

Postgres auto_explain: автолог плана запроса
Снова о деревьях
Что нового в PostgreSQL 11: JSONB-трансформы

В предыдущих постах вы могли прочитать про INCLUDE-индексы и встроенный веб-поиск. Эти фичи появятся в PostgreSQL 11, релиз которого, напомню, планируется в октябре. Сегодня мне хотелось бы продолжить обзор новых фичей грядущего релиза, рассказав про JSONB-трансформы для языков PL/Python (3f44e3db) и PL/Perl (341e1661). Оба патча написаны Антоном Быковым.
Дайджест новостей из мира PostgreSQL. Выпуск №5

Feature freeze
Это, конечно, главное событие для сообщества. То, что не прошло только что закончившийся комитфест, не попадет в версию PostgreSQL 11.
Что заморозили на feature freeze
Это наша сводка попавших в нее важнейших патчей.
Сводка сводкой, а статьи об PostgreSQL 11 уже начали появляться. А дальше — больше.
Waiting for PostgreSQL 11 – Transforms for jsonb to PL/Python and to PL/Perl
Депеш, то есть Хуберт 'depesz' Любашевски, пишет в своем блоге о 2 соответствующих патчах Антона Быкова из Postgres Professional.
Postgres 11 highlight — Covering Indexes
В своем блоге Мишель Пакье (Michael Paquier) пишет о покрывающих индексах (см также статью Что нового в PostgreSQL 11: INCLUDE-индексы Александра Алексеева из Postgres Professional и комментарии к ней). На эту же тему — INCLUDE-индексов — статья Waiting for PostgreSQL 11: Covering + unique indexes Алексея Лесковского из Data Egret.
Partition Elimination in PostgreSQL 11
По поводу этого серьезного достижения 11-й версии пишет в своей статье Дэвид Роули (David Rowley) из 2ndQuadrant.
Об еще одном патче, прошедшем в PostgreSQL 11, пишет в статье Что нового в PostgreSQL 11: встроенный веб-поиск тот же Александр Алексеев.
Manipulating checksums of a cluster
Мишель Пакье пишет еще об одном патче PostgreSQL 11. Патч проверяет чексуммы страниц после штатной остановки кластера. Более того, он предлагает свою утилиту pg_checksums на базе этого патча.

DevConf: переход Uber с PostgreSQL на MySQL

История вопроса
Uber перешел с MySQL на Postgres в 2013 году и причины, которые они перечисляют, были во-первых: PostGIS — это геоинформационное расширение для PostgreSQL и хайп. То есть, у PostgreSQL есть некий ореол серьезный, солидная СУБД, совершенный, без недостатков. По крайней мере, если сравнивать с MySQL. Они мало что знали о PostgreSQL, но повелись на весь этот хайп и перешли, а через 3 года пришлось переезжать обратно. И основные причины, если просуммировать их доклад — это плохие эксплуатационные характеристики при эксплуатации в production.
Что заморозили на feature freeze

8-го апреля закончился комитфест 2018-03. Те патчи, которые не закомичены на нем (и на 3 предыдущих комитфестах) уже не попадут в релиз PostgreSQL 11: произошла заморозка функциональности (feature freeze). Время подводить итоги.
Главные новости последнего комитфеста (и версии 11 соответственно):
- увесистый набор патчей для секционирования.
- JIT-компиляции посвящен только один патч, но это шаг в направлении, которое в будущем наверняка будет развиваться интенсивно.
- «покрывающие» индексы (INCLUDE-индексы). Это тема уже активно обсуждается и продолжается в разработках.
- Серия патчей в группе процедурных языков. Они важны в том числе для совместимости со стандартами SQL и миграции с Oracle.
- Интересные, но не столь резонансные патчи.
Начнем в произвольном порядке.
Postgres Enum
На скорую руку попытался понять что это для бд и для клиента вообще:
- enum — статический упорядоченный набор значений
- Значение enum занимает на диске 4 байта
- Регистр имеет значение, т. е. 'happy' и 'HAPPY' — не одно и то же
- Разные enum сравнивать меж собой нельзя (можно, если привести к общему типу или запилить операторы для них)
- Невозможно в колонку перечисляемого типа подсунуть значение, которое отсутствует в самом перечислении
Ок, вроде всё как обычно, только в Postgres
Секционирование в PostgreSQL 10 и не только

