

Привет, меня зовут Антон Щербак, я разработчик корпоративного портала Selectel. Это внутренняя система, где можно узнать новости компании, поучаствовать в Selectel Game (это наша собственная геймификация рабочих достижений) и, конечно, найти необходимого коллегу или структуру.
Нас уже более 700, и иногда поиск человека превращается в выпуск ток-шоу «Жди меня». Поэтому у нас была задача сделать его более удобным и приводящим к нужному результату. Под катом рассказываю, к какому решению мы в итоге пришли и как реализовали.
Итак, наша цель — сделать поиск на портале более удобным и функциональным. Пользователи — сотрудники компании — хотели бы искать коллег по:
- ФИО,
- департаменту,
- телеграм-аккаунту,
- номеру телефона,
- логину,
- должности.
Причем частенько сотрудники ищут кого-то с неправильной раскладкой клавиатуры. Хотят написать Петров, а выходит Gtnhjd. Жутко бесит каждый раз понимать, что забыл изменить раскладку (поклонники Punto Switcher, к вам это, конечно же, не относится). Поэтому решили сделать поиск еще и по неправильно выставленной раскладке клавиатуры (RUS-EN).
О базе данных
В работе наша команда использует СУБД PostgreSQL, которую админят DevOps-инженеры Selectel. По сути, мы пользуемся облачными базами данных, которые доступны и нашим клиентам.
Структура базы данных, которая затрагивается в этой задаче, выглядит примерно так:
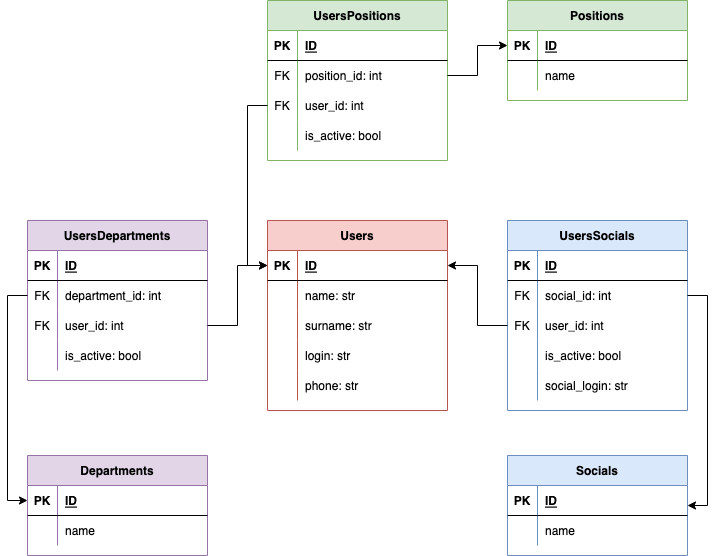
Что мы имеем? Данные расположены в разных табличках и связаны отношениями М2М. Всего в поиске задействовано 7 таблиц, и каждая имеет поле активных записей.
Количество записей в каждой из таблиц не более 2 000, и в ближайшее время это число не вырастет. Хоть Selectel и нанимает неплохое число новых сотрудников каждую неделю, но +1 000 людей в ближайшее ��ремя точно не наймет. А значит, изменений в числе запросов пока не предвидится.
Осталось разобраться, какой способ организации поиска выбрать, чтобы собрать все данные в простую строчку.
Краткий обзор подходов к поиску
Поиск с использованием ILIKE
Описание этого подхода довольно простое: «А давайте просто сделаем SELECT … FROM … WHERE column ILIKE ‘%pattern%’»
Для тех, кто мало с ним знаком, ILIKE — это оператор регистронезависимого сравнения по шаблону. Если паттерн совпал со значением в колонке, он возвращает TRUE.
Преимущества
- Подход очень удобен, когда данных не очень много.
- Не требует дополнительных настроек для работы.
- Такой вариант хорошо использовать, когда данные экранированы и не подвергаются всяким склонениям и прочим морфологическим изменениям.
- И в целом для организации простого поиска он подходит как нельзя лучше.
Недостатки
- Эффективность поиска падает при росте количества данных.
- Очень сложно как-то расширять и усложнять поиск (если например требуется учет морфологии, либо поиск с опечатками)
- Есть небольшие нюансы, связанные с сортировкой данных после поиска. О них я расскажу далее.
Полнотекстовый поиск на PostgreSQL
PostgreSQL обладает отличным встроенным полнотекстовым движком с хорошей документацией и шикарным API. Полнотекстовый поиск очень полезен в двух случаях:
- требуется искать по тексту с учетом морфологии слова. К примеру, по запросу «собака» поиск должен также найти слова «собачий», «собачка» и т.д.,
- требуется неточный поиск (fuzzy search), когда в тексте могут быть опечатки.
Для организации полнотекстового поиска в PostgreSQL нужно создать новый столбец векторного типа. В нем будут храниться векторы, созданные из лексем слов текста для каждой строки в таблице. Потом по этому вектору строится GIN-индекс, чтобы поиск работал быстро, и пишется триггер, который будет создавать поисковый вектор для каждой новой записи. Также можно использовать автогенерируемые колонки для PostgreSQL 12 версии и старше.
