Telegram в качестве хранилища данных для IT проектов
8 мин
Добрый день, сегодня я хотел бы поделится с Вами проблемами и их необычными решениями, которые встретились при написании небольших IT проектов. Сразу скажу, что статья для тех, кто хоть немного разбирается в разработке телеграмм ботов, баз данных, SQL и в языке программировании python.
Весь проект выложен на github, ссылка будет в конце статьи.

Изначально я хотел для себя написать простенького телеграмм бота счетчика калорий, который получает число от пользователя и возвращает сколько калорий осталось до нормы на день. То есть нужно хранить грубо говоря пару переменных для каждого пользователя.
Весь проект выложен на github, ссылка будет в конце статьи.
Основная проблема
Изначально я хотел для себя написать простенького телеграмм бота счетчика калорий, который получает число от пользователя и возвращает сколько калорий осталось до нормы на день. То есть нужно хранить грубо говоря пару переменных для каждого пользователя.

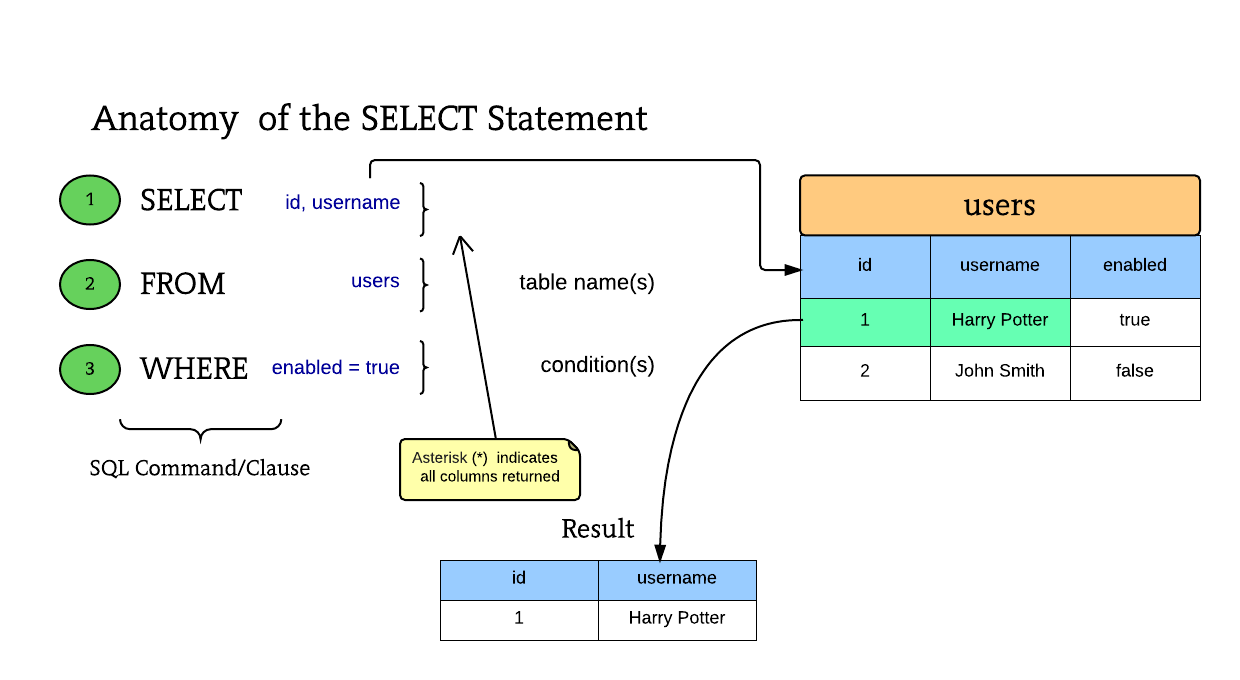
 Иногда медленные запросы можно исправить, немного изменив запрос. Один из таких примеров может быть проиллюстрирован, когда несколько значений сравниваются в предложении WHERE с помощью оператора OR или IN. Часто OR может вызывать сканирование индекса или таблицы, которая может не быть предпочтительным планом выполнения с точки зрения потребления ввода-вывода или общей скорости запросов.
Иногда медленные запросы можно исправить, немного изменив запрос. Один из таких примеров может быть проиллюстрирован, когда несколько значений сравниваются в предложении WHERE с помощью оператора OR или IN. Часто OR может вызывать сканирование индекса или таблицы, которая может не быть предпочтительным планом выполнения с точки зрения потребления ввода-вывода или общей скорости запросов.