У многих достижений версии PostgreSQL 10 прописка в разделе Секционирование (Partitioning). И это справедливо: очевидно, что при переходе от 9.6 к 10 произошел мощный технологический скачок. В предыдущих версиях секции строили и управляли ими, теми средствами, что уже имелись: механизмом наследования со всеми его ограничениями и неудобствами.
В версии 10 перешли к более специализированным механизмам и более привычному (в том числе для пользователей Oracle, а с этим приходится считаться) синтаксису. Этот скачок при переходе от 10 к версии 11 должен был подкрепиться важными дополнениями, которые должны расширить функциональность и улучшить производительность операций, использующих секционирование. Но из итогов последнего комитфеста (он закончился 8 апреля) видно, что не все задуманное удалось довести до рабочего состояния, а значит не все попадет в версию 11.
К тому же последние пару лет параллельно велись разработки модуля pg_pathman в Postgres Professional. Некоторые важные возможности пересеклись, некоторые остались уникальны для PostgreSQL и pg_pathman (который работает с ванильной версией, то есть PostgreSQL 10 + pg_pathman дает уже вполне впечатляющую сумму функциональности). Об этом будет отдельная статья. Замечания, относящиеся к версии 11 и к pg_pathman для удобства выделены курсивом.
Эта статья представляет собой переработанные и дополненные фрагменты книжки Nouveaulités de PostgreSQL 10. (с) Dalibo, перевод с французского Игоря Лёвшина (оригинал). Примеры из книги проверены, иногда адаптированы и локализованы для большей наглядности.
Что нового в PostgreSQL 11: INCLUDE-индексы

Релиз PostgreSQL 11 состоится еще не скоро, только в октябре. Но фичфриз уже наступил, а значит мы знаем, какие фичи попали в этот релиз, и можем их потестировать, собрав PostgreSQL из ветки master. Особого внимания заслуживает фича под названием INCLUDE-индексы. Патч изначально написан Анастасией Лубенниковой, а потом допилен Александром Коротковым и Федором Сигаевым. Протолкнуть его в PostgreSQL заняло «всего лишь» что-то около трех лет.
Spring Boot. Фоновые задачи и не только
Введение
В данном туториале я хочу привести пример приложения для отправки email-ов юзерам, основываясь на дате их рождения(например с поздравлениями), используя аннотацию Scheduled. Я решил привести данный пример, т к по моему мнению он включает в себя довольно многие вещи, такие как работа с базой данных(в нашем случает это PostgreSQL), Spring Data JPA, новый java 8 time api, email-сервис, создание фоновых задач и небольшую бизнес-логику при этом оставаясь компактным. Сегодня интернет пестрит огромным множеством туториалов которые обычно сводятся к тому как наследоваться от CrudRepository, JpaRepository и тд. Туториал расчитан на то, что вы уже смотрели хотя бы некоторые из них и имеете представление о том, что такое Spring Boot. Я же постараюсь показать пример приложения, которое более обширно показывает его возможности и как с ним работать.
Создание проекта
Идем на Spring Initializr.
Добавляем зависимости:
1. PosgreSQL — в качестве базы данных
2. JPA — доступ к базе
3. Lombok — для удобства и избавления от бойлерплейт кода(не придётся писать геттеры, сеттеры и тд самим), подробнее тут
4. Mail — собственно для работы и отправки email-ов, оф. документация
Указываем группу и артефакт, к примеру com.application и task. Скачиваем и распаковываем проект, затем открываем его в среде разработки, у меня это Intellij IDEA.
База данных
Теперь устанавливаем себе PostgreSQL. Далее создаём базу данных с юзером и паролем. Можно сделать это прямо из IDEA, во вкладке database, можно с помощью командной строки если у вас линукс, следующими командами:
sudo -u postgres createuser <username>
sudo -u postgres createdb <dbname>
$ sudo -u postgres psql
psql=# alter user <username> with encrypted password '<password>';
psql=# grant all privileges on database <dbname> to <username> ;Также на windows это можно сделать с помощью pgAdmin или его альтернатив.
Что нового в DataGrip 2018.1

Ближайшие события
Как ускорили PostgreSQL 10
(В статье использованы примеры и пояснения из книги Nouveaulités de PostgreSQL 10. (с) Dalibo, перевод с французского Игоря Лёвшина, редактор Егор Рогов (оригинал). Примеры проверены, иногда изменены для большей наглядности)
Конечно, мы уже ждем не дождемся появления 11-й версии PostgreSQL. Но уже сейчас ясно, что некоторые довольно радикальные улучшения производительности появились уже в версии 10. Определенно есть смысл разобраться сначала с ними.
Производительность "десятки" улучшилась сразу в нескольких направлениях. В этой статье речь пойдет об ускорении за счет:
- распараллеливания сканирования таблиц и индексов,
- более эффективного агрегирования,
- быстрых переходных таблиц,
- ускорения запросов за счет многоколоночной статистики.
Мы начнем с параллелизма.
DZ Online Tech: Postgres Professional
В прошлом году я начал снимать серию передач/интервью на тему цифровой трансформации бизнеса (они тут, кому интересно — подписывайтесь). Эти передачи были на стыке IT и бизнеса, но, всё же, больше про бизнес.
В процессе стало понятно, что есть немало тем, которые имеют существенную глубину с программерской точки зрения. И в этом году мы начали снимать серию интервью под общим лейблом «DZ Online Tech» — теперь уже с упором на то, что под капотом. Ну и поскольку видео всем смотреть лень, конечно, эти интервью расшифровываются, и сегодня я публикую первое — с Иваном Панченко из Postgres Professional.
Кому интересен оригинал — вот он:
(Ну и, кстати, я не могу поклясться, что все выпуски будут выходить в расшифровке, так что если понравилось — подписывайтесь на ютубе, туда всё приходит раньше и гарантированно.)
Для тех, кто любит читать — расшифровка:
Дайджест новостей из мира PostgreSQL. Выпуск №4