Преимущества
- Простая настройка, так как в наших проектах используется PostgreSQL и не требуется подключение дополнительного инструментария.
- Поддержка морфологии и поиска с опечатками. Это позволит расширять сложность поиска.
- Лучшая поддержка консистентности данных за счет хранения векторов в той же базе данных. Меньше головной боли.
- По производительности превосходит оператор LIKE.
Недостатки
- Производительность падает при аналитике больших документов.
- Масштабирование нагрузки поиска и его индексации приходится делать в том же сервисе.
Полнотекстовый поиск с использованием NoSQL поисковых движков по типу ElasticSearch
ElasticSearch — это мощный инструмент поиска документов. Решение делалось специально для поиска и особо эффективно, когда данных очень много.
Преимущества
- Недостатки PostgreSQL тут не актуальны.
- Хорошая устойчивость к изменениям в модели, так как решение отделено от основного хранилища данных.
Недостатки
- Нужно передавать содержимое базы данных внешним поисковым системам.
- Нужно следить за согласованностью данных. Могут быть ситуации, когда поиск находит уже удаленные или деактивированные в БД данные.
В целом, такой вариант подходит для поиска по огромным пластам данных и для того, чтобы получить готовое эффективное коробочное решение. Чем больше тексты, по которым будет производиться поиск, тем эффективнее будет ElasticSearch по сравнению с PostgreSQL.
Для организации поиска на корпоративном портале (не путать с основным сайтом selectel.ru) больше всего подходит написание запроса с использованием ILIKE. Выбор обусловлен тем, что:
- Данных мало.
- Данные экранированы, а значит, морфологический разбор нам не нужен.
- Хочется сохранить консистентность данных на высоком уровне.
- Должности, департаменты и логины в социальных сетях часто меняются.
- Этот вариант наименее трудозатратен и не требует дополнительных настроек.
- Лучшая производительность полнотекстового поиска PostgreSQL не раскрывается в полной мере на маленьком количестве данных.

Программная реализация
Первым делом напишем запрос для базы данных, который будет отдавать информацию по поисковому запросу.
Будем писать его, разбив на части и постепенно наращивая объем. Так будет понятно, какая из частей какую задачу решает.
Начнем с простого и выполним поиск по ФИО. Он должен выдавать нам результаты на поисковые запросы вида:
антон
щербак
антон щербак
щербак антон
щербак а
антон щ
Запрос:
select users.id, concat_ws(' ', users.surname, users.name) as display_name from users where concat_ws(' ', users.surname, users.name) ilike :pattern or concat_ws(' ', users.name, users.surname) ilike :pattern
Pattern будет равен ‘{string}%’ (например ‘антон%’), чтобы искать строки, которые начинаются на заданный шаблон. В этом случае наш поиск не будет отдавать нерелевантные данные, если пользователь ввел, например «наст», а получил пользователя «Конастов Виктор».
Но если это не критично, то, думаю, можно использовать шаблон ‘%{string}%’ для получения полного объема данных, который совпадает с шаблоном. Либо же для каких-то полей искать только те строки, где одинаковое именно начало шаблона, а уже в других полное вхождение.
Пример:
departments.name ilike ‘%корп%’ or users.surname ilike ‘корп%’
В примере выше поиск найдет например «Отдел разработки корпоративного портала», но не найдет пользователя в фамилией «Стокорпин».
Теперь добавим поиск по департаменту. Для этого нужно приклеить новую табличку:
select users.id, concat_ws(' ', users.surname, users.name) as display_name from users join users_departments on (users_departments.is_active = true and users_departments.user_id = users.id) join departments on (users_departments.department_id = departments.id) where ( (concat_ws(' ', users.surname, users.name) ilike :pattern or concat_ws(' ', users.name, users.surname) ilike :pattern) or departments.name ilike :pattern )
Поле is_active со значением true одно в департаментах и должностях, поэтому дубликатов при склейке не возникает и необходимость outerjoin также пропадает.
Добавим поиск по телеграм-аккаунту к нашему запросу:
select users.id, concat_ws(' ', users.surname, users.name) as display_name from users join users_departments on (users_departments.is_active = true and users_departments.user_id = users.id) join departments on (users_departments.department_id = departments.id) join users_socials on (users_socials.is_active = true and users_socials.user_id = users.id and users_socials.social_id=:telegram_social_id) where ( (concat_ws(' ', users.surname, users.name) ilike :pattern or concat_ws(' ', users.name, users.surname) ilike :pattern) or departments.name ilike :pattern or users_socials.social_login ilike :pattern )
И оставшиеся поля:
select users.id, concat_ws(' ', users.surname, users.name) as display_name from users join users_departments on (users_departments.is_active = true and users_departments.user_id = users.id) join departments on (users_departments.department_id = departments.id) join users_socials on (users_socials.is_active = true and users_socials.user_id = users.id and users_socials.social_id=:telegram_social_id) join users_positions on (users_positions.is_active = true and users.id=users_positions.user_id) join positions on users_positions.position_id = positions.id where ( (concat_ws(' ', users.surname, users.name) ilike :pattern or concat_ws(' ', users.name, users.surname) ilike :pattern) or departments.name_ru ilike :pattern or users_socials.social_login ilike :pattern or positions.name ilike :pattern or users.login ilike :pattern or users.phone ilike :pattern )
Теперь мы можем находить наших пользователей! Чтобы поиск был еще удобнее и полезнее, к нему нужно добавить сортировку данных. Обычно люди при вводе информации хотят сначала увидеть, к примеру, подходящие под шаблон фамилии, а потом уже ник в Telegram.
