По вашему запросу найдено: реализация нечеткого поиска
8 мин
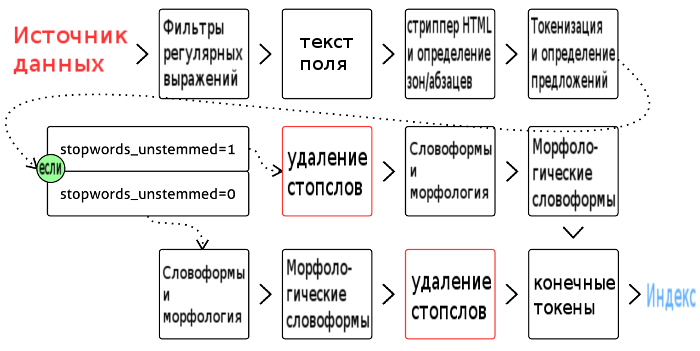
Все мы совершаем ошибки: в данном случае речь идет о поисковых запросах. Количество сайтов для продажи товаров и услуг растет наряду с потребностями пользователей, однако не всегда они могут найти то, что ищут – только потому, что неправильно вводят название необходимого товара. Решение данной проблемы достигается путем реализации нечеткого поиска, то есть использования алгоритма поиска наиболее близких значений с учетом возможных ошибок или опечаток пользователя. Область применения такого поиска достаточно широка – нам же удалось поработать над поиском для крупного интернет-магазина в фудритейл-сегменте.


 Мои читатели попросили сравнить проекты Manticore и Sphinx с точки зрения качества кода. Я могу сделать это только одним освоенным мною способом — проверить проекты с помощью статического анализатора PVS-Studio и посчитать плотность ошибок в коде. Итак, я проверил C и C++ код в этих проектах и, на мой взгляд, качество кода Manticore выше, чем качество кода Sphinx. Естественно, это очень узкий взгляд, и я не претендую на достоверность своего исследования. Однако меня попросили, и я сделал сравнение так, как умею.
Мои читатели попросили сравнить проекты Manticore и Sphinx с точки зрения качества кода. Я могу сделать это только одним освоенным мною способом — проверить проекты с помощью статического анализатора PVS-Studio и посчитать плотность ошибок в коде. Итак, я проверил C и C++ код в этих проектах и, на мой взгляд, качество кода Manticore выше, чем качество кода Sphinx. Естественно, это очень узкий взгляд, и я не претендую на достоверность своего исследования. Однако меня попросили, и я сделал сравнение так, как умею.