 Данная статья ориентирована в основном на тех, кто слышал об этой библиотеке, но не значет с чего начать.
Данная статья ориентирована в основном на тех, кто слышал об этой библиотеке, но не значет с чего начать.Intel Threading Building Blocks позволяет упростить создание и развертывание многопоточных приложений, предлагая разработчику ряд инструментов, позволяющих не задумываться о том на какой архиектуре и на какой платформе будет использоваться программа. Она берет на себя ответственность за работу с потоками.
Давайте рассмотрим использование Intel TBB на простом примере. Некоторое время назад я приводил пример создания многопоточного приложения с использованием OpenMP, которое брутфорсило пароль по его хэшу в MD5. Сделаем тоже самое, но с использованием TBB.
Оговорюсь сразу, это не инструкция по написанию утилиты для подбора пароля по его хэшу в MD5, помимо брутфорса, для подобного рода задач, существуют другие, более элегантные решения.
Для начала необходимо скачать библиотеку. На момент написания статьи последней стабильной версией библиотеки была версия 3.0. Распаковываем архив в любую папку на диске. В моем случае это была папка D:\Libs\ (полный путь к библиотеке, который получился у меня D:\Libs\tbb30_20100406oss\).
Данный пример создавался в MS VS 2008, за небольшими исключениями сказанное в статье справедливо и для других версия MS VS.
Создадим новый консольный проект. В свойствах проекта необходимо указать пути к папке Include, содержащей заголовочные файлы, и к папке Lib, содержащей библиотеки линковщика.
Открываем свойства проекта, на закладке C/C++ -> General в строке Additional Include Directories добавляем путь к папке Include, в моем случае это путь к D:\Libs\tbb30_20100406oss\include.

Далее переходим в раздел Linker -> General и добавляем путь к папке Lib в поле Additional Library Directories (D:\Libs\tbb30_20100406oss\lib\ia32\vc9).
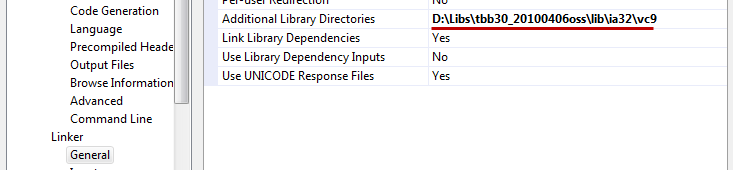
Обратите внимание, что в зависимости от целевой платформы и версии MS VS путь к папке lib может меняться, например, для 10-й студии это будет lib\ia32\vc10, для 64-х битной платформы lib\intel64\vc9.
Настроили, можно приступать к написанию программы. Начнем с добавления заголовочных файлов.
#include "tbb/task_scheduler_init.h"
#include "tbb/parallel_for.h"
#include "tbb/blocked_range.h"
using namespace tbb;
* This source code was highlighted with Source Code Highlighter.В функции main перед началом использования необходимо произвести инициализацию, создав экземпляр класса task_scheduler_init.
int _tmain(int argc, _TCHAR* argv[])
{
task_scheduler_init init;
return 0;
}
* This source code was highlighted with Source Code Highlighter.Концепция библиотеки такова, что разработчику необходимо создавать задачи, выполняющие определенные действия, например, над массивами данных, которые могут быть распаралелены. В нашем случае задача будет получать некоторый диапазон чисел, в пределах которого она будет вычислять хэш MD5 для каждого числа и сравнивать его с эталоном.
class MD5Calculate
{
public:
//////////////////////////////////////////////////////////////////////////
// Задача, которая будет параллелиться с помощью TBB
// входным параметром является некий диапазон,
// в нашем случае это "кусок" из заданного диапазона чисел
//////////////////////////////////////////////////////////////////////////
void operator() (const blocked_range<int>& range) const
{
string md5;
stringstream stream;
for(int i = range.begin(); i != range.end(); i++)
{
stream.clear();
stream << i;
GetMD5Hash(stream.str(), md5);
if(md5 == g_strCompareWith)
{
cout << "Password is: " << stream.str() << endl;
exit(0);
}
}
}
};
* This source code was highlighted with Source Code Highlighter.Вызов данного кода будет происходить с помощью функции parallel_for
int _tmain(int argc, _TCHAR* argv[])
{
task_scheduler_init init;
//////////////////////////////////////////////////////////////////////////
// В данном примере пароль это число, лежащее в пределах
// от 8000000 до 8999999
//////////////////////////////////////////////////////////////////////////
parallel_for(blocked_range<int>(8000000, 8999999), MD5Calculate());
return 0;
}
* This source code was highlighted with Source Code Highlighter.Как видите все просто, а что самое замечательное, TBB является кроссплатформенным решением, что позволит вам не задумаваться над тем как работать с потоками под той или иной платформой.
Еще одним плюсом является то, что библиотека сама позаботиться об оптимальном количестве потоков на целевой платформе. Количество потоков будет равняться количеству ядер процессора.
Библиотека достаточно удобна и функциональна, помимо функции для распараллеливания цикла parallel_for она так же содержит функции parallel_reduce, parallel_scan, parallel_do, контейнеры, объекты синхронизации и многое другое.
На официальном сайте библиотеки вы сможете найти архивы библиотеки под различные платформы включая Windows, Linux, Mac OS X, Solaris, а так же документацию и примеры использования.

