Этой весной мне удалось, наконец, реализовать давнюю мечту строителей конструкторов: встроить среди американских патентов четвертьвековой давности очень простое решение всех их проблем. По сути — это эмуляция базы данных приложения, при построении которого вся черновая, рутинная работа программиста вынесена «за скобки».
В снове решения — система хранения данных и способ их обработки, результат — альтернатива существующим ORM. Заявленные преимущества: повышение надёжности базы данных за счёт минимизации ошибок при добавлении новых данных и формировании запросов к ним, а также снижение риска лавинообразной деградации производительности при работе с большими объемами данных (с любыми объемами).
Оно не меняет принципиально структуру физического хранения данных, в нем всё происходит точно так же, как в обычном приложении с базой данных: информация хранится на носителе, она фрагментирована, со временем фрагментация увеличивается. При запросах данных так же происходит множество чтений разрозненных фрагментов информации с диска.
Больше того — это может работать в обычной реляционной БД.
Но есть нюансы.

В целом, сейчас те мечты 90-х уже не так актуальны, есть множество различных ORM, и их проблемы менее заметны на фоне всего остального, что успел породить прогресс. Но иногда так хочется вернуться к истокам… Вернёмся.
Есть два качественных улучшения в управлении данными:
- Программист работает на уровень выше — на уровне конструктора, что позволяет делать на порядок меньше работы для задания структуры и выборки данных
- Администратор работает с предельно простой базой данных, в которой задачи кластеризации, зеркалирования, шардирования и подобные решаются также значительно проще
Сегодня реализованный прототип ядра (пусть далее оно называется так) будущей платформы не предоставляет Администратору никаких готовых средств для решения его задач. Учитывая простоту архитектуры, адаптация этих средств под конкретный проект сопоставима с написанием их с нуля. То же касается переноса между средами, контроля версий и прочего.
Рамки задач ядра: управление структурой, запросы и базовый интерфейс для изменения данных.
Я сделал минимальную обвязку и интерфейс, чтобы можно было пользоваться. Например, не используется механизм транзакций, доступный в СУБД, хотя реализовать его в ядре займет не более часа. Также не используются триггеры и constraints, просто потому что всё это до сих пор не понадобилось нам в прикладной разработке. Подобные вещи делаются поверх ядра (далеко за рамками патентной формулы) и, рискну заявить, делаются достаточно тривиально чтобы любой желающий мог сделать их под себя.
Теперь рассмотрим упомянутые нюансы.
Все данные физически хранятся в одной таблице из 5 полей: ID, родитель (ID), тип (тоже ID), порядок среди равных (число), значение (набор байтов). У неё есть 3 индекса: ID, тип-значение, родитель-тип. Вместо обращения к базе данных, которая найдет таблицу, в ней найдет поле, в котором найдет данные, ядро обращается к единственной таблице, в которой по индексу сразу находит данные нужного типа.
Подход, реализованный в ядре, позволят описать в этой таблице любую структуру данных: в редакторе типов создаем метамодель данных, а сами данные по этой модели доступны для просмотра и изменения в базовом интерфейсе. Объединение данных разных типов в таблицы использует статистику индексов, чтобы всё это работало с оптимальной скоростью — любая РСУБД примерно так же работает с данными на диске.
Это можно представить как устройство хранения, куда можно отправлять данные и запрашивать их, обращаясь к ядру. При этом снаружи, в интерфейсе, данные выглядят как набор обычных таблиц реляционной БД. Далее под таблицами я подразумеваю именно эти смоделированные ядром таблицы.
Целостность данных
Очевидно, что для обеспечения целостности данных ядро должно контролировать выполнение следующих условий:
- Уникальность ID (используется автоинкрементное значение);
- Недопустимость пустых значений Value;
- Недопустимость удаления записи, ID которой присутствует в поле Entity или Attribute любой другой записи.
В случае попытки нарушить третье из этих условий ядро сообщает пользователю о недопустимости операции и выдаёт информацию о связанных объектах.
Индексирование данных
Как видите, есть некоторая избыточность при индексировании, такова цена удобства.
Оптимизатор запросов сделает грязную работу за программиста — устранит неоптимальные сканирования таблиц данных, как если бы администратор проанализировал структуру и построил все нужные индексы вручную. Это рутинная задача, которой обычно занимаются по мере необходимости, тем не менее, если этим всерьез не заниматься, то база данных непродуктивно потребляет ресурсы сервера. Иногда очень непродуктивно.
