
ZSON: расширение PostgreSQL для прозрачного сжатия JSONB
4 мин
Туториал

Недавно мы выложили на GitHub ZSON. ZSON — это расширение к PostgreSQL для прозрачного сжатия JSONB-документов. Сжатие осуществляется путем выделения строк, наиболее часто встречающихся в ваших документах, и построения словаря с этими строками. Притом строки могут быть не только ключами документа, но и значениями или, например, строками из вложенных массивов. В некоторых случаях ZSON позволяет уменьшить размер базы до двух раз и увеличить количество транзакций в секунду на 10%. В shared buffers документы хранятся в сжатом виде, за счет чего память тоже экономится.
Интересно? Читайте дальше, и вы узнаете, как пользоваться всем этим хозяйством на практике.
 Здравствуй, Хабр! Мы начинаем блог об Idea Platform — платформе для автоматизации бизнес-процессов.
Здравствуй, Хабр! Мы начинаем блог об Idea Platform — платформе для автоматизации бизнес-процессов.  Целостность данных легко нарушить. Бывает так, что в поле price попадает значение 0 из-за ошибки в коде приложения (периодически всплывают новости, как в том или ином инет-магазине продавали товары по 0 долларов). Или бывает, что удалили юзера из таблицы, но какие-то данные о нем остались в других таблицах, и эти данные вылезли в каком-то интерфейсе.
Целостность данных легко нарушить. Бывает так, что в поле price попадает значение 0 из-за ошибки в коде приложения (периодически всплывают новости, как в том или ином инет-магазине продавали товары по 0 долларов). Или бывает, что удалили юзера из таблицы, но какие-то данные о нем остались в других таблицах, и эти данные вылезли в каком-то интерфейсе. В 2008 году в списке рассылки pgsql-hackers началось
В 2008 году в списке рассылки pgsql-hackers началось 

 При проектировании достаточно объёмных реляционных баз данных часто принимается решение об отступлении от
При проектировании достаточно объёмных реляционных баз данных часто принимается решение об отступлении от 
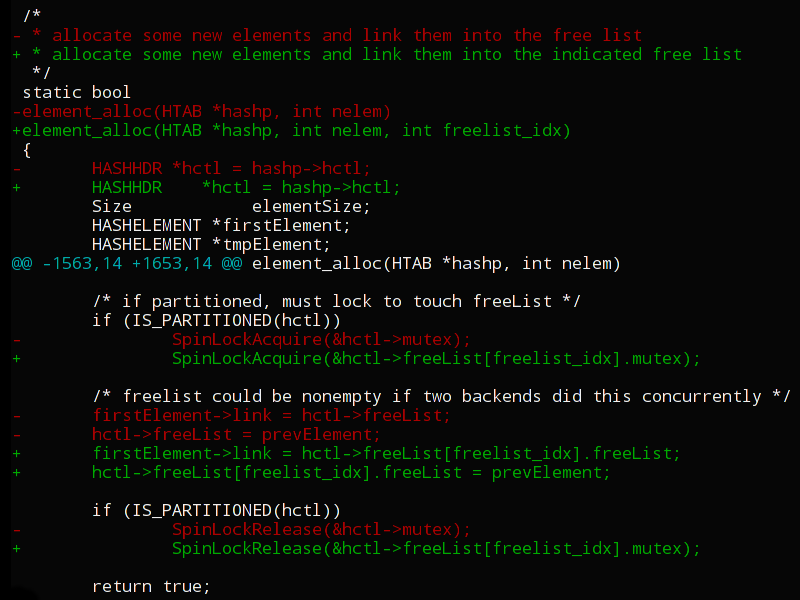

 Многие пользуются
Многие пользуются 
 В этой статье я хотел бы рассказать о том, как выглядит процесс разработки PostgreSQL глазами одного из контрибьютеров в этот самый PostgreSQL. Заниматься разработкой этой СУБД я начал в декабре 2015 года, когда устроился работать в компанию Postgres Professional. То есть, не так уж давно. А значит, еще свежи воспоминания о моментах, которые поначалу казались мне не вполне очевидными. Хотелось бы их законспектировать, чтобы новым людям, приходящим в нашу команду, а также всем тем, кто желает попробовать себя в роли разработчика открытой реляционной СУБД, было легче. Я расскажу о том, как выглядит процесс разработки PostgreSQL, какие инструменты я использую в своей повседневной работе, как следует оформлять патчи, и так далее. Заинтересовавшихся прошу проследовать под кат.
В этой статье я хотел бы рассказать о том, как выглядит процесс разработки PostgreSQL глазами одного из контрибьютеров в этот самый PostgreSQL. Заниматься разработкой этой СУБД я начал в декабре 2015 года, когда устроился работать в компанию Postgres Professional. То есть, не так уж давно. А значит, еще свежи воспоминания о моментах, которые поначалу казались мне не вполне очевидными. Хотелось бы их законспектировать, чтобы новым людям, приходящим в нашу команду, а также всем тем, кто желает попробовать себя в роли разработчика открытой реляционной СУБД, было легче. Я расскажу о том, как выглядит процесс разработки PostgreSQL, какие инструменты я использую в своей повседневной работе, как следует оформлять патчи, и так далее. Заинтересовавшихся прошу проследовать под кат.