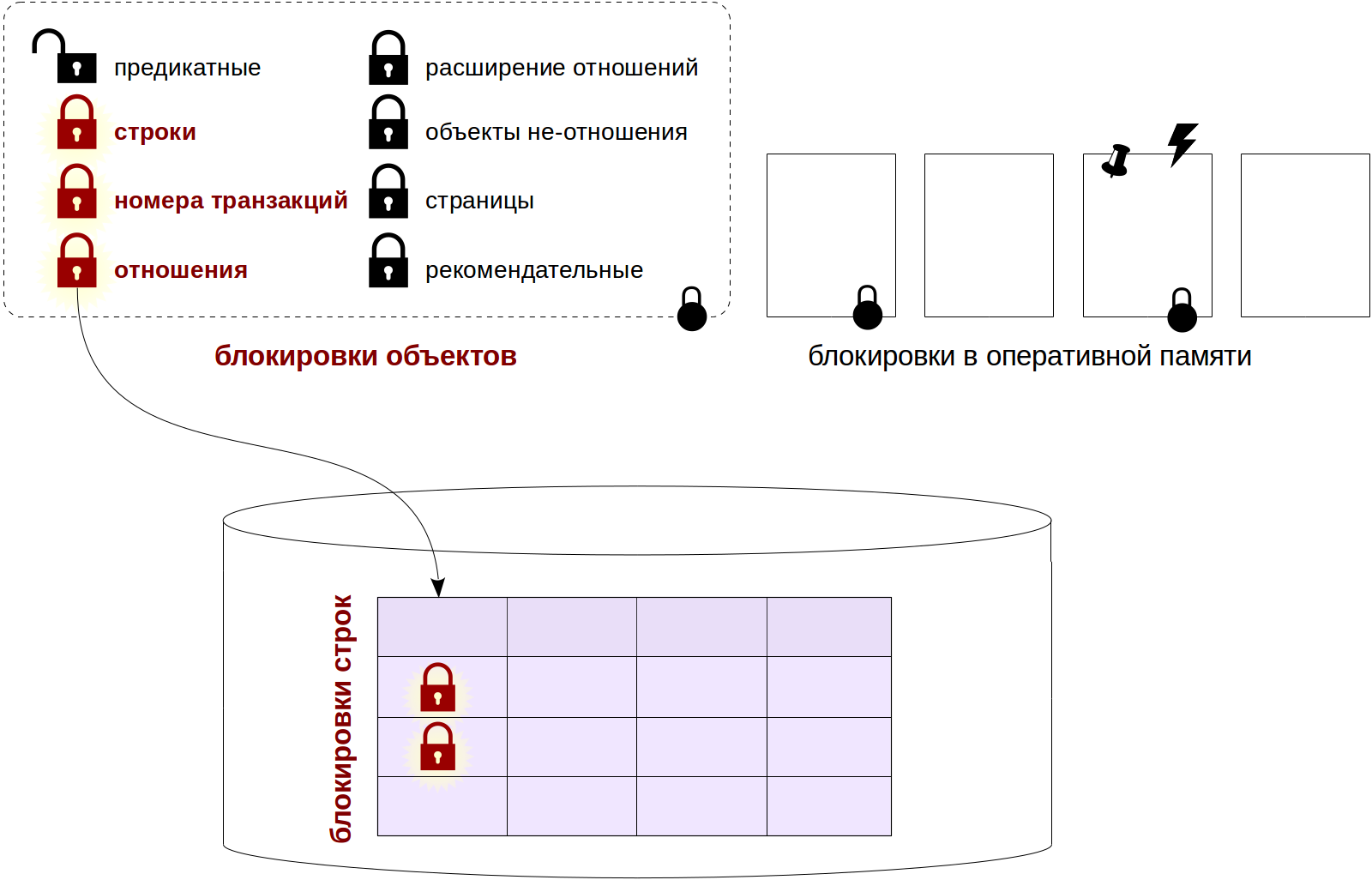




 Настройка производительности базы данных — разработчики обычно либо любят это, либо ненавидят. Я получаю удовольствие от этого и хочу поделиться некоторыми методами, которые я использовал в последнее время для настройки плохо выполняющихся запросов в PostgreSQL. Мои методы не является исчерпывающими, скорее учебником для тех, кто просто тащится от тюнинга.
Настройка производительности базы данных — разработчики обычно либо любят это, либо ненавидят. Я получаю удовольствие от этого и хочу поделиться некоторыми методами, которые я использовал в последнее время для настройки плохо выполняющихся запросов в PostgreSQL. Мои методы не является исчерпывающими, скорее учебником для тех, кто просто тащится от тюнинга.