Разумеется, никакой оптимизатор не заменит человека, особенно, знакомого с предметной областью, поэтому в любом приложении есть место для негрязной, творческой работы программиста.
Далее несколько примеров, когда может потребоваться подойти к решению с умом.
Есть правила, которые нужно помнить и соблюдать, чтобы производительность вашего приложения была оптимальна. Эти правила придумал не я, они относятся к общим приемам эффективной работы с большими объемами данных. Надо заметить, что эти же правила работают в любой реляционной базе данных. Некоторые из них очевидны для опытных разработчиков, однако, не все приходят в разработку сразу опытными.
Невозможность использования индекса
Избегайте использовать критичный к быстродействию фильтр по неиндексируемому значению поля:
- Индекс не применится в случае, когда вы используете некую функцию для преобразования поля, а затем уже к её результату применяете фильтр.
- Также следует учитывать, что индекс строится по значению полей, начиная с их первого символа, поэтому если вы используете в фильтре сравнение с подстрокой, начинающейся не с первого символа, то индекс применен не будет.
Не так часто встречается реальная необходимость применять указанные выше способы отбора данных в больших массивах записей, но если это действительно необходимо, то лучше будет дополнительно хранить заранее вычисленное значение нужной функции.
- Если в номерах банковских счетов вы анализируете код валюты по 6-8 символам, то вместо использования выражения SUBSTRING(Валюта, 6, 3) для отбора валют счетов следует вынести код валюты в отдельное поле в таблице счетов и делать выборку по его значению
- Когда вам требуется быстро найти человека по последним цифрам номера его телефона, то вместо поиска по маске %4567 стоит создать дополнительное поле с инвертированными номерами 89101234567 => 765432 (необязательно номер целиком) и затем также инвертировать условие поиска перед отправкой его в запрос: 7654%
Отсутствие индекса
Если вы планируете использовать для фильтрации данных некий атрибут, который может быть пустым, то его следует сделать обязательным и прописать туда по умолчанию значение, которое будет означать пустоту, например, слово NULL.

В данном случае выполненный заказ имеет заполненное время выполнения, и если не заполнять это поле аналогом пустого значения, то ядро не сохранит и не проиндексирует его. А значит, оптимизатору придется просмотреть все заказы для нахождения невыполненных, что при большом количестве заказов может занять время и является непродуктивной работой.
Если же мы ставим значение «NULL» (текстовое) по умолчанию, то оптимизатор быстро найдет все невыполненные заказы при помощи индекса.
Последовательность выборки связанных сущностей
При создании запроса старайтесь поместить в колонки отчета в первую очередь объекты или реквизиты, выборка которых по заданным условиям может значительно сократить массив связанных данных.
Обычно оптимизатор неплохо справляется со своей задачей, но бывают случаи, когда ему необходима помощь человека.
В выборке несколько таблиц с различным количеством записей, при этом заданы условия отбора, к которым не может быть применен индекс.
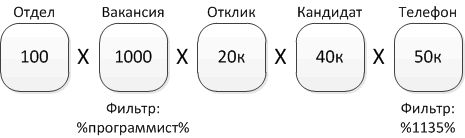
Оптимизатор может начать строить произведение таблиц, начиная с Отдела, прежде чем начнет применять фильтр к телефонам. Это может занять большое время.
Человеку же в этом случае очевидно, что даже без индекса запрос к одной таблице записей отработает быcтрее, вернув несколько записей и подтянув данные остальных таблиц. Поэтому человек поможет оптимизатору, переместив колонку Телефон в начало запроса, и тогда оптимизатор начнет выборку с телефонов.
В общем, это всё что нужно знать о новом ядре, чтобы начать с ним работать, если вам понадобится им овладеть.
Мои предыдущие статьи подвергались критике из-за отсутствия экосистемы вокруг технологического преимущества, данного ядром. Безусловно, это важно — предоставить администратору минимальный набор простых примеров, над чем мы с единомышленниками сейчас работаем, реализовывая самые разные задачи. Эти проекты служат только для подтверждения концепции, они пока не имеют ресурсов для создания Экосистемы для широкого промышленного применения. Тем не менее, там вы можете посмотреть наработки, чтобы мне не быть голословным.