Мы выбрали следующий порядок приоритетов:
- Фамилия
- логин в Telegram
- телефон
- логин на портале
- имя
- департамент
- должность
Чтобы выполнить сортировку, есть один трюк, который мы разберем на примере совпадения фамилии.
Добавим к нашему запросу новый оператор:
order by (not users.surname ilike :pattern)
Как это работает? Если шаблон совпал с фамилией пользователя, будет true (или единица). Получится так, что у нас будет сортировка по числовому столбцу, состоящему из нулей и единиц. Чтобы совпадающие фамилии были вверху, нужно инвертировать значение (т.к. 0 < 1).
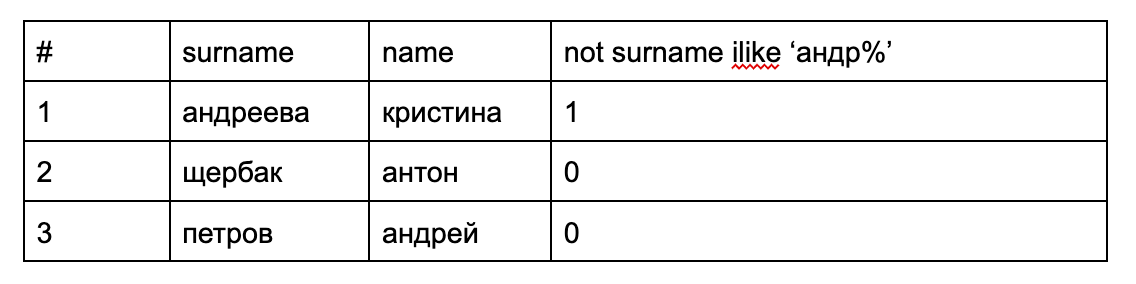
Теперь если мы добавим в сортировку еще и имя, то фамилия все равно будет в приоритете. Но и результаты поиска изменятся — будут в том виде, в котором нам нужно.
Дополним наш запрос сортировкой:
select users.id, concat_ws(' ', users.surname, users.name) as display_name from users join users_departments on (users_departments.is_active = true and users_departments.user_id = users.id) join departments on (users_departments.department_id = departments.id) join users_socials on (users_socials.is_active = true and users_socials.user_id = users.id and users_socials.social_id=:telegram_social_id) join users_positions on (users_positions.is_active = true and users.id=users_positions.user_id) join positions on users_positions.position_id = positions.id where ( (concat_ws(' ', users.surname, users.name) ilike :pattern or concat_ws(' ', users.name, users.surname) ilike :pattern) or departments.name_ru ilike :pattern or users_socials.social_login ilike :pattern or positions.name ilike :pattern or users.login ilike :pattern or users.phone ilike :pattern ) order by (not users.surname ilike :pattern), (not COALESCE(users_socials.social_login, '') ilike :pattern), (not users.phone ilike :pattern), (not users.login ilike :pattern), (not users.name ilike :pattern), (not departments.name_ru ilike :pattern), (not positions.name ilike :pattern), users.id
COALESCE нужен на случай, если логина у пользователя нет. Он выставляет в значение по умолчанию пустую строку, которая не влияет на результаты выборки.
Запрос готов! Осталось только решить задачку с неправильной раскладкой клавиатуры. Тут мы не придумали ничего лучше, чем просто написать маленькую функцию на питоне (наш бэк написан на Python), которая возвращает текст на другой раскладке.
def translate_text(s: str): eng_layout = "qwertyuiop[]asdfghjkl;'zxcvbnm,./`QWERTYUIOP{}ASDFGHJKL:\"ZXCVBNM<>?~" rus_layout = "йцукенгшщзхъфывапролджэячсмитьбю.ёЙЦУКЕНГШЩЗХЪФЫВАПРОЛДЖЭЯЧСМИТЬБЮ,Ё" if s[0] in eng_layout: table = str.maketrans(eng_layout, rus_layout) else: table = str.maketrans(rus_layout, eng_layout) return s.translate(table)
И в итоге просто искать по двум шаблонам.
Заключение
Итак, мы рассмотрели реализацию довольно простого поиска по небольшой базе. Безусловно, если ваша база данных сложнее и больше, вам нужна другая система поиска. Надеюсь, вам было полезно описание этой технической задачки. Пишите в комментариях, с каким поиском имели дело вы.
Возможно, эти тексты тоже вас заинтересуют:
→ Как мы решали задачу с «нарезкой» vCPU
→ Как мы сделали самописный длиномер для работы в дата-центрах
→ Обзор на разработчика: как айтишники попробовали себя в стендапе
