Посвящается всем любителям анализировать логи.
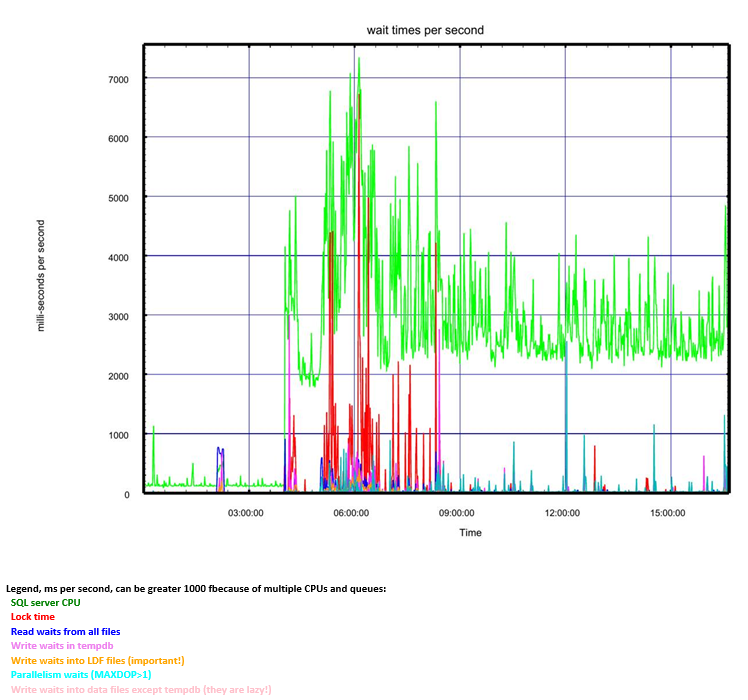
В логах работающих систем рано или поздно появляются тексты каких-то ошибок. Чем таких систем больше в обозримом пространстве, тем больше вероятность ошибку увидеть. Серверы PostgreSQL, которые
находятся под нашим мониторингом ежедневно генерируют от 300K до, в неудачный день,
12M записей об ошибках.
И такие ошибки — это не какой-то там
«о, ужас!», а вполне нормальное поведение сложных алгоритмов с высокой степенью конкурентности вроде тех, о которых я рассказывал в
статье про расчет себестоимости в СБИС — все эти deadlock,
could not obtain lock on row in relation …,
canceling statement due to lock timeout как следствие выставленных разработчиком statement/lock timeout.
Но есть ведь и другие виды ошибок — например,
you don't own a lock of type ..., которая возникает при
неправильном использовании рекомендательных блокировок и может очень быстро «закопать» ваш сервер, или, мало ли, кто-то периодически пытается «подобрать ключик» к нему, вызывая возникновение
password authentication failed for user …
[источник КДПВ]
Собственно, это все нас подводит к мысли, что если мы не хотим потом хвататься за голову, то возникающие в логах PostgreSQL ошибки недостаточно просто «считать поштучно» — их надо аккуратно классифицировать. Но для этого нам придется решить нетривиальную задачу
индексированного поиска регулярного выражения, наиболее подходящего для строки.

















 Иногда медленные запросы можно исправить, немного изменив запрос. Один из таких примеров может быть проиллюстрирован, когда несколько значений сравниваются в предложении WHERE с помощью оператора OR или IN. Часто OR может вызывать сканирование индекса или таблицы, которая может не быть предпочтительным планом выполнения с точки зрения потребления ввода-вывода или общей скорости запросов.
Иногда медленные запросы можно исправить, немного изменив запрос. Один из таких примеров может быть проиллюстрирован, когда несколько значений сравниваются в предложении WHERE с помощью оператора OR или IN. Часто OR может вызывать сканирование индекса или таблицы, которая может не быть предпочтительным планом выполнения с точки зрения потребления ввода-вывода или общей скорости запросов.