Мы продолжаем знакомить вас с самыми интересными новостями по PostgreSQL.
Релизы
Вышел PostgreSQL 10.3
В этом релизе закрыта дыра безопасности: неконтролируемый путь поиска объектов в схемах БД в pg_dump и других приложениях. Среди других исправлений: теперь логическая репликация не будет пытаться передавать изменения, если таблицы запрещены для публикации. Также вышли обновленные версии 9.x.
Версия Postgres Pro Standard 10.3.1 вышла в тот же день, что и PostgreSQL 10.3, так как необходимо было залатать дыру как можно быстрее. Сейчас доступны уже Postgres Pro Standard 10.3.2 и Postgres Pro Enterprise 10.3.2. В них в том числе добавлена поддержка TOAST для атрибутов INCLUDED в индексах-B-деревьях. Серьезно усовершенствована утилита pg_probackup (теперь это версия 2.0.16).
Почему ставить наиболее селективные колонки в префикс составного индекса – это не всегда хорошо
tl;dr В этой статье мы рассмотрим случай, когда лучше переместить самый селективный атрибут из префикса составного индекса в суффикс.
А также рассмотрим, что такое pipeline и как с его помощью select-ить данные уже отсортированными.

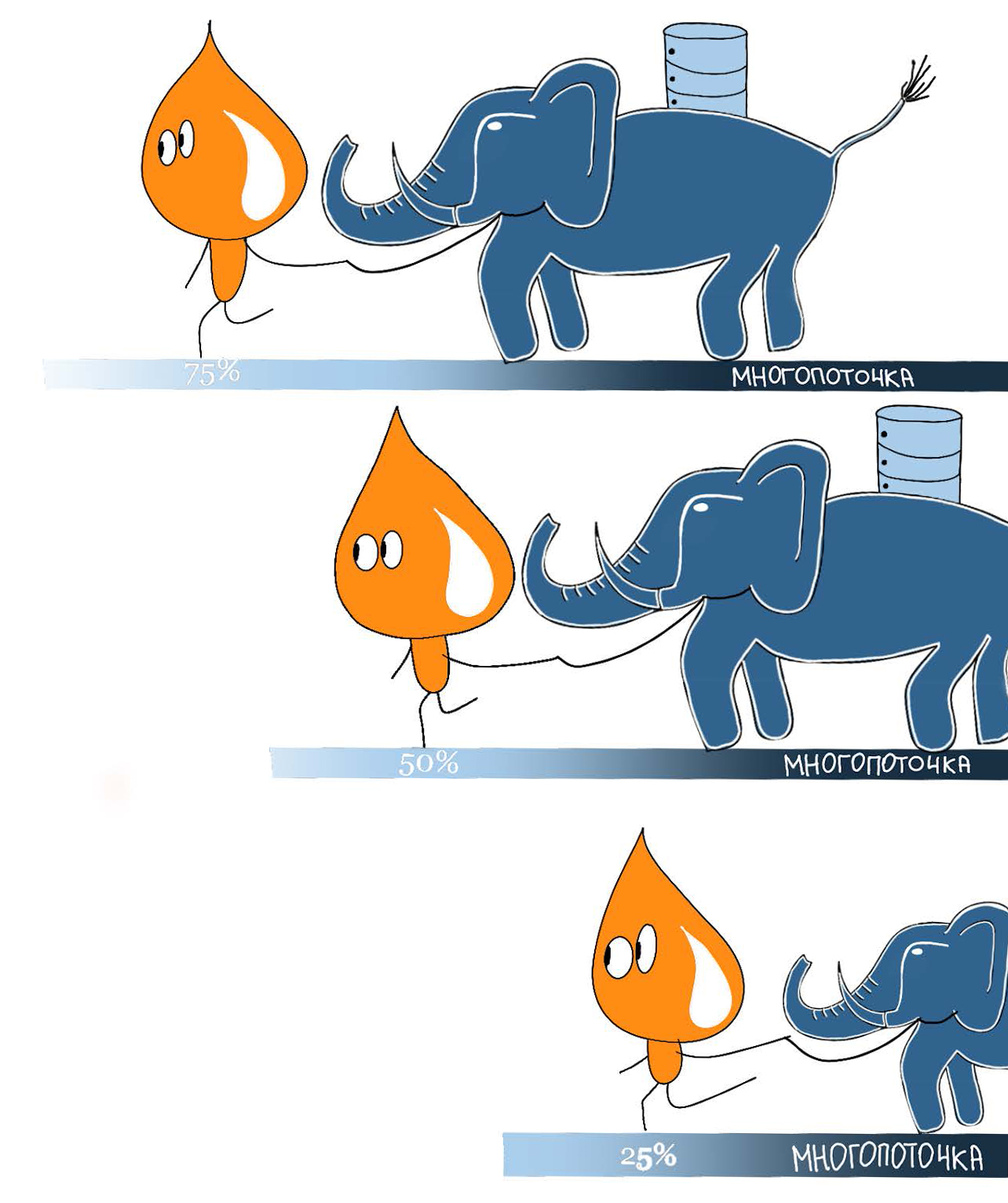
#PostgreSQL. Ускоряем деплой в семь раз с помощью «многопоточки»
Почему фотография Скарлетт Йоханссон заставила PostgresSQL майнить Monero
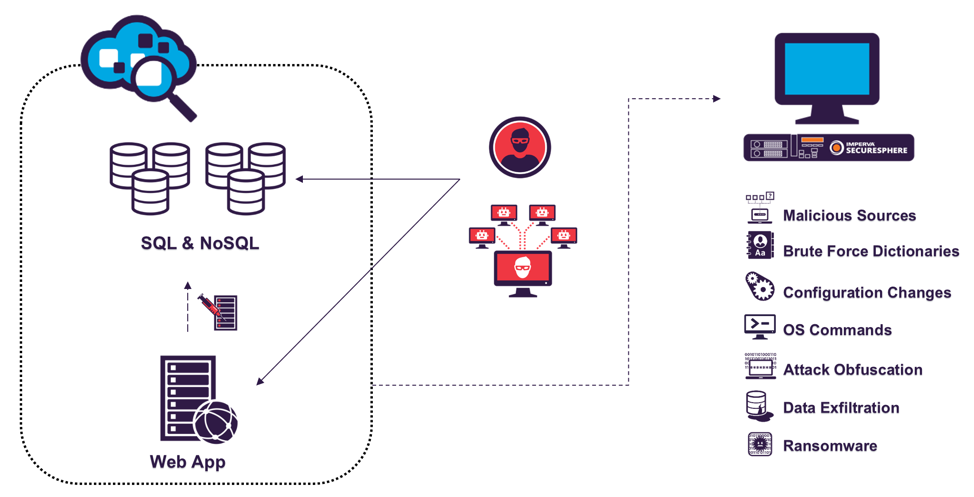
Рис. 1. Сетевое окружение ханипота StickyDB
Недавно мы обнаружили интересную технику в ходе атаки одного из серверов PostgreSQL. После входа в БД злоумышленник продолжал создавать полезные нагрузки из встроенных бинарников в скачанных картинках, сохранять полезные нагрузки на диск и запускать их. Как часто бывает в последнее время, злоумышленник захватил ресурсы сервера для майнинга Monero. Как будто этого мало, вектором атаки была фотография Скарлетт Йоханссон. Ну тогда ладно. Разберёмся, как это работает!
Установка сервера Linux + (Nginx + Apache) + PostgreSQL + PHP на VirtualBox (Ubuntu Server 16.04.3 LTS)
Принцип работы следующий:
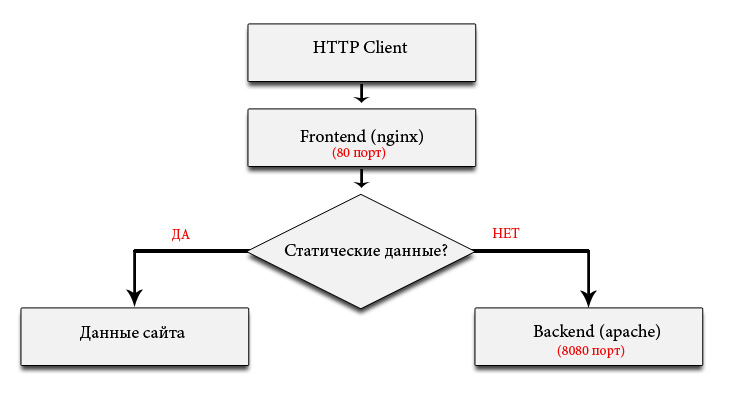
Статические данные (файлы) отдает Nginx, а динамикой занимается Apache.