Отказоустойчивый сервер печати на базе Windows
12 мин
Туториал
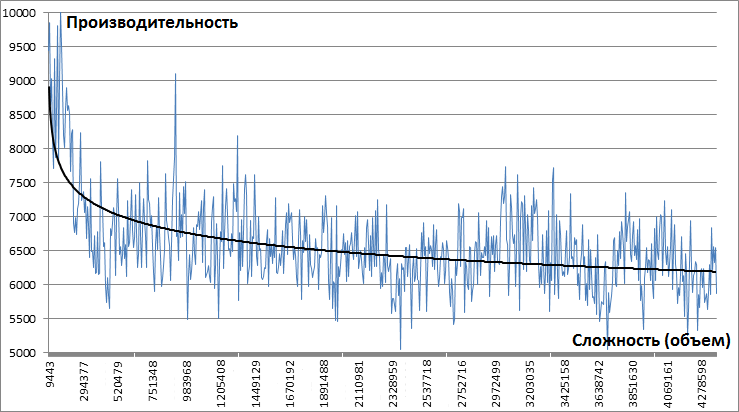
Настоящий админ может спать спокойно лишь тогда, когда у него всё бэкапится, мониторится и дублируется.
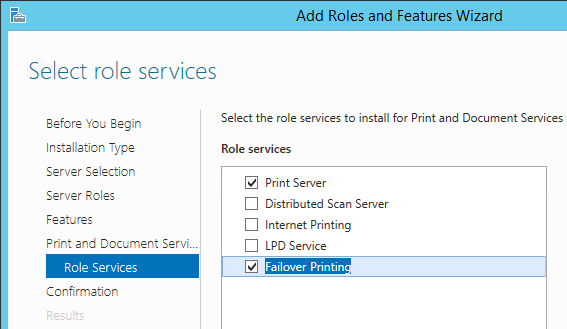
Так получилось, что я в своей работе использую в основном продукты Microsoft и могу сказать, что компания серьезно подходит к резервированию своих сервисов: Active Directory, Exchange DAG, SQL Always On, DFSR и т.д. Как и везде, здесь есть как весьма изящные и удачные реализации, так и явно неудобные и тяжелые. Для сервиса печати тоже есть решение, но для него необходима кластеризация на базе Hyper-V. А хотелось простого решения “из коробки”, не требующего дополнительных финансов. За основу была взята Windows 2012 R2, но скорее всего та же схема без проблем будет работать на любых серверных версиях, начиная с Windows 2008, и даже клиентских ОС от Vista и выше (привет любителям экономить бюджет!). Кому интересно — прошу под кат.







 Не так давно мы публиковали статью
Не так давно мы публиковали статью