
Python: Работа с базой данных, часть 2/2: Используем ORM
14 мин
Туториал
| часть 1/2: Используем DB-API | часть 2/2: Используем ORM |
|---|
Статья ориентирована в первую очередь на начинающих, она не претендует на исчерпывающе глубокое изложение, а скорее дает краткую вводную в тему, объясняет самые востребованные подходы для старта и иллюстрирует это простыми примерами базовых операций.
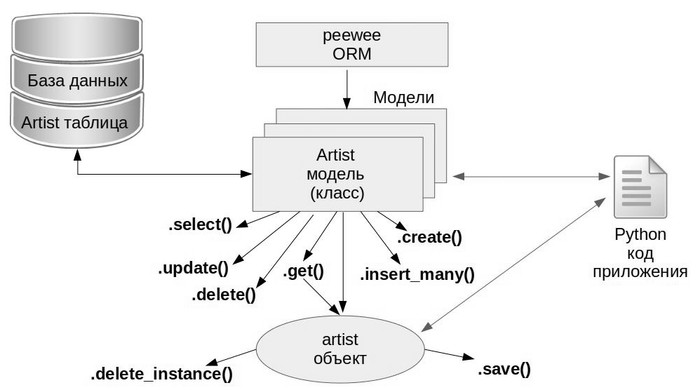
Требуемый уровень подготовки: базовое понимание SQL и Python (код статьи проверялся под Python 3.6). Желательно ознакомится с первой частью, так как к ней будут неоднократные отсылки и сравнения. В конце статьи есть весь код примеров под спойлером в едином файле и список ссылок для более углубленного изучения материала.














