Редко когда кандидат проходит только одно техническое собеседование — обычно их несколько. Среди причин, почему человеку они могут даваться непросто, можно назвать и ту, что каждый раз приходится общаться с новыми людьми, думать о том, как они восприняли твой ответ, пытаться интерпретировать их реакцию. Мы решили попробовать использовать формат контеста, чтобы сократить количество итераций для всех участников процесса.

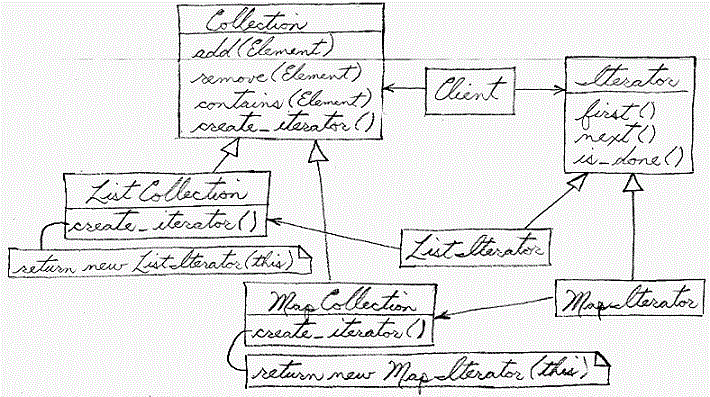
Для Блица мы выбрали исключительно алгоритмические задачи. Хотя для оценки раундов и применяется система ACM, в отличие от спортивного программирования все задания максимально приближены к тем, которые постоянно решают в продакшене Поиска. Те, кто решит успешно хотя бы четыре задачи из шести, могут считать, что прошли первый этап отбора в Яндекс. Почему алгоритмы? В процессе работы часто меняются задачи, проекты, языки программирования, платформы — те, кто владеет алгоритмами, всегда смогут перестроиться и быстро научиться новому. Типичная задача на собеседовании — составить алгоритм, доказать его корректность, предложить пути оптимизации.
Квалификацию можно пройти с 18 по 24 сентября включительно. В этом раунде вам нужно будет написать программы для решения шести задач. Можете использовать Java, C++, C# или Python. На всё про всё у вас будет четыре часа. В решающем раунде будут соревноваться те, кто справится как минимум с четырьмя квалификационными задачами. Финал пройдёт одновременно для всех участников — 30 сентября, с 12:00 до 16:00 по московскому времени. Итоги будут подведены 4 октября. Чтобы всем желающим было понятно, с чем они столкнутся на Блице, мы решили разобрать пару похожих задач на Хабре.







 Приветствую вас, коллеги. Оказывается, не все компьютерное зрение сегодня делается с использованием нейронных сетей. Хотя многие стартапы и заявляют, что у них дип лернинг везде, спешу вас разочаровать, они просто хотят хайпануть немножечко. Рассмотрим, например, задачу сегментации. В
Приветствую вас, коллеги. Оказывается, не все компьютерное зрение сегодня делается с использованием нейронных сетей. Хотя многие стартапы и заявляют, что у них дип лернинг везде, спешу вас разочаровать, они просто хотят хайпануть немножечко. Рассмотрим, например, задачу сегментации. В  Всем привет! Это уже семнадцатый выпуск дайджеста на Хабрахабр о новостях из мира Python.
Всем привет! Это уже семнадцатый выпуск дайджеста на Хабрахабр о новостях из мира Python.