Разработка программ высокого качества подразумевает, что программа и её части подвергаются тестированию. Классическое модульное (unit) тестирование подразумевает разбиение большой программы на маленькие блоки, удобные для тестов. Либо, если разработка тестов происходит параллельно с разработкой кода или тесты разрабатываются до программы (TDD — test driven development), то программа изначально разрабатыватся небольшими блоками, подходящими под требования тестов.
Одной из разновидностей модульного тестирования можно считать propery-based testing (такой подход реализован, например, в библиотеках QuickCheck, ScalaCheck). Этот подход основан на нахождении универсальных свойств, которые должны быть справедливы для любых входных данных. Например, сериализация с последующей десериализацией должна давать такой же объект. Или, повторная сортировка не должна менять порядок элементов в списке. Для проверки таких универсальных свойств в вышеупомянутых библиотеках поддерживается механизм генерации случайных входных данных. Особенно хорошо такой подход работает для программ, основанных на математических законах, которые служат универсальными свойствами, справедливыми для широкого класса программ. Есть даже библиотека готовых математических свойств — discipline — позволяющая проверить выполнение этих свойств в новых программах (хороший пример повторного использования тестов).
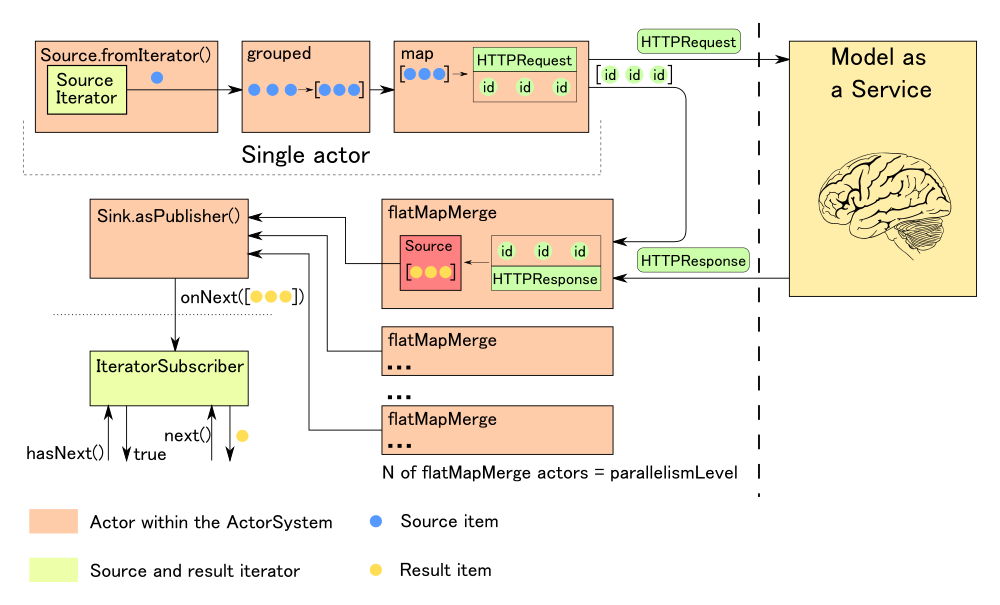
Иногда оказывается, что необходимо протестировать сложную программу, не имея возможности разобрать её на независимо проверяемые части. В таком случае тестируемая программа представляет собой черный белый ящик (белый — потому что мы имеем возможность изучать внутреннее устройство программы).
Под катом описаны несколько подходов к тестированию сложных программ с одним входом с разной степенью сложности (вовлеченности) и разной степенью покрытия.













 Долгое время я мечтал научиться работать с FPGA, присматривался. Потом купил отладочную плату, написал пару hello world-ов и положил плату в ящик, поскольку было непонятно, что с ней делать. Потом пришла идея: а давайте напишем генератор композитного видеосигнала для древнего ЭЛТ-телевизора. Идея, конечно, забавная, но я же Verilog толком не знаю, а так его ещё и вспоминать придётся, да и не настолько этот генератор мне нужен… И вот недавно захотелось посмотреть в сторону
Долгое время я мечтал научиться работать с FPGA, присматривался. Потом купил отладочную плату, написал пару hello world-ов и положил плату в ящик, поскольку было непонятно, что с ней делать. Потом пришла идея: а давайте напишем генератор композитного видеосигнала для древнего ЭЛТ-телевизора. Идея, конечно, забавная, но я же Verilog толком не знаю, а так его ещё и вспоминать придётся, да и не настолько этот генератор мне нужен… И вот недавно захотелось посмотреть в сторону