельзя было сделать проще как в MS SQL или Oracle? Почему бэкап в Postgres оставляет впечатление чьей то лабораторной работы? Статья адресована прежде всего специалистам 1С избалованным комфортом в MS SQL, в суровых буднях импортозамещения на Postgres.